Data Partitioning
The space can have a single instance that runs on a single JVM, or multiple instances that run on multiple JVMs. When there are multiple instances, the spaces can be set up in one of several topologies. This architecture determines how the data is distributed across the JVMs.
Available topologies:
- Replicated - data is copied to all of the JVMs in the cluster.
- Partitioned - data is distributed across all of the JVMs, each containing a different data subset. A partition is a subset of data that is distributed by a routing key.
- Partitioned with backup - data resides in a partition, and also in one or more backup space instances for this partition.
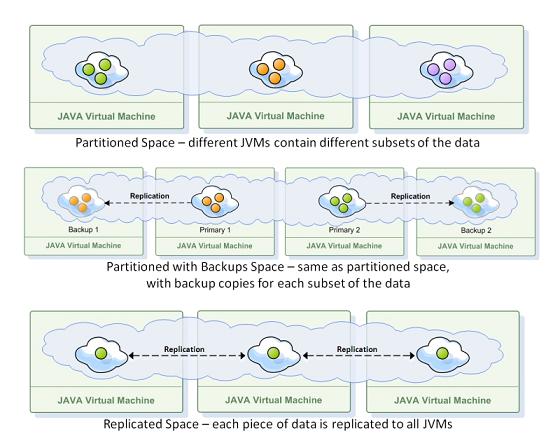
With a partitioned topology, data or operations on data are routed to one of several space instances (partitions). Each space instance holds a subset of the data, with no overlap. Business logic can be collocated within the partition to allow for fast parallel processing.
See also:
To learn more about data partitioning and load balancing, refer to Data Partitioning.