XAP Integration with Storm
| Author | XAP Version | Last Updated | Reference | Download |
|---|---|---|---|---|
| Oleksiy Dyagilev | 10.0 | August 2014 | Storm | Github link |
Introduction
Real-time processing is becoming very popular, and Storm is a popular open source framework and runtime used by Twitter for processing real-time data streams. Storm addresses the complexity of running real time streams through a compute cluster by providing an elegant set of abstractions that make it easier to reason about your problem domain by letting you focus on data flows rather than on implementation details.
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
This pattern integrates XAP with Storm. XAP is used as stream data source and fast reliable persistent storage, whereas Storm is in charge of data processing. We support both pure Storm and Trident framework.
As part of this integration we provide classic Word Counter and Twitter Reach implementations on top of XAP and Trident.
Also, we demonstrate how to build highly available, scalable equivalent of Realtime Google Analytics application with XAP and Storm. Application can be deployed to cloud with one click using Cloudify.
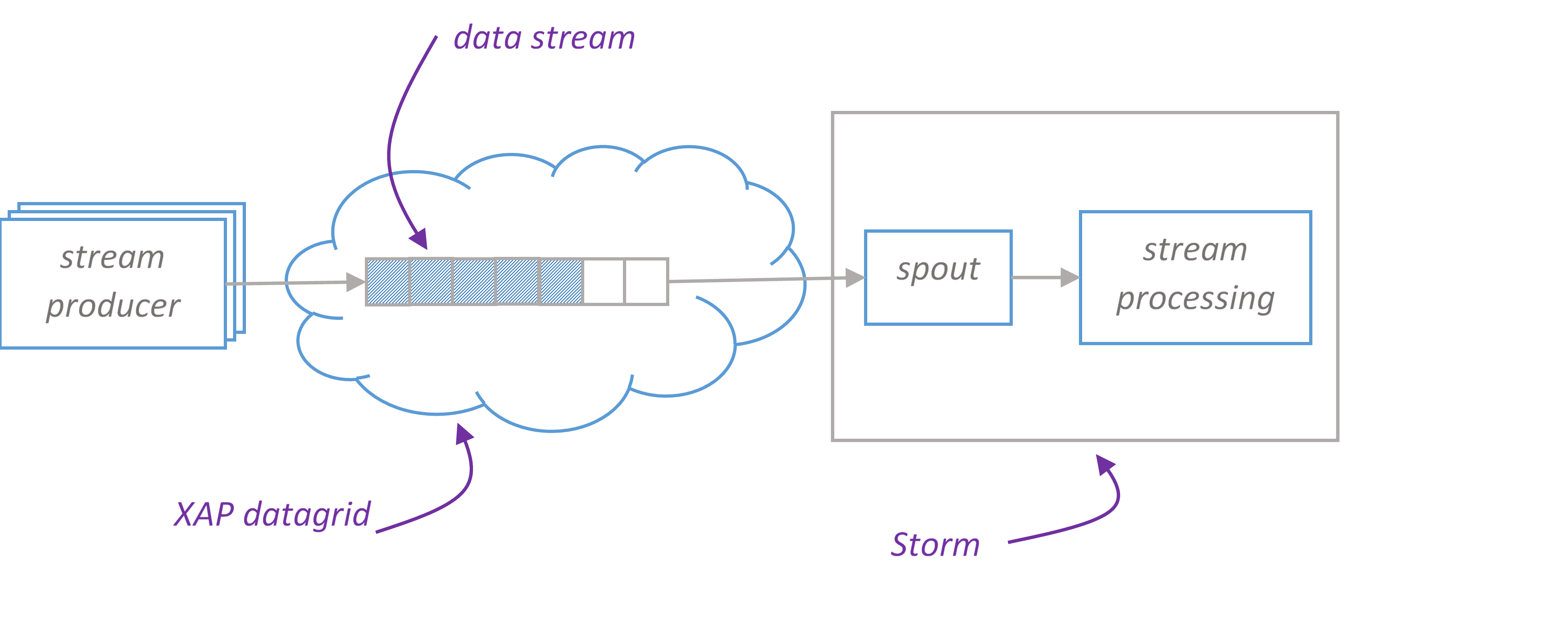
 XAP Storm Integration
XAP Storm IntegrationStorm in a Nutshell
Storm is a real time, open source data streaming framework that functions entirely in memory. It constructs a processing graph that feeds data from an input source through processing nodes. The processing graph is called a “topology”. The input data sources are called “spouts”, and the processing nodes are called “bolts”. The data model consists of tuples. Tuples flow from Spouts to the bolts, which execute user code. Besides simply being locations where data is transformed or accumulated, bolts can also join streams and branch streams.
