Elastic Processing Unit
An Elastic Processing Unit (EPU) is a Processing Unit with additional capabilities that simplify its deployment across multiple machines. Containers and machine resources such as Memory and CPU are automatically provisioned based on Memory and CPU requirements. When a machine failure occurs, or when scale requirements change, new machines are provisioned and the Processing Unit deployment distribution is balanced automatically. The PU scale is triggered by modifying the requirements through an API call. From that point in time the EPU continuously maintains the specified capacity (indefinitely, or until the next scale trigger).
The EPU has following features:
- SLA based deployment where required memory and cores can be specified.
- Automatic container lifecycle management.
- Automatic re-balancing (repartitioning).
- Automatic partition count calculation.
- Scale up/down or in/out without system downtime.
- Eager and manual scale strategies.
- Automatic machine provisioning plug-in.
Basic steps when using the EPU:
- Start GigaSpaces agents
Deploy PU
- Specify maximum PU capacity
- Specify container memory capacity
- Specify initial PU capacity
Scale up/down or in/out
Undeploy
Here is a simple example scaling a running EPU. With the following illustration the system using initially 2 machines, 20 partitions , 20 instances per machine (40 instances total), 4 instances per GSC, GSC capacity is 8GB. Total memory capacity 80 GB.:
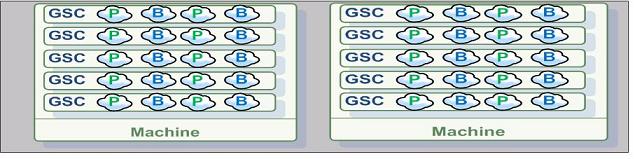
After scaling it to leverage 10 machines, we will have 4 instances per machine, 1 instance per GSC. Total memory capacity 400 GB.

Here is a quick EPU tutorial:
For a quick start follow the Elastic Processing Unit deployment example. When using the EPU, GigaSpaces manage the entire life cycle of the container. Once the EPU is deployed containers are started and the EPU instances are provisioned into these containers. When the EPU scales up, additional containers are started and instances are relocated into these containers. When the EPU is un-deployed, all the containers associated with the EPU are automatically terminated.
This page has three main sections:
- The EPU Deployment section describes the required deployment parameters and capacity planning considerations.
- The Scale Triggers section describes how to scale a PU after it has been deployed.
- The Machine Provisioning, describes how to start the GigaSpaces agent on each machine, plug-in development for different cloud providers and the algorithm that re-balances the PU across the machines.
With XAP 8.0 the EPU supports only partitioned deployment topology. The scale event is triggered by the administrator and not automatically when memory reaches a certain threshold.
EPU Deployment
The deployment of a partitioned (space based) EPU and stateless/web EPU is done via the Admin API.
In order for the deployment to work, the Admin API must first discover a running GSM, ESM (managers) and running GSAs (GigaSpaces agents).
// Wait for the discovery of the managers and at least one GigaSpaces agent
Admin admin = new AdminFactory().addGroup("myGroup").create();
admin.getGridServiceAgents().waitForAtLeastOne();
admin.getElasticServiceManagers().waitForAtLeastOne();
GridServiceManager gsm = admin.getGridServiceManagers().waitForAtLeastOne();
Maximum Memory Capacity
The EPU deployment requires two important properties:
memoryCapacityPerContainerdefines the Java Heap size of the Java Virtual Machine and is the most granular memory allocation deployment property. It is internally translated to:
commandLineArgument("-Xmx"+memory).commandLineArgument("-Xms"+memory)
.
maxMemoryCapacityprovides an estimate for the maximum total Processing Unit memory.
Here is a typical example for a memory capacity Processing Unit deployment. The example also includes a scale trigger that is explained in the following sections of this page.
// Deploy the Elastic Stateful Processing Unit
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.maxMemoryCapacity(512,MemoryUnit.GIGABYTES)
//initial scale
.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(128,MemoryUnit.GIGABYTES)
.create()));
);
Here is again the same example, this time the deployed Processing Unit is a pure Space (no jar files):
// Deploy the Elastic Space
ProcessingUnit pu = gsm.deploy(
new ElasticSpaceDeployment("mySpace")
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.maxMemoryCapacity(512,MemoryUnit.GIGABYTES)
//initial scale
.scale(
new ManualCapacityScaleConfigurer()
.memoryCapacity(128,MemoryUnit.GIGABYTES)
.create())
);
The memoryCapacityPerContainer and maxMemoryCapacity properties are used to calculate the number of partitions for the Processing Unit as follows:
minTotalNumberOfInstances
= ceil(maxMemoryCapacity/memoryCapacityPerContainer)
= ceil(1024/256)
= 4
numberOfPartitions
= ceil(minTotalNumberOfInstances/(1+numberOfBackupsPerPartition))
= ceil(4/(1+1))
= 2
The number of Processing Unit partitions cannot be changed without re-deployment of the PU.
