Real Time Big Data Analytics
We live almost every aspect of our lives in a real-time world. Think about our social communications; we update our friends online via social networks and micro-blogging, we text from our cell phones, or message from our laptops. But it’s not just our social lives; we shop online whenever we want, we search the web for immediate answers to our questions, we trade stocks online, we pay our bills, and do our banking. All online and all in real time.
 Real Time Analytics
Real Time AnalyticsReal time doesn’t just affect our personal lives. Enterprises and government agencies need real-time insights to be successful, whether they are investment firms that need fast access to market views and risk analysis, or retailers that need to adjust their online campaigns and recommendations to their customers. Even homeland security has come to increasingly rely on real-time monitoring. The amount of data that flows in these systems is huge. Twitter, for example, 500 million Tweets per day, which is nearly 3,000 Tweets per second, on average. At various peak moments through 2011, Twitter did as high as 8,000+ TPS, with at least one instance of over 25,000 tps. Facebook gets 100 billion hits per day with 3.2B Likes & Comments/day. Google get 2 billion searches a day. These numbers are growing as more and more users join the service.
This tutorial explains the challenges of a Real-time (RT) Analytics system using Twitter as an example, and show in details how these challenges can be met by using GigaSpaces XAP.
The Challenge
Twitter users aren’t just interested in reading tweets of the people they follow; they are also interested in finding new people and topics to follow based on popularity. This poses several challenges to the Twitter architecture due to the vast volume of tweets. In this example, we focus on the challenges relating to calculating the word count use case. The challenge here is straightforward:
- Tens of thousands of tweets need to be stored and parsed every second.
- Word counters need to be aggregated continuously. Since tweets are limited to 140 characters, we are dealing with hundreds of thousands of words per second.
- Finally, the system needs to scale linearly so the stream can grow as the business grows.
These challenges are not simple to deal with as there are knock-on effects from the volume and analysis of the data, as follows:
- Tens of thousands of tweets to tokenize every second, meaning hundreds of thousands of words to filter -> CPU bottleneck
- Tens/hundreds of thousands of counters to update -> Counters contention
- Tens/hundreds of thousands of counters to persist -> Database bottleneck
- Tens of thousands of tweets to store in the database every second -> Database bottleneck
Solution Architecture
In designing a solution, we need to consider the various challenges we must address.
The first challenge is providing unlimited scalability - therefore, we are talking about dynamically increasing resources to meet demand, and hence implementing a distributed solution using parallelized processing approach.
The second challenge is providing low latency - we can’t afford to use a distributed file system such as Hadoop HDFS, a relational database or a distributed disk-based structured data store such as NoSQL database. All of these use physical I/O that becomes a bottleneck when dealing with massive writes. Furthermore, we want the business logic collocated with the data on a single platform for faster processing, with minimal network hops and integration issues.
To overcome the latency challenge, we use an in-memory system of record. GigaSpaces XAP is built just for that. Its core component is in-memory data grid (IMDG, a.k.a. the Space) that partitions the data based on a specified attribute within the data object. The data grid uses a share nothing policy, and each primary node has consistent backup. In addition the grid keeps its SLA by self-healing crashed nodes, so it’s completely consistent and highly-available.
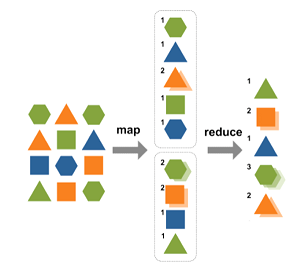
The third challenge is the efficient processing of the data in a distributed system. To achieve this, we use the Map / Reduce algorithm for distributed computing on large data sets on clusters of computers. In the Map step, we normalize the data so we can create local counters. In the Reduce step, we aggregate the entire set of interim results into a single set of results.
In our Twitter example, we need to build a flow that provides the Map / Reduce flow in real time. For this we use XAP’s Processing and Messaging features collocated with its corresponding data.