Storm is designed to be run on several machines to provide parallelism. Storm topologies are deployed in a manner somewhat similar to a webapp or a XAP processing unit; a jar file is presented to a deployer which distributes it around the cluster where it is loaded and executed. A topology runs until it is terminated.
Beside Storm, there is a Trident - a high-level abstraction for doing realtime computing on top of Storm. Trident adds primitives like groupBy, filter, merge, aggregation to simplify common computation routines. Trident has consistent, exactly-once semantics, so it is easy to reason about Trident topologies.
Capability to guarantee exactly-once semantics comes with additional cost. To guarantee that, incremental processing should be done on top of persistence data source. Trident has to ensure that all updates are idempotent. Usually that leads to lower throughput and higher latency than similar topology with pure Storm.
Spouts
Basically, Spouts provide the source of tuples for Storm processing. For spouts to be maximally performant and reliable, they need to provide tuples in batches, and be able to replay failed batches when necessary. Of course, in order to have batches, you need storage, and to be able to replay batches, you need reliable storage. XAP is about the highest performing, reliable source of data out there, so a spout that serves tuples from XAP is a natural combination.
Depending on domain model and level of guarantees you want to provide, you choose either pure Storm or Trident. We provide Spout implementations for both - XAPSimpleSpout and XAPTranscationalTridentSpout respectively.
Storm Spout
XAPSimpleSpout is a spout implementation for pure Storm that reads data in batches from XAP. On XAP side we introduce conception of stream. Please find SimpleStream - a stream implementation that supports writing data in single and batch modes and reading in batch mode. SimpleStream leverages XAP’s FIFO(First In, First Out) capabilities.
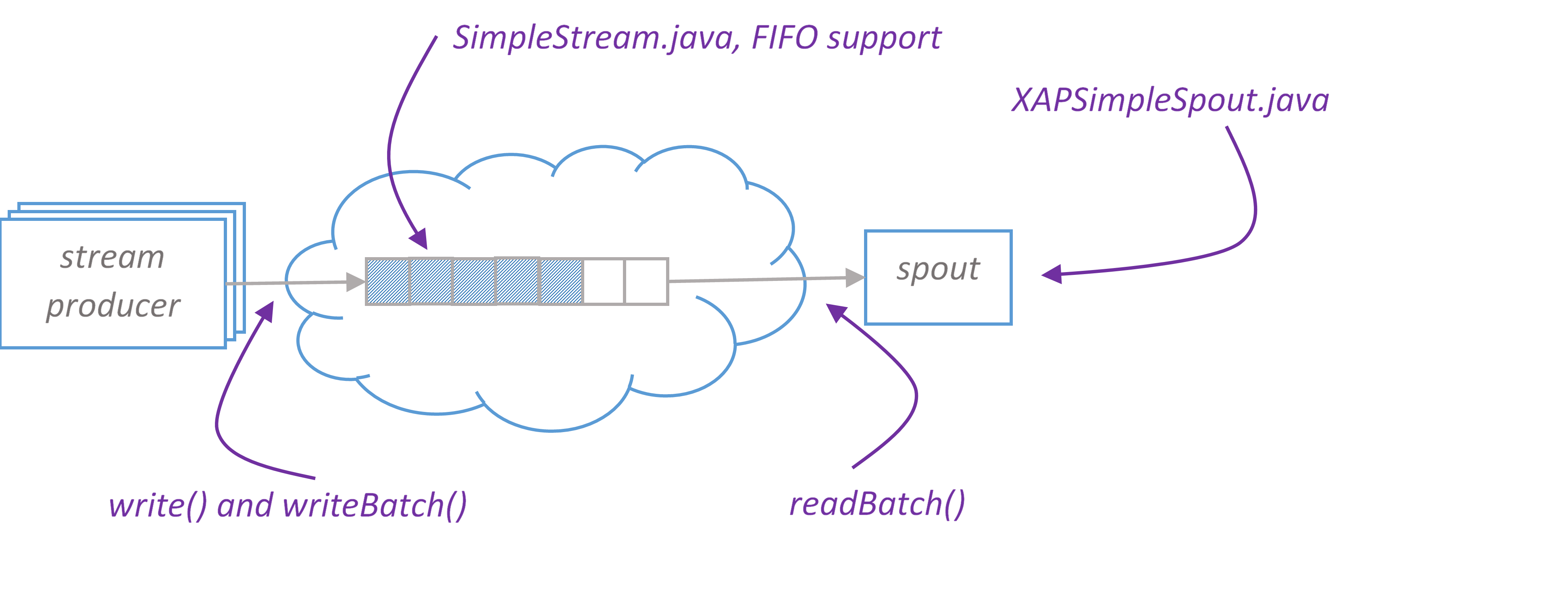
SimpleStream works with arbitrary space class that has FifoSupport.OPERATION annotation and implements Serializable.