Maximum Number of CPU Cores
In many cases when you should take the number of space operations per second into consideration when scaling the system. The memory utilization will be a secondary factor when calculating the required scale. For example, if the system performs mostly data updates (as opposed to reading data), the CPU resources could be a limiting factor more than the total memory capacity. In these cases use the maxNumberOfCpuCores deployment property. Here is a typical deployment example that includes CPU capacity planning:
// Deploy the EPU
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.maxMemoryCapacity(512,MemoryUnit.GIGABYTES)
.maxNumberOfCpuCores(32)
// continously scale as new machines are started
.scale(new EagerScaleConfig())
);
The maxNumberOfCpuCores property provides an estimate for the maximum total number of CPU cores on machines that have one or more primary processing unit instances deployed (instances that are not in backup state). Internally the number of partitions is calculated as follows:
minTotalNumberOfInstances
= ceil(maxMemoryCapacity/memoryCapacityPerContainer)
= ceil(1024/256)=4
minNumberOfPrimaryInstances
= ceil(maxNumberOfCpuCores/minNumberOfCpuCoresPerMachine)
= ceil(8/2)
= 4
numberOfPartitions
= max(minNumberOfPrimaryInstances,
ceil(minTotalNumberOfInstances/(1+numberOfBackupsPerPartition))
= max(4, 4/(1+1) )
= 4
In order to evaluate the minNumberOfCpuCoresPerMachine, the deployment communicates with each discovered GigaSpaces agent and collects the number of CPU cores the operating system reports. In case a machine provisioning plugin (cloud) is used, the plugin provides that estimate instead. The minNumberOfCpuCoresPerMachine deployment property can also be explicitly defined.
Explicit Number of Partitions
The numberOfPartitions property allows explicit definition of the number of space partitions. When the numberOfPartitions property is defined then maxMemoryCapacity and maxNumberOfCpuCores should not be defined.
// Deploy the EPU
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.numberOfPartitions(12)
.scale(new EagerScaleConfig())
);
Here is another example, deployment with explicit number of partitions and memory capacity scale trigger:
// Deploy the EPU
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.numberOfPartitions(12)
.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(16,MemoryUnit.GIGABYTES)
.create())
)
);
// Application continues
Thread.sleep(10000);
// Scale out to 32GB memory
pu.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(32,MemoryUnit.GIGABYTES)
.create()
);
Specifying number of partitions explicitly is recommended only when fine grained scale triggers are required. The example below illustrating 12 partitions system (12 primaries + 12 backups = 24 instances). See how the system scales to have increased total memory capacity as a function of the number of Containers and memoryCapacityPerContainer:
| Number of Containers | Number of partitions per container | Total available memory |
|---|---|---|
| 2 | 24 / 2 = 12 | 2 * 6GB = 12GB |
| 4 | 24 / 4 = 6 | 4 * 6GB = 24GB |
| 8 | 24 / 8 = 3 | 8 * 6GB = 48GB |
| 12 | 24 / 12 = 2 | 12 * 6GB = 72GB |
| Number of Containers | Number of partitions per container | Total available memory |
|---|---|---|
| 2 | 24 / 2 = 12 | 2 * 12GB = 24GB |
| 4 | 24 / 4 = 6 | 4 * 12GB = 48GB |
| 8 | 24 / 8 = 3 | 8 * 12GB = 96GB |
| 12 | 24 / 12 = 2 | 12 * 12GB = 144GB |
| Number of Containers | Number of partitions per container | Total available memory |
|---|---|---|
| 2 | 24 / 2 = 12 | 2 * 24GB = 48GB |
| 4 | 24 / 4 = 6 | 4 * 24GB = 96GB |
| 8 | 24 / 8 = 3 | 8 * 24GB = 192GB |
| 12 | 24 / 12 = 2 | 12 * 24GB = 288GB |
Having larger number of partitions will provide you better flexibility in terms of having more scaling “check points”. Having too many partitions (hundreds) will impact the system performance since in some point this will generate some overhead due to the internal monitoring required for each partition.
Deployment on a Single Machine (for development purposes)
For development and demonstration purposes, it is very convenient to deploy the EPU on a single machine. By default, the minimum number of machines is two (for high availability concerns). This could be changed using the singleMachineDeployment property.
// Deploy the EPU
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(256,MemoryUnit.MEGABYTES)
.maxMemoryCapacity(1024,MemoryUnit.MEGABYTES)
.singleMachineDeployment() // deploy on a single machine
// other processes running on machine would have at least 2GB left
.dedicatedMachineProvisioning(
new DiscoveredMachineProvisioningConfigurer()
.reservedMemoryCapacityPerMachine(2,MemoryUnit.GIGABYTES)
.create())
//initial scale
.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(512,MemoryUnit.MEGABYTES)
.create())
);
Stateless / Web Elastic Processing Units
Stateless Processing Units do not include an embedded space, and therefore are not partitioned. Deployment of stateless processing unit is performed by specifying the required total number of CPU cores. This ensures 1 container per machine.
