Overview
GigaSpaces Data-Grid clustering Scalability and High-Availability are based on the following concepts:
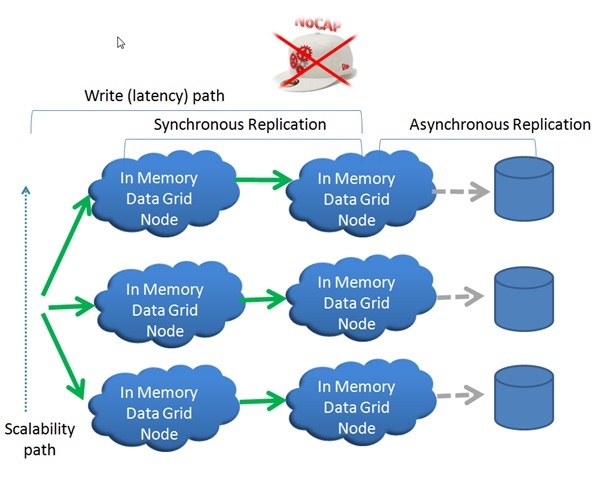
Scalability
- Data is segmented into partitions. Each partition includes a primary instance and ZERO or more backups instances. A partition (primary or a backup) hosted within a single Grid Service container.
- Data access is load-balanced across the different partitions using a routing field or a routing value specified as part of the space object or as part of the read/execute request. This allows the application to control the data distribution in a transparent manner.
- Some operations such as batch read or execute support map-reduce behavior allowing the application to access multiple partitions in parallel.
- Partition maximum size would be the Grid Service container heap size. GigaSpaces support large heap size (up to 100GB in RAM). A Grid Service container may host multiple partitions (primary or backup instances).
- A Data-Grid may have unlimited number of partitions. In reality the number of partition will be in the same magnitude as the number of Grid Service containers or servers that will be running the Data-Grid. This allows the data-grid to scale dynamically and re-balance itself across more Grid Service containers.
- The number of Data-Grid partitions is determined at the deployment time. The number of Grid Service containers hosting the Data-Grid partitions is dynamic and may change in runtime. It can scale in an elastic manner when using the ESM.
High-Availability
- Data Availability using synchronous replication to remote in-memory backups.
- Backup instances are always running on different physical machines than the ones running primary instances
- Persistency to database/disk done in a reliable Asynchronous manner.
- Once an instance of the system fails a new one recreated on-the-fly on some available machine. If the instance is primary, the existing backup turn into primary and a new backup is created.
- You can have more than a single backup copy per partition.
- Backup can be on the LAN or WAN. For remote WAN, special replication module is provided called the replication Gateway.
- Backup instances cannot be accessed by clients for write/read. This ensures total data consistency and avoids conflicts.
- Once a backup is not available the primary will log all activities (on file or overflow to disk) and send these to the backup once it will be available (send only delta). With a long disconnection total recovery of the backup will be conducted.
- Transaction boundary preserved when data is replicated from primary instance to the backup, when persisting the data or when replicating the data into remote site over the WAN (WAN Gateway).
References
NoCAP - Part II Availability and Partition tolerance
NoCAP - Part III - GigaSpaces clustering explained
GigaSpaces Clustering
See below high-level description of the GigaSpaces Clustering. It explains how load-balancing, failover , replication and high-availability works.
More details about Data-Grid clustering can be found here:
Related Topics
GigaSpaces Clustering Explained
Consistency
Consistency under concurrent updates
To ensure consistency in the case of concurrent updates on the same data record each individual record is mapped to a single logical-partition at each given point in time. To ensure scalability, different records of the same logical table are written to multiple partitions in parallel as described in the diagram above. Each partition support the various locking semantics (pessimistic, optimistic (versioning), dirty-read) etc.. to control the concurrent access of the same record within the context of a single partition.
Consistency Between two or more replicas
To ensure the continuous high availability we keep one or more copies of our data. In asynchronous replication, we may end up with scenarios where read and write operations would hit two different nodes at the same time and end up reading two separate versions of that same data. There are various algorithms that were developed to handle that situation. In our case we chose to avoid getting into that situation in the first place through the use of synchronous backup. The performance overhead of the synchronous replication is fixed and is not proportional to the size of the cluster (each partition replicates data only to its backup replica). The replication to the database is kept asynchronous to reduce the overhead of writing to disk.
Transaction Consistency
Single operations or groups of operations can be executed under transactions. This ensures the ACID properties. Transactions can be made local to each partition. In this case, they will bound to the scope of a single partition and would be highly optimized in terms of performance. Transaction can also span between nodes (in this case the overhead is obviously going to be higher).
Ordering
All operations are ordered based on the time they were written. This is specifically relevant to ensure the consistency between the in-memory cluster and the long-term storage which is being updated asynchronously.
Availability
Primary failure
GigaSpaces keep one or more replica nodes as a hot backup. The hot backup will take over immediately in case a primary node fails. The hot backup nodes uses synchronous replication to ensure no data loss before fail-over took place.
Backup failure
When a backup node fails, the primary continues to serve requests and log the operation in a redo-log. In parallel, a new backup is being provisioned on demand to take over from the failed one. That process involves a provisioning process (in which a new backup is created) and a recovery process (during which the backup gets its state).
