Custom Aggregators
| Author | XAP Version | Last Updated | Reference | Download |
|---|---|---|---|---|
| Shay Hassidim | 10.1 | July 2015 |
Aggregators provided by the core XAP platform are extensible, allowing developers to modify existing functionality as well as add new features. This flexibility allows the framework to grow with changing requirements and new technologies. Creating a new aggregator or extending an existing one is a small level of effort for the developer. This document will describe different patterns to write custom aggregators and some common use cases.
SpaceEntriesAggregator
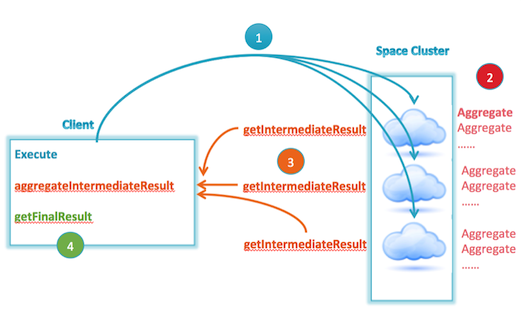
The SpaceEntriesAggregator is an abstract class that serves as the base class for all aggregators, including the ones provided by the core platform. Extending this class will provide several methods to allow the user to easily implement a custom aggregator. The methods are as follows:
aggregate
The aggregate method is executed for each space entity matching the SQLQuery in a space partition. The function receives a SpaceEntriesAggregatorContext, which is a wrapper that allows the user to access members of the user entity. The members of each space entity can be accessed by the getPathValue method of SpaceEntriesAggregatorContext.
Long departmentId = (Long) context.getPathValue(“departmentId”);
getIntermediateResult
Executed after all aggregate method calls have completed, this method represents the aggregation result of one partition. The returned value will be passed back to the client where it will trigger the aggregateIntermediateResult method.
aggregateIntermediateResult
Assembles the responses from each partition on the client side to represent a response from the entire cluster. The input to this method is the returned value of the getIntermediateResult method.
getFinalResult (optional)
Once all partitions have returned their results, the proxy invokes the getFinalResult method to retrieve the final aggregation result. Its default implementation will invoke the getIntermediateResult method, which yields the correct value in most aggregation implementations. Implement getFinalResult when there needs to be additional logic performed on the entire aggregatedResult.
getDefaultAlias
An aggregation result can contain the results from multiple aggregations. An alias provides a way to distinguish one aggregation result from another.
Simple Aggregator
In the following example we will implement a custom aggregator to retrieve a result set of employee-id and salary. In the aggregate method, we place the employee-id and salary-id in a key value map. On the client side, each partition result is assembled in the aggregateIntermediateResult method. After the results are assembled the getFinalResult method is called. In this case we implemented getFinalResult to be explicit, but by default getFinalResult behavior will invoke getIntermediateResult.
package com.gigaspaces.se.aggregator.example.salaryaggregator;
import java.util.HashMap;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregator;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregatorContext;
public class SalaryAggregator extends SpaceEntriesAggregator<HashMap<String, Integer>>{
private static final long serialVersionUID = -7641865740945835568L;
private transient HashMap<String, Integer> map;
@Override
public void aggregate(SpaceEntriesAggregatorContext context) {
String employeeId = (String)context.getPathValue("id");
Integer salary = (Integer)context.getPathValue("salary");
if(map == null)
map = new HashMap<String, Integer>();
map.put(employeeId, salary);
}
@Override
public HashMap<String, Integer> getIntermediateResult() {
return map;
}
@Override
public void aggregateIntermediateResult(
HashMap<String, Integer> partitionResult) {
if(partitionResult != null){
if(map == null){
map = partitionResult;
}else{
map.putAll(partitionResult);
}
}
}
@Override
public String getDefaultAlias() {
return "salaryAggrgetor()";
}
@Override
public Object getFinalResult() {
return getIntermediateResult();
}
}
SalaryAggregator salaryAggregator = new SalaryAggregator();
AggregationSet aggregationSet = new AggregationSet();
aggregationSet.add(salaryAggregator);
SQLQuery<Employee> query = new SQLQuery<Employee>(Employee.class, "salary > 50000");
AggregationResult aggregationResult = gigaSpace.aggregate(query, aggregationSet);
Map<String, Integer> employeeSalaryMap = (Map<String, Integer>)aggregationResult.get("salaryAggrgetor()");
Extending an Existing Aggregator
In the following example we extend the GroupByAggregator to add custom filtering based on a Mathematical operation. For each value found, we compare the absolute value of ‘expenses ‘ to the value of ‘limit’ provided in the constructor. If expenses fall between -100 and 100 the aggregator will include the space entry in the aggregation.