// Deploy the Elastic Stateless Processing Unit
ProcessingUnit pu = gsm.deploy(
new ElasticStatelessProcessingUnitDeployment("servlet.war")
.memoryCapacityPerContainer(4,MemoryUnit.GIGABYTES)
//initial scale
.scale(
new ManualCapacityScaleConfigurer()
.numberOfCpuCores(10)
.create())
);
Scale Triggers
Manual Capacity Scale Trigger
The system administrator may specify the memory and/or CPU core resources required for the processing unit in production. This should be specified during the deployment time, and could be specified also anytime after the deployment. The memory capacity trigger affects the number of provisioned containers. If there are not enough machines to host the provisioned containers the trigger also affects the number of provisioned machines. The number of CPUs affect directly the number of provisioned machines (even if it means that some of the machines have unused memory).
When specifying both memory and cores capacity requirements as part of the deploy and scale routines, the EPU will be deployed successfully only when both memory and cores resources can be allocated (sufficient amount of memory and cores across the available machines). If you would like to the memory capacity requirements to take precedence on the cores capacity requirements, have lower values for the cores capacity requirements than the exact existing cores count.
Here is an example how you can scale a deployed EPU memory and CPU capacity.
Step 1 - Deploy the PU:
We deploy the PU having 512GB as the maximum total amount of memory utilized both for primary and backup instances where the entire system should consume maximum of 32 cores. At start only 128GB and 8 cores will be utilized.
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.maxMemoryCapacity(512,MemoryUnit.GIGABYTES)
.maxNumberOfCpuCores(32)
// set the initial memory and CPU capacity
.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(128,MemoryUnit.GIGABYTES)
.numberOfCpuCores(8)
.create())
);
// Wait until the deployment is complete.
pu.waitForSpace().waitFor(pu.getTotalNumberOfInstances());
Step 2 - Increase the memory capacity from 128GB to 256GB and number of cores from 8 to 16:
ProcessingUnit pu = admin.getProcessingUnits().waitFor("myPU", 5,TimeUnit.SECONDS); //get the PU
// increasing the memory capacity will start new containers
// existing machines if enough free memory is available
pu.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(256,MemoryUnit.GIGABYTES)
.numberOfCpuCores(16)
.create());
Step 3 - Increase the memory capacity from 256GB to 512GB and number of cores from 16 to 32:
ProcessingUnit pu = admin.getProcessingUnits().waitFor("myPU", 5,TimeUnit.SECONDS); //get the PU
// scales out to more CPU cores (existing containers are terminated on existing machines and
// new are started on new machines if not enough CPU cores are available on existing machines)
pu.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(512,MemoryUnit.GIGABYTES)
.numberOfCpuCores(32)
.create());
Step 4 - Decrease the memory capacity and CPU capacity:
ProcessingUnit pu = admin.getProcessingUnits().waitFor("myPU", 5,TimeUnit.SECONDS); //get the PU
pu.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(128,MemoryUnit.GIGABYTES)
.numberOfCpuCores(8)
.create());
Eager Scale Trigger
Eager trigger scales the EPU on all available machines and new machines joining the GigaSpaces Grid. Each new machine running a GigaSpaces agent automatically starts a new container hosting the EPU partition instance(s) relocated from some other container. To use the Eager Scale Trigger you should scale the EPU using the EagerScaleConfigurer:
pu.scale(new EagerScaleConfigurer().create());
The Eager trigger has the following limitations:
- Number of maximum machines is limited to the number of partitions calculated/defined during the deployment time. This limitation does not exist for stateless processing units.
- Multiple Eager EPUs can run on the same Lookup Service but on different machines. Machines are marked by starting a Grid Service Agent with a specific zone (With a command line argument -Dcom.gs.zones=zone1).
ProcessingUnit pu1 = gsm.deploy(
new ElasticSpaceDeployment("eagerspace1")
.maxMemoryCapacity(10, MemoryUnit.GIGABYTES)
.memoryCapacityPerContainer(1, MemoryUnit.GIGABYTES)
// discover only agents with "zone1"
.dedicatedMachineProvisioning(
new DiscoveredMachineProvisioningConfigurer()
.addGridServiceAgentZone("zone1")
.removeGridServiceAgentsWithoutZone()
.create())
// eager scale
.scale(new EagerScaleConfigurer()
.create())
);
ProcessingUnit pu2 = gsm.deploy(
new ElasticSpaceDeployment("eagerspace2")
.maxMemoryCapacity(10, MemoryUnit.GIGABYTES)
.memoryCapacityPerContainer(1, MemoryUnit.GIGABYTES)
//discover only agents with "zone2"
.dedicatedMachineProvisioning(
new DiscoveredMachineProvisioningConfigurer()
.addGridServiceAgentZone("zone2")
.removeGridServiceAgentsWithoutZone()
.create())
//eager scale
.scale(new EagerScaleConfigurer()
.create())
);
The differences between the Eager scale trigger and a Manual capacity trigger in terms of the maximum amount of memory and CPU are:
- Manual capacity trigger expects the administrator to start enough available machines running the GigaSpaces agent to satisfy the specified capacity. Since it expects a new machine to be started, it does not balance the Processing Unit instances nor it does start new containers, until the machines are started. Eager trigger, on the other hand, redeploys as best as it can on the available machines, and scales out only when another machine is started or until the max capacity is reached.