Here is an example how one may write data to SimpleStream and process it in Storm topology. Let’s consider we would like to build an application to analyze the stream of page views (user clicks) on website. At first, we create a data model that represents a page view
@SpaceClass(fifoSupport = FifoSupport.OPERATION)
public class PageView implements Serializable {
private String id;
private String page;
private String sessionId;
[getters setters omitted for brevity]
}
Now we would like to create a reference to stream instance and write some data.
SimpleStream<PageView> stream = new SimpleStream<>(space, new PageView());
stream.writeBatch(pageViews);
The second argument of SimpleStream is a template used to match objects during reading.
If you want to have several streams with the same type, template objects should differentiate your streams.
Now let’s create a spout for PageView stream.
public class PageViewSpout extends XAPSimpleSpout<PageView> {
public PageViewSpout() {
super(new PageViewTupleConverter(), new PageView());
}
}
To create a spout, we have to specify how we want our space class be converted to Storm tuple. That is exactly what TupleConverter knows about.
class PageViewTupleConverter implements TupleConverter<PageView> {
@Override
public Fields tupleFields() {
return new Fields("page", "session");
}
@Override
public List<Object> spaceObjectToTuple(PageView pageView) {
return Arrays.<Object>asList(pageView.getPage(), pageView.getSessionId());
}
}
At this point we have everything ready to build Storm topology with PageViewSpout.
Config conf = new Config();
conf.put(ConfigConstants.XAP_SPACE_URL_KEY, "jini://*/*/space");
conf.put(ConfigConstants. XAP_STREAM_BATCH_SIZE, 300);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("pageViewSpout", new PageViewSpout());
ConfigConstants.XAP_SPACE_URL_KEY is a space URL
ConfigConstants. XAP_STREAM_BATCH_SIZE is a maximum number of items that spout reads from XAP with one hit.
Trident Spout
XAPTranscationalTridentSpout is a scalable, fault-tolerant, transactional spout for Trident, supports pipelining. Let’s discuss all its properties in details.
For spout to be maximally performant, we want an ability to scale the number of instances to control the parallelism of reader threads.