package com.gigaspaces.se.aggregator.example.salaryaggregator;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
import com.gigaspaces.query.aggregators.GroupByAggregator;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregatorContext;
public class GroupByAggregatorWithFilter extends GroupByAggregator{
private Double limit;
public GroupByAggregatorWithFilter(){
super();
}
public GroupByAggregatorWithFilter(Double limit){
super();
this.limit = limit;
}
@Override
public void aggregate(SpaceEntriesAggregatorContext context) {
Double expenses = (Double) context.getPathValue("expenses");
if(Math.abs(expenses) < this.limit) {
super.aggregate(context);
}
}
/***
* Override Parent Serialization methods
* and serialize and new members
*/
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
super.readExternal(in);
limit = (Double)in.readObject();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
super.writeExternal(out);
out.writeObject(limit);
}
}
SQLQuery<Employee> query = new SQLQuery<Employee>(Employee.class, "salary > 50000");
GroupByAggregator groupByAggregator = new GroupByAggregatorWithFilter(100.0)
.selectAverage("salary")
.groupBy("departmentId");
AggregationSet aggregationSet = new AggregationSet();
aggregationSet.add(groupByAggregator);
AggregationResult result = gigaSpace.aggregate(query, aggregationSet);
GroupByResult groupByResult = (GroupByResult)result.get(0);
SELECT AVG(salary)
FROM employee
WHERE ABS(expenses) < 100 AND salary > 50000
GROUP BY departmentId
Chaining Aggregators
Chaining aggregators allows users to reuse the same filtering logic for different aggregators. Just as in our example where we extend the GroupByAggregator, we check the absolute value of a field before aggregating the value. This time we accept any type of aggregator.
package com.gigaspaces.se.aggregator.example.salaryaggregator;
import java.io.Serializable;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregator;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregatorContext;
public class ChainedAggregatorWithFilter<T extends Serializable> extends SpaceEntriesAggregator<T>{
private static final long serialVersionUID = 3892805657010192758L;
private SpaceEntriesAggregator<T> aggregator;
private Double limit;
public ChainedAggregatorWithFilter(SpaceEntriesAggregator<T> aggregator, Double limit){
super();
this.aggregator = aggregator;
this.limit = limit;
}
@Override
public void aggregate(SpaceEntriesAggregatorContext context) {
Double expenses = (Double) context.getPathValue("expenses");
if(Math.abs(expenses) < limit){
aggregator.aggregate(context);
}
}
@Override
public void aggregateIntermediateResult(T partitionResult) {
aggregator.aggregateIntermediateResult(partitionResult);
}
@Override
public String getDefaultAlias() {
return "filterByExpenses";
}
@Override
public T getIntermediateResult() {
return aggregator.getIntermediateResult();
}
@Override
public Object getFinalResult() {
return aggregator.getFinalResult();
}
}
SQLQuery<Employee> query = new SQLQuery<Employee>(Employee.class, "salary > 50000");
GroupByAggregator groupByAggregator = new GroupByAggregator()
.selectAverage("salary")
.groupBy("departmentId");
AggregationSet aggregationSet = new AggregationSet();
aggregationSet.add(new ChainedAggregatorWithFilter<GroupByResult>(groupByAggregator, 100.0));
AggregationResult result = gigaSpace.aggregate(query, aggregationSet);
GroupByResult groupByResult = (GroupByResult)result.get(0);
SELECT AVG(salary)
FROM employee
WHERE ABS(expenses) < 100 AND salary > 50000
GROUP BY departmentId
Common Use Cases
Comparing Two Properties From the Same Object
Sometimes there is a need to compare two members of the same object. Currently (XAP 10.2) SQLQuery does not support this type of comparison. To achieve this a user may create a custom aggregator to perform the comparison before performing the aggregation. The following example will emulate a read multiple call. It has a special filter that compares two fields from the same object.