- The Eager trigger spreads out thin if enough machines are available (to gain as much CPU resources as possible). Manual trigger spreads out to new machines, before existing machines’ memory is utilized, only when the
numberOfCpuproperty is high enough.
Machine Provisioning
System Bootstrapping
Each machine requires a single running GigaSpaces Agent. The example below shows how to start a new GigaSpaces agent. The command line parameters instruct the agents to communicate with each other and start the specified amount of managers. It does not start any containers automatically. The EPU starts containers on demand.
That means that potentially any machine could be a management machine:
rem Agent deployment that potentially can start management processes
set LOOKUPGROUPS=myGroup
set JSHOMEDIR=d:\gigaspaces
start cmd /c "%JSHOMEDIR%\bin\gs-agent.bat gsa.global.esm 1 gsa.gsc 0 gsa.global.gsm 2 gsa.global.lus 2"
1. Agent deployment that potentially can start management processes
export LOOKUPGROUPS=myGroup
export JSHOMEDIR=~/gigaspaces
nohup ${JSHOMEDIR}/bin/gs-agent.sh gsa.global.esm 1 gsa.gsc 0 gsa.global.gsm 2 gsa.global.lus 2 > /dev/null 2>&1 &
Dedicated Management Machines
In case you prefer having dedicated management machines, start GigaSpaces agents with the above settings on two machines, and start the rest of the GigaSpaces agents with the settings below. The command line parameters instruct the GigaSpaces agents not to start managers. It does not start any containers automatically. The EPU starts containers on demand:
rem Agent that does not start management processes
set LOOKUPGROUPS=myGroup
set JSHOMEDIR=d:\gigaspaces
start cmd /c "%JSHOMEDIR%\bin\gs-agent.bat gsa.global.esm 0 gsa.gsc 0 gsa.global.gsm 0 gsa.global.lus 0"
1. Agent that does not start management processes
export LOOKUPGROUPS=myGroup
export JSHOMEDIR=~/gigaspaces
nohup ${JSHOMEDIR}/bin/gs-agent.sh gsa.global.esm 0 gsa.gsc 0 gsa.global.gsm 0 gsa.global.lus 0 > /dev/null 2>&1 &
Configure the EPU scale config to use dedicatedManagementMachines, and reduce the reservedMemoryCapacityPerMachine. For more information consult the discovered machine provisioning configuration JavaDoc.
Zone Based Machine Provisioning
The EPU can be deployed into specific zone. This allows you to determine the specific locations of the EPU instances. You may have multiple EPU deployed, each into a difference zone. To specify the agent zone you should set the zone name before starting the agent - here is an example how to set the agent zone to ZoneX:
export GSA_JAVA_OPTIONS="-Dcom.gs.zones=zoneX ${GSA_JAVA_OPTIONS}"
gs-agent.sh gsa.global.lus 1 gsa.lus 0 gsa.global.gsm 1 gsa.gsm 0 gsa.gsc 0 gsa.global.esm 1
When deploying the EPU you should specify the zone you would like the EPU will be deployed into:
ProcessingUnit pu1 = gsm.deploy(
new ElasticSpaceDeployment("mySpace")
.maxMemoryCapacity(512, MemoryUnit.GIGABYTES)
.memoryCapacityPerContainer(10, MemoryUnit.GIGABYTES)
// discover only agents with "zoneX"
.dedicatedMachineProvisioning(new DiscoveredMachineProvisioningConfigurer()
.addGridServiceAgentZone("zoneX")
.removeGridServiceAgentsWithoutZone()
.create())
.scale(new ManualCapacityScaleConfigurer()
.memoryCapacity(256,MemoryUnit.GIGABYTES)
.create())
With the above the mySpace EPU will be deployed only into agents associated with zoneX where other agents without a zone specified will be ignored.
Automatic Machine Provisioning
When deploying an EPU pass an instance of ElasticMachineProvisioningConfig as the machineProvisioning deployment property.