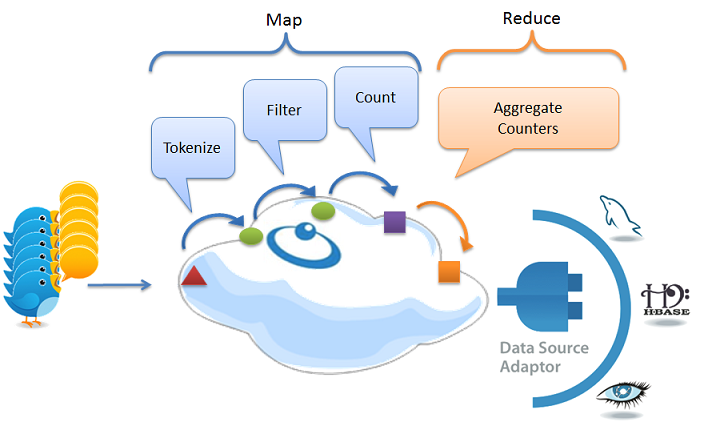
Our solution uses two main modules:
Feeder
The feeder write raw tweets into the Space (IMDG)– The tweets are routed to their relevant partition using their ID (assumed to be globally unique). This makes the solution scalable.
Processor
The processor module implements the Map/Reduce algorithm that processes tweets in the Space, resulting in real-time word counts. The tweets are then moved from the Space to the historical data store. The processor performs the following steps:
- Tokenizes tweets into maps of tokens and writes them to the Space (triggered by the writing of raw tweets to the Space).
- Filters unwanted words from the maps of tokens and writes the filtered maps to the Space (triggered by the writing of maps of tokens to the Space).
- Generates a token counter per word, distributing the counters across the grid partitions for scalability and performance (triggered by the writing of filtered maps of tokens to the Space).
The processor’s Reduce phase aggregates the local results into global word counters.
Implementing the Solution
We use a local file to store the historical data. XAP will process and persist the data in real-time using the following modules:
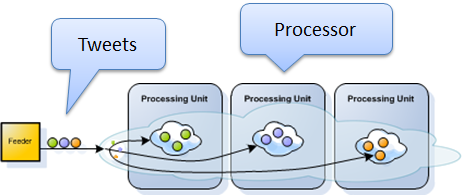
The processor module is a XAP processing unit that contains the Space and performs the real-time workflow of processing the incoming tweets. The processing of data objects is performed using event containers.
The feeder module is implemented as well as a processing unit. It is simulating tweets , converting them to Space Documents objects and writes them to the Space. This in turn invokes the relevant event processors on the processor module.
The common module including items that are shared between the feeder and the processor modules (e.g. common interfaces, shared data model, etc.).
Building the Application
The following are step-by-step instructions building the application:
Install XAP Follow these instructions to download and install the latest version of XAP.
Get the demo application code from github Get the demo application and place the files under an empty folder.
Install Maven and the GigaSpaces Maven plug-in The application uses Apache Maven. If you don’t have Apache Maven installed, please download and install it. Once installed:
- Set the
MVN_HOMEenvironment variable - Add
$MVN_HOME/binto your path. - Run the GigaSpaces Maven plug-in installer by calling the
<XapInstallationRoot>/tools/maven/installmavenrep.bat/shscript.
- Building the Application
Move to the application root folder. Edit the
pom.xmlfile and make sure the<gsVersion>include the correct XAP release you have installed. For example if you have XAP 12.2.1 installed you should have the following:
<properties>
<gsVersion>12.2.1</gsVersion>
</properties>
To Build the project type the following at your command (Windows) or shell (*nix):
mvn package
The Maven build will download the required dependencies, compile the source files, run the unit tests, and build the required jar files. In our example, the following processing unit jar files are built:
<project root>/feeder/target/rt-feeder-rt-analytics1.0.jar<project root>/processor/target/rt-processor-rt-analytics1.0.jar
Once the build is complete, a summary message similar to the following is displayed:
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] rt-analytics ...................................... SUCCESS [0.001s]
[INFO] rt-common ......................................... SUCCESS [2.196s]
[INFO] rt-processor ...................................... SUCCESS [11.301s]
[INFO] rt-feeder ......................................... SUCCESS [3.102s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 16.768s
[INFO] Finished at: Sun May 13 13:38:06 IDT 2012
[INFO] Final Memory: 14M/81M
[INFO] ------------------------------------------------------------------------
Running and Debugging the Application within an IDE
Since the application is a Maven project, you can load it using your Java IDE and thus automatically configure all module and classpath configurations.