package com.gigaspaces.se.aggregator.example.salaryaggregator;
import java.util.HashMap;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregator;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregatorContext;
public class SalaryAggregatorWithFilter extends SpaceEntriesAggregator<HashMap<String, Integer>>{
private static final long serialVersionUID = -1639750562385907859L;
private transient HashMap<String, Integer> map;
public SalaryAggregatorWithFilter() {
super();
}
@Override
public void aggregate(SpaceEntriesAggregatorContext context) {
String employeeId = (String)context.getPathValue("id");
String ssn = (String)context.getPathValue("ssn");
Integer salary = (Integer)context.getPathValue("salary");
if(employeeId.equals(ssn)){
if(map == null)
map = new HashMap<String, Integer>();
map.put(employeeId, salary);
}
}
@Override
public HashMap<String, Integer> getIntermediateResult() {
return map;
}
@Override
public void aggregateIntermediateResult(
HashMap<String, Integer> partitionResult) {
if(partitionResult != null){
if(map == null){
map = partitionResult;
}else{
map.putAll(partitionResult);
}
}
}
@Override
public String getDefaultAlias() {
return "salaryAggrgetorWithFilter()";
}
@Override
public Object getFinalResult() {
return getIntermediateResult();
}
}
SalaryAggregatorWithFilter salaryAggregator = new SalaryAggregatorWithFilter();
AggregationSet aggregationSet = new AggregationSet();
aggregationSet.add(salaryAggregator);
SQLQuery<Employee> query = new SQLQuery<Employee>(Employee.class, "salary > 50000");
AggregationResult aggregationResult = gigaSpace.aggregate(query, aggregationSet);
Map<String, Integer> employeeSalaryMap = (Map<String, Integer>)aggregationResult.get("salaryAggrgetorWithFilter()");
SELECT employeeId, salary
FROM employee
WHERE employeeId = ssn AND salary > 50000
SQL IN Query vs. Custom Aggregator Query
SQL IN Queries – Custom Aggregator Example
This example has a Space with a million Employee objects. The Employee objects are associated with 50,000 different Departments – in average 20 Employees per Department. An Employee object has an id field, a salary field (extended indexed) and a departmentId field (indexed).
Out of the million Employees within the space we had 750,000 with a salary = 6000 and 250,000 Employees with salary = 1000.
The query executed using a classic SQL IN statement:
select id from Employee where salary > 5000 AND departmentId IN (?)
Where the dynamic parameter had a different size of IDs list each time. The normal way of implementing such a query is to use the SQLQuery in the following manner:
Collection<Integer> departmentList = new HashSet<Integer>();
departmentList.add(…);
….
SQLQuery<Employee> query = new SQLQuery<Employee>(Employee.class, "salary > 5000 AND departmentId IN (?)");
query.setProjections("id");
query.setParameter(1, departmentList);
Employee result[] = gigaSpace.readMultiple(query);
where the departmentList includes the list of IDs we want to match against.
The other option is to use a Custom Aggregator as described below.
Here are the results comparing regular query using IN with the custom aggregator:
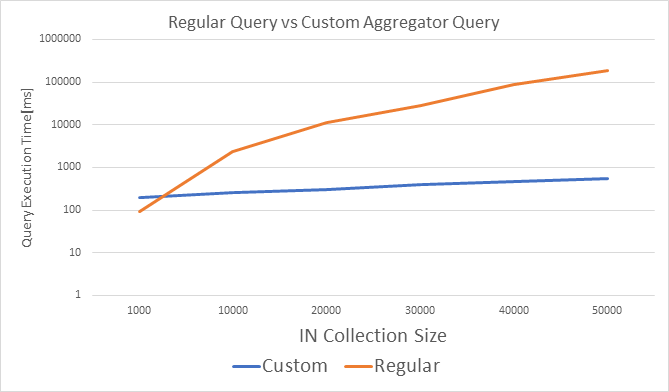
As we can see - the time it takes to execute the query using the regular approach grows exponentially as we increase the departmentList size, where with the custom aggregator we are getting a minor increase with the query execution time.
The reason for this difference is the way the Custom Aggregator is implemented. With the Custom Aggregator, the Space iterates the candidate set (in our case Employee objects that matches salary > 5000) and calls the CustomINAggregator.Aggregate() for each where the given departmentList matched against the Employee departmentID field value. The ones that can be found within the departmentList are added to the result set that eventually is sent back to the client using getIntermediateResult and finally aggregated via the aggregateIntermediateResult that is called for each partition. Iterating the candidate set is a very fast process that does not generates many new objects on the server. Getting the final result (HashSet) back into the client size also have very minimal garbage creation footprint.
The regular approach, where the SQLQuery is getting the departmentList to match against , performs a separate query for each element within the departmentList collections. All results are eventually aggregated into a final one returned back to the client.
This is a time consuming process. In addition – the aEmployee objects are materialize on the client side, which may consume memory and invoke garbage collection activity.
With the Custom Aggregator approach, Employee objects are not created anywhere throughout the process (these are accessed by reference during the scan activity), so no garbage is created.