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.maxMemoryCapacity(512,MemoryUnit.GIGABYTES)
.maxNumberOfCpuCores(32)
//automatically start new virtual machines on demand
.dedicatedMachineProvisioning(new XenServerMachineProvisioning("xenserver.properties"))
);
When deploying Gigaspaces XAP on the management machine(s) place the plug-in JAR file under /gigaspaces-xap/lib/platform/esm folder. The ESM then loads classes specified by the machineProvisioning configuration. These classes need to implement either ElasticMachineProvisioning or NonBlockingElasticMachineProvisioning. That class must also implement Bean which has resemblance to the Spring Bean.
Automatic Rebalancing
Each stateful processing unit (embedding a space) has a fixed number of logical partitions. The number of logical partitions can be specified by the user or calculated by GigaSpaces using the memory capacity requirements during the deployment time. Each logical partition has by default two instances - a primary and a backup. Instances of an EPU are automatically relocated between containers until the following criteria is met:
- Number of instances per container is nearly the same across all containers.
- Number primary instances per cores is nearly the same across all machines.
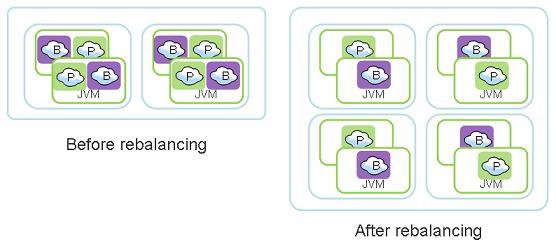
How Rebalancing works
GigaSpaces runtime environment differentiate between a Container (GSC) or Grid node that is running within a single JVM instance and an IMDG node, also called a logical partition. A partition has one primary instance and zero or more backup instances.
A grid node hosts zero or more logical partitions, these may be primary or backup instances belong to different logical partitions. Logical partitions (primary or backup instances) may relocate between Grid nodes during runtime. A deployed stateful PU may expand its capacity or shrink its capacity in real-time by adding or removing Grid nodes and relocating existing logical partitions to the newly started Grid nodes.
If the system selects to relocate a primary instance, it will first switch its activity mode into a backup mode and the existing backup instance of the same logical partition will be switched into a primary mode. Once the new backup will be relocated, it will recover its data from the existing primary. This how the PU expands its capacity without disruption to the client application.
GigaSpaces rebalancing controls which logical partition is moving, where it is moving to and whether to move a primary to a backup instance. Without such control, the system might choose to move partitions into containers that are fully consumed or move too many instances into the same container. This will obviously crash the system.
Adaptive SLA
GigaSpaces adjust the high-availability SLA dynamically to cope with the current system memory resources. This means that if there is not sufficient memory capacity to instantiate all the backup instances, GigaSpaces will relax the SLA in runtime to allow the system to continue and run. Once the system identifies that there are enough resources to accommodate all the backups, it will start the missing backups automatically.
Re-balancing Automatic Process Considerations
- It assumes that all partitions are equal (in terms of memory and CPU consumption).
- When manual capacity scale is used, the specified memory capacity and CPU cores must be provisioned before the re-balancing takes place. As long as the available machines do not meet the specified memory capacity or CPU cores re-balancing does not take place.
- The maximum number of CPU cores that can be occupied by the Processing Unit primary instances is:
numberOfPartitions X numberOfCpuCoresPerMachine
.
- The maximum amount of memory that can be used by the primary and backup instances is:
numberOfPartitions X ( 1 + numberOfBackupsPerPartition ) X memoryCapacityPerContainer
.
- During relocation of a specific instance, primary election takes place. For a few seconds, operations on that partition and operations on the whole cluster is denied. Internally, the client proxy retries the operation until the primary election takes place and masks the failure, but the delay exists. This delay can be reduced by modifying configuration settings as explained in Failure Detection. Overriding the default value of these context properties is achieved with the addContextProperty deployment property. For example:
ProcessingUnit pu = gsm.deploy(
new ElasticStatefulProcessingUnitDeployment(new File("myPU.jar"))
.memoryCapacityPerContainer(16,MemoryUnit.GIGABYTES)
.maxMemoryCapacity(512,MemoryUnit.GIGABYTES)
.maxNumberOfCpuCores(32)
.addContextProperty("cluster-config.groups.group.fail-over-policy.active-election.yield-time","300")
);
Shared Machine Provisioning
In the code examples above, we showed the usage of .dedicatedMachineProvisioning. ‘Dedicated’ machine provisioning means that the whole machine is ‘reserved’ for instances of a single processing unit. In other words, other processing units are denied to co-exist on the same machine. This policy is useful if one processing unit should not be affected by other resource consuming processes.
For sharing a machine between processing units, you would need to specify a sharing ID - a simple string identifying your sharing policy. When a processing unit is requested to scale-out, a new machine is marked with the sharing ID of the processing unit. This ensures that no other processing unit will race to occupy the machine. This sharing ID is later used to match against other processing unit’s sharing ID - to allow or deny sharing the same machine resource.