There are several spout APIs available that we could potentially use for our XAPTranscationalTridentSpout implementation:
- IPartitionedTridentSpout: A transactional spout that reads from a partitioned data source. The problem with this API is that it doesn’t acknowledge when batch is successfully processed which is critical for in memory solutions since we want to remove items from the grid as soon as they have been processed. Another option would be to use XAP’s lease capability to remove items by time out. This might be unsafe, if we keep items too long, we might consume all available memory.
- ITridentSpout: The most general API. Setting parallelism hint for this spout to N will create N spout instances, single coordinator and N emitters. When coordinator issues new transaction id, it passes this id to all emitters. Emitter reads its portion of transaction by given transaction id. Merged data from all emitters forms transaction.
For our implementation we choose ITridentSpout API.
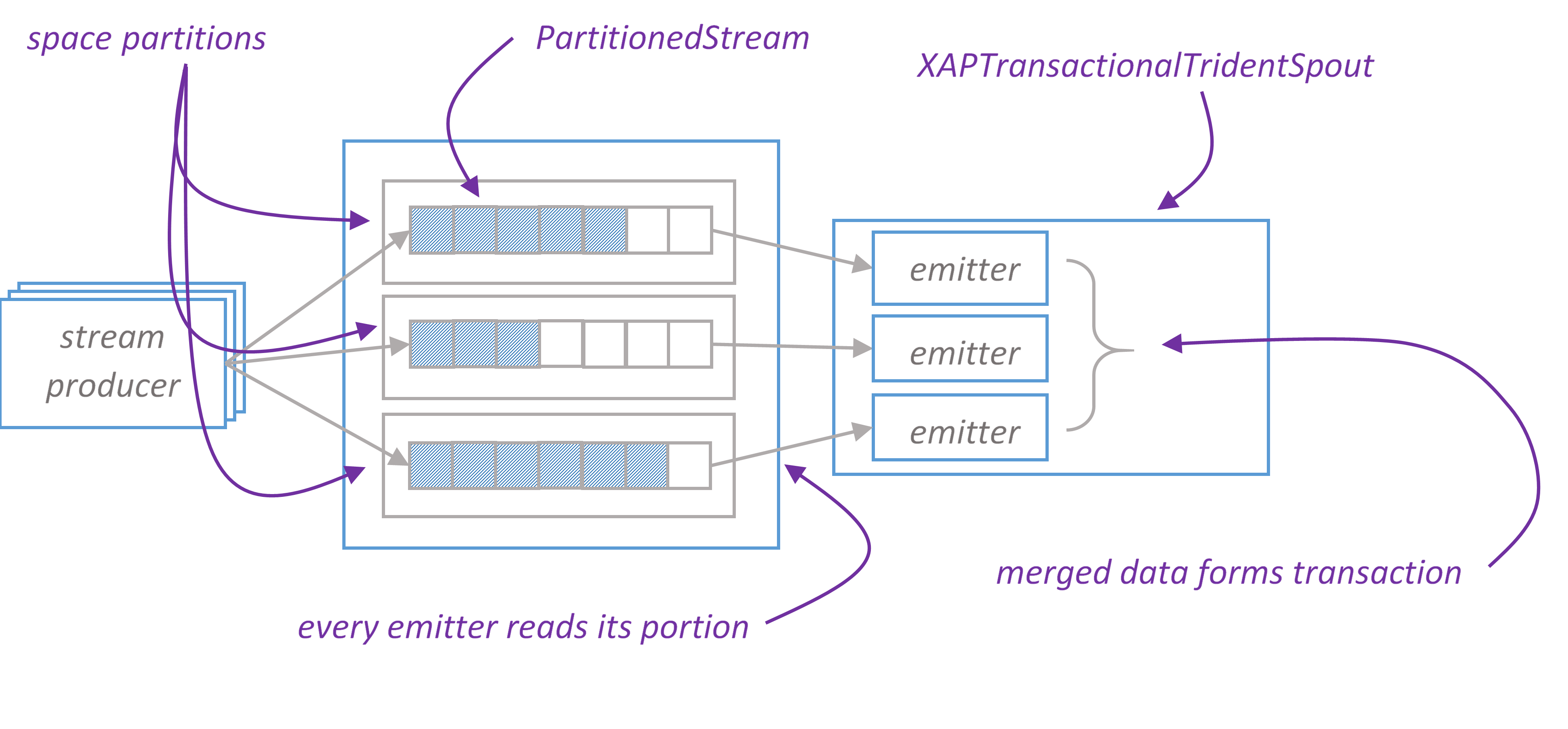
There is one to one mapping between XAP partitions and emitters.