This generates a very stable system in case such a query is executed continuously by many threads.
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
import java.util.Collection;
import java.util.HashSet;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregator;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregatorContext;
public class CustomINAggregator extends SpaceEntriesAggregator<HashSet<String>> implements Externalizable {
private Collection<Integer> collection;
private HashSet<String> result = new HashSet<String>();
public CustomINAggregator() {
super();
}
public String getDefaultAlias() {
return "IN";
}
public HashSet<String> getIntermediateResult() {
return result;
}
public CustomINAggregator(Collection<Integer> collection) {
super();
this.collection = collection;
}
public void aggregateIntermediateResult(HashSet<String> partitionResult) {
result.addAll(partitionResult);
}
@Override
public void aggregate(SpaceEntriesAggregatorContext context) {
Integer departmentId = (Integer) context.getPathValue("departmentId");
if (collection.contains(departmentId)) {
result.add((String) context.getPathValue("id"));
}
}
public void readExternal(ObjectInput in) {
try {
collection = (Collection<Integer>) in.readObject();
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
}
public void writeExternal(ObjectOutput out) {
try {
out.writeObject(collection);
} catch (IOException e) {
e.printStackTrace();
}
}
}
import com.gigaspaces.annotation.pojo.SpaceId;
import com.gigaspaces.annotation.pojo.SpaceIndex;
import com.gigaspaces.metadata.index.SpaceIndexType;
public class Employee {
String id;
Integer salary;
Integer departmentId;
@SpaceId
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
@SpaceIndex(type = SpaceIndexType.EXTENDED)
public Integer getSalary() {
return salary;
}
public void setSalary(Integer salary) {
this.salary = salary;
}
@SpaceIndex
public Integer getDepartmentId() {
return departmentId;
}
public void setDepartmentId(Integer departmentId) {
this.departmentId = departmentId;
}
}
SQLQuery<Employee> query = new SQLQuery<Employee>(Employee.class, "salary > 5000");
CustomINAggregator customINAggregator = new CustomINAggregator(departmentList);
AggregationSet aggregationSet = new AggregationSet();
aggregationSet.add(customINAggregator);
AggregationResult result = gigaSpace.aggregate(query, aggregationSet);
HashSet<String> aggreResult = (HashSet<String>) result.get(0);
Replacing Large Collection for IN Operator
Consider replacing the IN/NOT IN operator in SQLQuery with a custom aggregator when using a large collection as a parameter. The SQLQuery supports the IN and NOT IN operator, but when the collection is extensive, it may be beneficial to pass the collection into a custom aggregator as shown below.
package com.gigaspaces.se.aggregator.example.salaryaggregator;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
import java.util.Collection;
import com.gigaspaces.query.aggregators.GroupByAggregator;
import com.gigaspaces.query.aggregators.SpaceEntriesAggregatorContext;
public class GroupByAggregatorWithContainsFiler<T> extends GroupByAggregator{
private Collection<T> collection;
private String inFieldName;
public GroupByAggregatorWithContainsFiler(String inFieldName, Collection<T> collection){
super();
this.inFieldName = inFieldName;
this.collection = collection;
}
public GroupByAggregatorWithContainsFiler(){
super();
}
@Override
public void aggregate(SpaceEntriesAggregatorContext context) {
T field = (T) context.getPathValue(inFieldName);
if(collection.contains(field)) {
super.aggregate(context);
}
}
/***
* Override Parent Serialization methods
* and serialize and new members
*/
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
super.readExternal(in);
collection = (Collection<T>)in.readObject();
inFieldName = (String)in.readObject();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
super.writeExternal(out);
out.writeObject(collection);
out.writeObject(inFieldName);
}
}
List<Integer> departmentList = new ArrayList<Integer>();
departmentList.add(1);
departmentList.add(2);
//Large List....
SQLQuery<Employee> query = new SQLQuery<Employee>(Employee.class, "salary > 50000");
GroupByAggregator groupByAggregator = new GroupByAggregatorWithContainsFiler("departmentId", departmentList)
.selectAverage("salary")
.groupBy("departmentId");
AggregationSet aggregationSet = new AggregationSet();
aggregationSet.add(groupByAggregator);
AggregationResult result = gigaSpace.aggregate(query, aggregationSet);
GroupByResult groupByResult = (GroupByResult)result.get(0);
SELECT AVG(salary), departmentId FROM
Employee
WHERE salary > 50000 AND departmentId IN (1,25,33,…. 10,000)