To simulate a ‘public’ sharing policy, use the same sharing ID for all deployments. For example .sharedMachineProvisioning("public").
The following example, shows two elastic stateless processing units that may share each others machine resources.
// Deploy the Elastic Stateless Processing Unit on "site1"
ProcessingUnit puA = gsm.deploy(
new ElasticStatelessProcessingUnitDeployment("servlet.war")
.name("servlet-A")
.memoryCapacityPerContainer(4,MemoryUnit.GIGABYTES)
//initial scale
.scale(
new ManualCapacityScaleConfigurer()
.memoryCapacity(1,MemoryUnit.GIGABYTES)
.create())
.sharedMachineProvisioning("site1", machineProvisioningConfig)
);
// Deploy the Elastic Stateless Processing Unit on "site1"
ProcessingUnit puB = gsm.deploy(
new ElasticStatelessProcessingUnitDeployment("servlet.war")
.name("servlet-B")
.memoryCapacityPerContainer(4,MemoryUnit.GIGABYTES)
//initial scale
.scale(
new ManualCapacityScaleConfigurer()
.memoryCapacity(1,MemoryUnit.GIGABYTES)
.create())
.sharedMachineProvisioning("site1", machineProvisioningConfig)
);
Main Configuration Properties
Elastic Deployment Topology Configuration
Here are the main configuration properties you may use with the ElasticSpaceDeployment and the ElasticStatefulProcessingUnitDeployment:
| Property | Type | Description | Default | Mandatory |
|---|---|---|---|---|
| highlyAvailable | boolean | Specifies if the space should duplicate each information on two different machines. | true | No |
| memoryCapacityPerContainer | int , MemoryUnit | Specifies the the heap size per container (operating system process) | Yes | |
| minNumberOfCpuCoresPerMachine | double | Overrides the minimum number of CPU cores per machine assumption. | No | |
| maxMemoryCapacity | int , MemoryUnit | Specifies an estimate of the maximum memory capacity for this processing unit. | Yes | |
| maxNumberOfCpuCores | int | Specifies an estimate for the maximum total number of cpu cores used by this processing unit. | No | |
| numberOfPartitions | int | Defines the number of processing unit partitions. | No | |
| numberOfBackupsPerPartition | int | Overrides the number of backup processing unit instances per partition. | 1 | No |
| secured | boolean | deploy a secured processing unit. | false | No |
| singleMachineDeployment | Allows deployment of the processing unit on a single machine, by lifting the limitation for primary and backup processing unit instances from the same partition to be deployed on different machines. | false | No | |
| userDetails | UserDetails | Advanced: Sets the security user details for authentication and authorization of the processing unit. | No | |
| scale | EagerScaleConfig or ManualCapacityScaleConfig | Enables the specified scale strategy, and disables all other scale strategies. | No | |
| useScriptToStartContainer | Allow the GridServiceContainer to be started using a script and not a pure Java process. | No |
Scale Strategy Configuration
Here are the main configuration properties you may use with the EagerScaleConfig and the ManualCapacityScaleConfig:
| Property | Type | Description | Default | Mandatory |
|---|---|---|---|---|
| memoryCapacityInMB | int | Specifies the total memory capacity of the processing unit. | Yes | |
| numberOfCpuCores | int | Specifies the total CPU cores for the processing unit. | No | |
| maxConcurrentRelocationsPerMachine | int | Specifies the number of processing unit instance relocations each machine can handle concurrently. By setting this value higher than 1, processing unit re balancing completes faster, by using more machine cpu and network resources | 1 | No |
| reservedMemoryCapacityPerMachineInMB | int | Sets the expected amount of memory per machine that is reserved for processes other than grid containers. These include Grid Service Manager, Lookup Service or any other daemon running on the system. | 1024 MB | No |
EPU Example
The following demo illustrates the EPU. You may run it on your development machine or on your deployment machine. When running it on your development machine it will scale the EPU within the machine and expand or shrink the memory capacity without any downtime. The demo includes the following phases:
- Initial Deployment of an EPU with maximum of 256 MB memory capacity and initial capacity of 64 MB.
- Scaling up to 128 MB
- Scaling up to 256 MB
- Scaling down to 64 MB
This demo assumes you have about 300 MB available memory on your machine.
Running the Example
Download and Install Download the example and extract it.
Start gs-agent Start gs-agent using the following command:
gs-agent gsa.esm 1 gsa.gsc 0 gsa.lus 1 gsa.gsm 1
This will start an agent without any running GSCs.
- Run the Client Application Run the Client Application using the following command:
call C:\gigaspaces-xap-premium-8.0.0-ga\bin\setenv.bat
java -cp bin;%GS_JARS% -Djava.rmi.server.hostname=127.0.0.1 -DlocalMachineDemo=true com.test.scaledemo.ScaleDemoMain
- You should replace the GigaSpaces root folder and your machine IP with the relevant values.