Storm framework guarantees that topology is high available, if some component fails, it restarts it. That means our spout implementation should be stateless or able to recover its state after failure.
When emitter is created, it calls remote service ConsumerRegistryService to register itself. ConsumerRegistryService knows the number of XAP partitions and keeps track of the last allocated partition. This information is reliably stored in the space, see ConsumerRegistry.java.
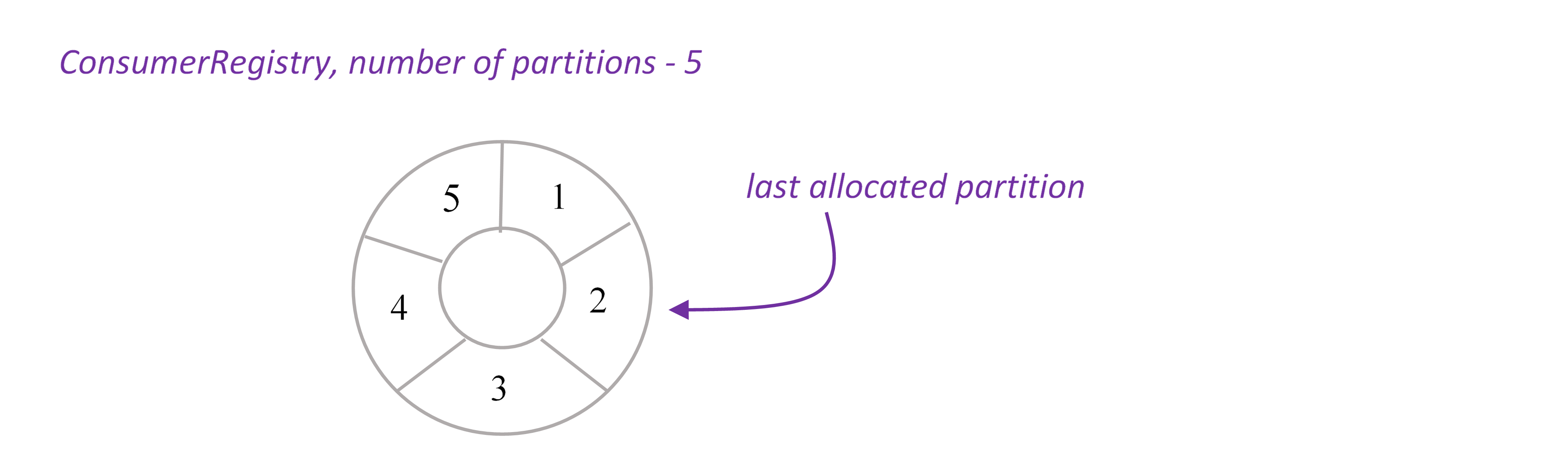
Remember that parallelism hint for XAPTranscationalTridentSpout should equal to the number of XAP partitions.
The property of being transactional is defined in Trident as following: - batches for a given txid are always the same. Replays of batches for a txid will exact same set of tuples as the first time that batch was emitted for that txid. - there’s no overlap between batches of tuples (tuples are in one batch or another, never multiple). - every tuple is in a batch (no tuples are skipped)
XAPTranscationalTridentSpout works with PartitionedStream that wraps stream elements into Item class and keeps items ordered by ‘offset’ property. There is one PartitionStream instance per XAP partition.