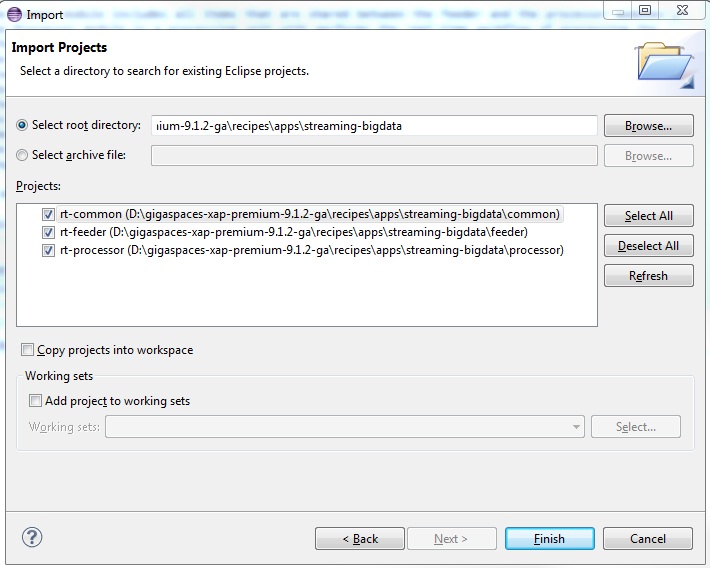
- With Eclipse, install the M2Eclipse plugin and click “File -> Import” , “Maven -> Existing Maven Projects” , select the
streaming-bigdatafolder and click theFinishbutton.

Once the project is loaded in your IDE, you can run the application, as follows:
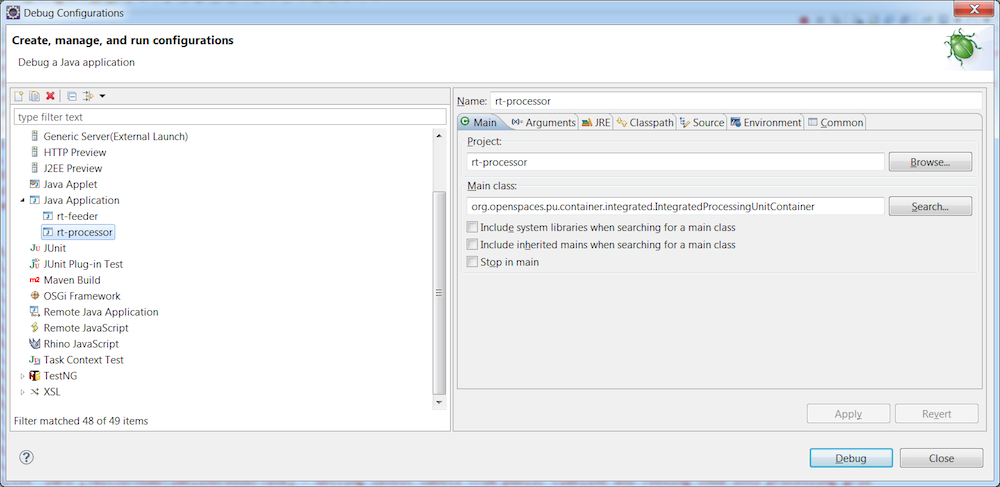
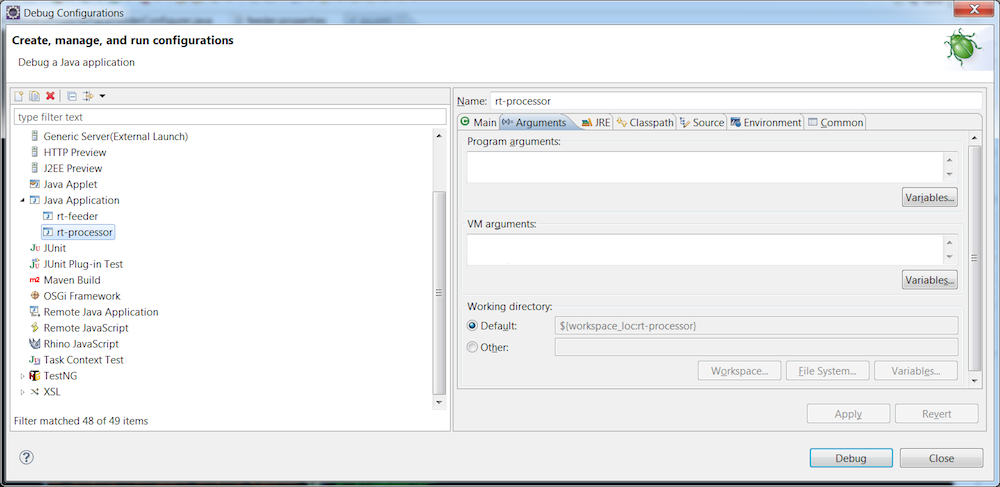
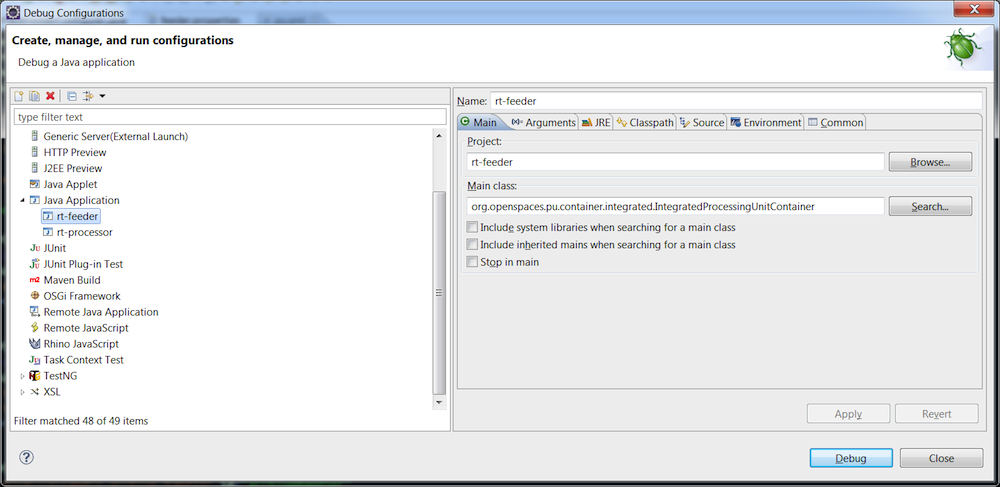
In Eclipse, create two run configurations. One for the feeder and one for the processor. For both, the main class must be [IntegratedProcessingUnitContainer]https://docs.gigaspaces.com/api/xap/14.2.0/java/org/openspaces/pu/container/integrated/IntegratedProcessingUnitContainer.html).
rt-processor project run configuration:
rt-feeder project run configuration:
For more information about the IntegratedProcessingUnitContainer class (runs the processing units within your IDE), see Running and Debugging Within Your IDE.
Make sure you have updated gslicense.xml located under the GigaSpaces XAP root folder with the license key provided as part of the email sent to you after downloading GigaSpaces XAP.
To run the application, run the processor configuration, and then the feeder configuration. An output similar to the following is displayed:
2013-02-22 13:09:38,524 INFO [org.openspaces.bigdata.processor.TokenFilter] - filtering tweet 305016632265297920
2013-02-22 13:09:38,526 INFO [org.openspaces.bigdata.processor.FileArchiveOperationHandler] - Writing 1 object(s) to File
2013-02-22 13:09:38,534 INFO [org.openspaces.bigdata.processor.TweetArchiveFilter] - Archived tweet 305016632265297920
2013-02-22 13:09:38,535 INFO [org.openspaces.bigdata.processor.LocalTokenCounter] - local counting of a bulk of 1 tweets
2013-02-22 13:09:38,537 INFO [org.openspaces.bigdata.processor.LocalTokenCounter] - writing 12 TokenCounters across the cluster
2013-02-22 13:09:38,558 INFO [org.openspaces.bigdata.processor.GlobalTokenCounter] - Increment local token arrive by 1
2013-02-22 13:09:38,606 INFO [org.openspaces.bigdata.processor.GlobalTokenCounter] - Increment local token Reine by 1
2013-02-22 13:09:38,622 INFO [org.openspaces.bigdata.processor.GlobalTokenCounter] - Increment local token pute by 1
2013-02-22 13:09:38,624 INFO [org.openspaces.bigdata.processor.GlobalTokenCounter] - Increment local token lyc?e by 2
2013-02-22 13:09:41,432 INFO [org.openspaces.bigdata.processor.TweetParser] - parsing tweet SpaceDocument .....