- You will find a
run.batscript you may use to run the client.
Demo Expected Instances Distribution
When running the GS-UI you will have the following displayed:
Initial State - agent without any GSCs running:
After initial Deploy:

After Scaling from 64.0 MB to 128 MB:
After Scaling from 128.0 MB to 256 MB:
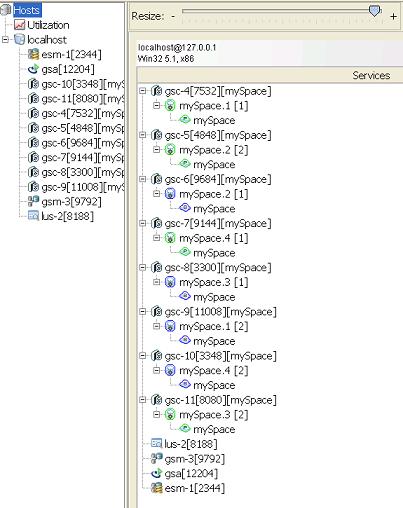
After Scaling from 256.0 MB to 64 MB:
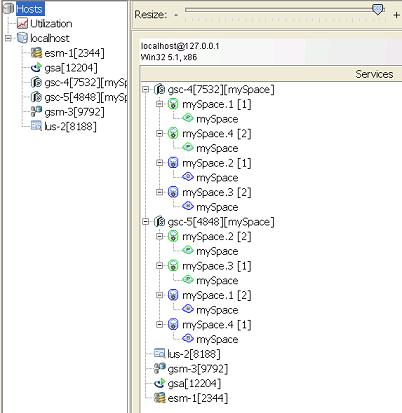
Demo Expected Output
The Client application will display the following output:
Welcome to GigaSpaces scalability Demo
Log file: C:\gigaspaces-xap-premium-X.x-ga\logs\2011-03-01~12.34-gigaspaces-service-127.0.0.1-6760.log
Created Admin - OK!
Data Grid PU not running - initial deploy
--- > Local Machine Demo - Starting initial deploy - Deploying a PU with:64MB
Tue Mar 01 12:34:53 EST 2011>> Total Memory used:0.0 MB - Progress:0.0 % done - Total Containers:0
Tue Mar 01 12:34:57 EST 2011>> Total Memory used:0.0 MB - Progress:0.0 % done - Total Containers:1
Tue Mar 01 12:35:01 EST 2011>> Total Memory used:0.0 MB - Progress:0.0 % done - Total Containers:1
Tue Mar 01 12:35:05 EST 2011>> Total Memory used:0.0 MB - Progress:0.0 % done - Total Containers:2
Tue Mar 01 12:35:09 EST 2011>> Total Memory used:0.0 MB - Progress:0.0 % done - Total Containers:2
Tue Mar 01 12:35:13 EST 2011>> Total Memory used:0.0 MB - Progress:0.0 % done - Total Containers:2
Tue Mar 01 12:35:17 EST 2011>> Total Memory used:64.0 MB - Progress:100.0 % done - Total Containers:2
Initial Deploy done! - Time to deploy system:32 seconds
About to start changing data-grid memory capacity from 64.0 MB to 128 MB
Hit enter to scale the data grid...
Tue Mar 01 12:37:02 EST 2011>> Total Memory used:64.0 MB - Progress:50.0 % done - Total Containers:2
Tue Mar 01 12:37:04 EST 2011>> Total Memory used:64.0 MB - Progress:50.0 % done - Total Containers:2
Tue Mar 01 12:37:06 EST 2011>> Total Memory used:64.0 MB - Progress:50.0 % done - Total Containers:3
Tue Mar 01 12:37:08 EST 2011>> Total Memory used:64.0 MB - Progress:50.0 % done - Total Containers:3
Tue Mar 01 12:37:10 EST 2011>> Total Memory used:64.0 MB - Progress:50.0 % done - Total Containers:4
Tue Mar 01 12:37:14 EST 2011>> Total Memory used:64.0 MB - Progress:50.0 % done - Total Containers:4
Tue Mar 01 12:37:17 EST 2011>> Total Memory used:96.0 MB - Progress:75.0 % done - Total Containers:4
Tue Mar 01 12:37:21 EST 2011>> Total Memory used:96.0 MB - Progress:75.0 % done - Total Containers:4
Tue Mar 01 12:37:25 EST 2011>> Total Memory used:96.0 MB - Progress:75.0 % done - Total Containers:4
Tue Mar 01 12:37:27 EST 2011>> Total Memory used:128.0 MB - Progress:100.0 % done - Total Containers:4
Data-Grid Memory capacity change done! - Time to scale system:27 seconds
About to start changing data-grid memory capacity from 128.0 MB to 256 MB
Hit enter to scale the data grid...