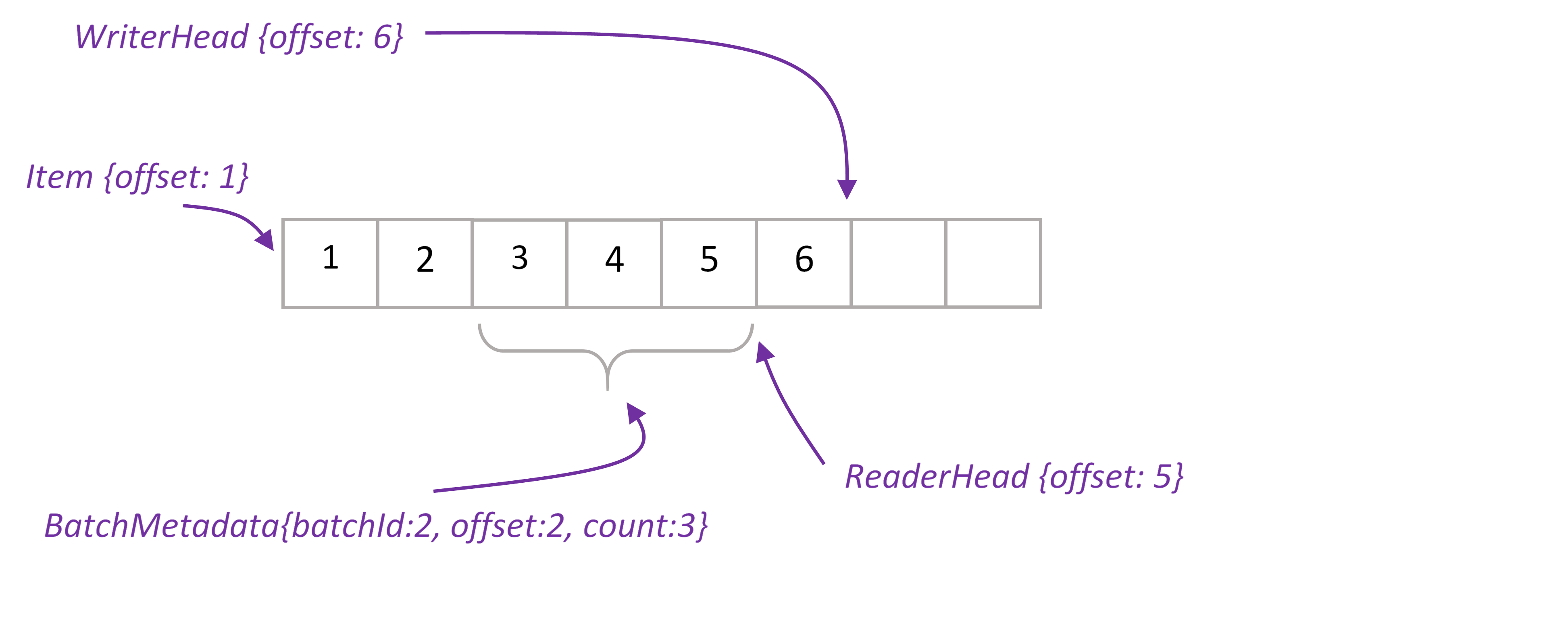
Stream’s WriterHead holds the last offset in the stream. Any time batch of elements (or single element) written to stream, WriterHead incremented by the number of elements. Allocated numbers used to populate offset property of Items. WriterHead object is kept in heap, there is no need to keep it in space. If primary partition fails, WriterHead is reinitialized to be the max offset value for given stream.
ReaderHead points to the last read item. We have to keep this value in the space, otherwise if partition fails we won’t be able to infer this value.
When spout request new batch, we take ReaderHead, read data from that point and update ReaderHead. New BatchMetadata object is placed to the space, it keeps start offset and number of items in the batch. In case Storm requests transaction replaying, we are able to reread exactly the same items by given batchId. Finally, once Storm acknowledges that batch successfully processed, we delete BatchMetadata and corresponding items from the spac