2013-02-22 13:09:41,440 INFO [org.openspaces.bigdata.processor.TokenFilter] - filtering tweet 305016630734381057
2013-02-22 13:09:41,441 INFO [org.openspaces.bigdata.processor.FileArchiveOperationHandler] - Writing 1 object(s) to File
2013-02-22 13:09:41,447 INFO [org.openspaces.bigdata.processor.LocalTokenCounter] - local counting of a bulk of 1 tweets
2013-02-22 13:09:41,448 INFO [org.openspaces.bigdata.processor.LocalTokenCounter] - writing 11 TokenCounters across the cluster
2013-02-22 13:09:41,454 INFO [org.openspaces.bigdata.processor.TweetArchiveFilter] - Archived tweet 305016630734381057
2013-02-22 13:09:41,463 INFO [org.openspaces.bigdata.processor.GlobalTokenCounter] - Increment local token Accounts by 1
2013-02-22 13:09:41,485 INFO [org.openspaces.bigdata.processor.GlobalTokenCounter] - Increment local token job by 1
2013-02-22 13:09:41,487 INFO [org.openspaces.bigdata.processor.GlobalTokenCounter] - Increment local token time by 1
Running the Application with XAP Runtime Environment
The following are step-by-step instructions for running the application in XAP:
- Download and install XAP.
- Edit
<XapInstallationRoot>/gslicense.xml>and place the license key file provided with the email sent to you after downloading GigaSpaces XAP as the<licensekey>value. - Make sure you have the
feeerandprocessorPUs built. - Start a Grid Service Agent by running the
gs-agent.sh/batscript.
nohup ./gs-agent.sh >/dev/null 2>&1
start /min gs-agent.bat
- Deploy the processor
./gs.sh deploy ../processor/target/rt-processor-rt-analytics1.0.jar
gs deploy ..\processor\target\rt-processor-rt-analytics1.0.jar
You should see the following output:
Deploying [rt-processor-rt-analytics1.0.jar] with name [rt-processor-rt-analytics1.0] under groups [xap-12.2.1] and locators []
Uploading [rt-processor-rt-analytics1.0] to [http://127.0.0.1:61765/]
Waiting indefinitely for [4] processing unit instances to be deployed...
[rt-processor-rt-analytics1.0] [1] deployed successfully on [127.0.0.1]
[rt-processor-rt-analytics1.0] [1] deployed successfully on [127.0.0.1]
[rt-processor-rt-analytics1.0] [2] deployed successfully on [127.0.0.1]
[rt-processor-rt-analytics1.0] [2] deployed successfully on [127.0.0.1]
Finished deploying [4] processing unit instances
- Deploy the feeder:
./gs.sh deploy ../feeder/taret/rt-feeder-rt-analytics1.0
gs deploy ..\feeder\target\rt-feeder-rt-analytics1.0
You will need XAP PREMIUM edition license key to deploy the processor in a clustered configuration
You should see the following output:
Deploying [rt-feeder-rt-analytics1.0.jar] with name [rt-feeder-rt-analytics1.0] under groups [xap-12.2.1] and locators []
Uploading [rt-feeder-rt-analytics1.0] to [http://127.0.0.1:61765/]
SLA Not Found in PU. Using Default SLA.
Waiting indefinitely for [1] processing unit instances to be deployed...
[rt-feeder-rt-analytics1.0] [1] deployed successfully on [127.0.0.1]
Finished deploying [1] processing unit instances
Once the application is running, you can use the XAP UI tools to view your application , access the data and the counters and manage the application:
- For the Web Based UI run gs-webui.bat/sh and point your browser to
localhost:8099 - For the Rich Based UI run gs-ui.bat/sh
To learn about additional options for deploying your XAP processing units, please see Deploying onto the Service Grid
Viewing Most Popular Words
To view the most popular words , start the GS-UI using the gs-ui.bat/sh , click the Query icon as demonstrated below and execute the following SQL Query by clicking the  button:
button:
select uid,* from org.openspaces.bigdata.common.counters.GlobalCounter order by counter DESC
You should see the top most popular words on twitter ordered by their popularity:
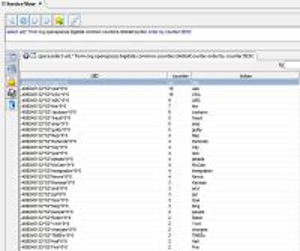
You can re-execute the query just by clicking the  button again. This will give you real-time view on the most popular words on Twitter.
button again. This will give you real-time view on the most popular words on Twitter.