Tue Mar 01 12:38:21 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:4
Tue Mar 01 12:38:23 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:4
Tue Mar 01 12:38:25 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:5
Tue Mar 01 12:38:27 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:5
Tue Mar 01 12:38:29 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:6
Tue Mar 01 12:38:31 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:6
Tue Mar 01 12:38:33 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:7
Tue Mar 01 12:38:35 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:7
Tue Mar 01 12:38:37 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:8
Tue Mar 01 12:38:41 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:8
Tue Mar 01 12:38:43 EST 2011>> Total Memory used:160.0 MB - Progress:62.5 % done - Total Containers:8
Tue Mar 01 12:38:47 EST 2011>> Total Memory used:160.0 MB - Progress:62.5 % done - Total Containers:8
Tue Mar 01 12:38:51 EST 2011>> Total Memory used:160.0 MB - Progress:62.5 % done - Total Containers:8
Tue Mar 01 12:38:53 EST 2011>> Total Memory used:192.0 MB - Progress:75.0 % done - Total Containers:8
Tue Mar 01 12:38:57 EST 2011>> Total Memory used:192.0 MB - Progress:75.0 % done - Total Containers:8
Tue Mar 01 12:39:01 EST 2011>> Total Memory used:224.0 MB - Progress:87.5 % done - Total Containers:8
Tue Mar 01 12:39:05 EST 2011>> Total Memory used:224.0 MB - Progress:87.5 % done - Total Containers:8
Tue Mar 01 12:39:09 EST 2011>> Total Memory used:224.0 MB - Progress:87.5 % done - Total Containers:8
Tue Mar 01 12:39:11 EST 2011>> Total Memory used:256.0 MB - Progress:100.0 % done - Total Containers:8
Data-Grid Memory capacity change done! - Time to scale system:51 seconds
About to start changing data-grid memory capacity from 256.0 MB to 64 MB
Hit enter to scale the data grid...
Tue Mar 01 12:40:11 EST 2011>> Total Memory used:256.0 MB - Progress:25.0 % done - Total Containers:8
Tue Mar 01 12:40:14 EST 2011>> Total Memory used:224.0 MB - Progress:28.6 % done - Total Containers:7
Tue Mar 01 12:40:18 EST 2011>> Total Memory used:192.0 MB - Progress:33.3 % done - Total Containers:7
Tue Mar 01 12:40:22 EST 2011>> Total Memory used:192.0 MB - Progress:33.3 % done - Total Containers:6
Tue Mar 01 12:40:26 EST 2011>> Total Memory used:160.0 MB - Progress:40.0 % done - Total Containers:6
Tue Mar 01 12:40:28 EST 2011>> Total Memory used:160.0 MB - Progress:40.0 % done - Total Containers:5
Tue Mar 01 12:40:32 EST 2011>> Total Memory used:128.0 MB - Progress:50.0 % done - Total Containers:5
Tue Mar 01 12:40:36 EST 2011>> Total Memory used:96.0 MB - Progress:66.7 % done - Total Containers:4
Tue Mar 01 12:40:38 EST 2011>> Total Memory used:96.0 MB - Progress:66.7 % done - Total Containers:3
Tue Mar 01 12:40:42 EST 2011>> Total Memory used:64.0 MB - Progress:100.0 % done - Total Containers:3
Data-Grid Memory capacity change done! - Time to scale system:33 seconds
Considerations
- When deploying an existing EPU (redeploy), the system does not ignore the scale parameters. A
ProcessingUnitAlreadyDeployedExceptionwill be thrown, but the scale call will be executed. Future releases will throwProcessingUnitAlreadyDeployedExceptionwithout executing the scale call. - The speed up the deployment process you should increase the
maxConcurrentRelocationsPerMachineparameter to have a larger number than 1 (default value). Having a value of 2 or 3 might speed up the deploy time when having multiple machines. - Scaling EPU should be done using multipliers that match the amount of the initial capacity. This will allow the system to allocate the exact memory/cores requested.
- When deploying on a Single Machine (using the
singleMachineDeploymentmode) you should make sure the machine has enough memory/cores resources for the entire EPU instances. ThereservedMemoryCapacityPerMachineshould be used to ensure relevant resources. Without having these set, the deploy process will fail. - In case of a failure with the deploy process due to insufficient resources or other reasons, the ESM will retry to deploy the EPU. To stop this activity, you should explicitly undeploy the EPU. You may use the UI, CLI or API to undeploy it.
- To verify a successful deployment, you should check the PU status (see the
org.openspaces.admin.pu.ProcessingUnit.getStatus()and theorg.openspaces.admin.pu.ProcessingUnit.getProcessingUnitStatusChanged()). You may also check the total amount of memory/cores utilized by the EPU by iterating the PU instances. - To monitor the EPU deployment you should monitor the ESM. A simple way to do that is to review its log file. You may use the GS-UI to have direct access to the ESM log files.