Failure of Multiple Nodes
To increase availability, some of the NoSQL variants suggest at least three or more replicas per partition. In this way, we can handle simultaneous failure of multiple nodes. That obviously comes with a huge overhead - for each terabyte of data, we would have two terabytes of redundant information for backup purposes, and - equally important - we would also have the consistent overhead of keeping all of them up to date. An alternative approach is to use on-demand backups. On-demand backups are provisioned automatically as soon as one of the nodes fail. If spare capacity exists within the current pool of machines the backup will be provisioned into an alternate machine within the existing pool - this process can take a few seconds (depending on the amount of data per partition). If no machine is available, it will start a completely new machine. A new backup will be provisioned into that new machine. The process of starting a new machine with its backup can take few minutes. As soon the node starts it will first use a primary election protocol to find the master node within its group and only then it boots up. The startup process includes a recovery stage in which the node recovers its state from either the master node or the available replicas. The source node will also store all the updates since the recovery started in a redo log and would replay all updates to fill in the gap since the node started its recovery process.
Client Failure
Clients use a cluster-aware proxy to communicate with the cluster. The smart proxy ensures that a write or read operation is always routed to one of the available partitions. The routing happens implicitly thus the client is not exposed to a fail-over scenario.
Lookup Discovery protocol
The GigaSpaces cluster discovery mechanism is based on the Jini specification. Services use the discovery protocol to find nodes within the cluster and share cluster state amongst all nodes.
Partition Tolerance
Network partition between primary and backup
When the connection between two nodes fails, the primary node logs all the transactions into a FIFO queue known as the redo-log. As soon as the communication gets re-established all the data gets replayed to the backup. If the backup fails completely, the system will start a new instance as described above.
Network partition with the long term persistency
If the communication with the long-term persistency data store fails, the replica will log all the operations till the connection gets re-established. The log is also replicated to a backup node to ensure that the data won’t be lost in case the primary partition fails before the data was successfully committed to the long-term storage.
Network partition between two or more data center sites
Most people referred to scenarios where two sites can live in two separate locations and continue to work independently in a case of network partition as THE reference scenario for partition tolerance. It is important to note that there are two class of multi-site deployments that are fundamentally different as it relates to the network partition:
- Disaster Recovery Site - This often located in close geographical proximity to the primary site and is backed by high-bandwidth and redundant network.
- Geographically Distributed Sites over Internet WAN - In this case we have multiple sites that are spread over the globe. Unlike disaster recovery sites those sites tend to operate under lower SLA’s and significantly higher latency. The recommended approach for dealing with multi site network partition would be fairly different in each of the categories that are mentioned above:
Disaster Recovery Site
Disaster recovery sites are very much like any node in a local network but often live in different network segments and with higher latency than local networks. Nodes within a cluster can be tagged with a zones tag to mark their data-center affinity. The system can use this information to automatically provision primary and backup nodes between the two sites. It will use the zone tag to ensure that primary and backup are always spread between two data centers. Consistency & Availability - The consistency and availability mode would be just the same as LAN based deployment as described above but the performance and throughput per partition would be lower due to the higher latency associated with the synchronous replication.
- Partition Tolerance - The system will continue to function even in a case where entire site fails or become disconnected. The system will continue to work through the available site. The system will also re balance itself as soon as the communication between both sites gets re-established in order that the load will be evenly distributed between the sites.
Geographically Distributed sites over internet WAN
In this scenario, nodes are spread over internet connections where the SLAs are lower and latency is significantly higher. In that case, it would be impractical to treat all of the nodes as a single cluster as in the previous case. It would be more practical to use a federated cluster deployment (a cluster of clusters) where we will use asynchronous replication to synchronize the multiple sites and therefore avoid the extreme latency overhead. In this mode, we can’t achieve all three CAP properties. In most cases it would be more common to choose AP over CA. Having said that even when we choose AP we don’t necessarily need to give away consistency completely. Here is a suggested architecture that can provides reasonable degree of consistency with slight compromise on absolute availability and partition tolerance:
- Consistency - Each site is the sole owner of its data - i.e. all updates on the data that belong to this site needs to be delegated to this site. In more extreme scenario we can define a master site which will own all the updates to the data by all other satellite sites. In that case we can ensure consistency and read availability over write availability.
- Partition tolerance - All sites use asynchronous replication to maintain local copies of the entire data set. In a case of a network partition between the sites each site can continue to read/write its own data even when other sites are not available. It can also read other sites data but will not be able to change any data that is owned by other sites. In that context we give away some level of partition tolerance for consistency.
- Availability - Local failures are dealt with through the same model as described above. Updates on data that belong to other sites will be blocked. In that context we give away some degree of availability for consistency.
Another option to deal with consistency under concurrent updates between two sites can be based on versioning. In that case it is assumed that the latest version wins or the system will delegate the decision for resolution on conflicting updates to the application. This is a more complex scenario that goes beyond the scope of this article.
Handling Extreme Failure
Multiple node Failures at the Same Time
In cases where both the primary and backup of a given partition fails at the same time, we will consider this cluster as non-functional and block operations to that cluster until the cluster becomes functional again. In that case we will compromise on certain aspects of Availability for the sake of Consistency. If your application can tolerate the potential consistency issues associated with such failure, you could configure the cluster to route all operations to currently available partitions. In that case we will trade Availability over Consistency - this behavior can be useful in streaming scenarios where the system is used to pass through events.
If we choose to use a proper disaster recovery site setup where we ensure that primaries and their backups never run on the same site the chances for having such a failure is close to zero in the first place and can be considered equal for having the two sites down at the same time.
Recovery from a Total Failure
When the entire system crashes, it will boot itself from the long-term persistent storage or from a snapshot (new). In that case we may lose some of the data that was kept in memory and wasn’t yet delivered to the long term persistent storage. It is important to note that in a disaster recovery setup that event can happen only when both sites goes down at the same time. In that case the system would recover itself from the data that was last updated in the long-term storage.