Advanced Configuration
Custom Mirror Service Name
A Mirror Service can be configured per Space cluster. You can’t have multiple Mirror services configured for the same space cluster.
If you need “multiple mirrors” for the same space cluster you can implement a Mirror Service that will route the data and operations to other multiple “agents” that will persist the data - effectively make the default Mirror act as a dispatcher.
If you have multiple different space clusters, each with its own Mirror service running, you should use a different name for each Mirror Service.
The Mirror Service name is used as part of the space config, specified via the cluster-config.mirror-service.url property. Its default is jini://*/mirror-service_container/mirror-service which match the “mirror-service” that is used as part of the url property used to start the mirror service.
As an example, let’s say we would like to call my mirror service mymirror-service (instead of the default mirror-service). Here is how the mirror service should be started:
<os-core:embedded-space id="space" space-name="myMirror-service" schema="mirror"
space-sync-endpoint="mirrorSynchronizationEndpoint" />
Here is how the space should be started:
<os-core:embedded-space id="space" space-name="mySpace" schema="persistent"
mirror="true" space-data-source="spaceDataSource">
<os-core:properties>
<props>
<prop key="cluster-config.mirror-service.url">
jini://*/mymirror-service_container/mymirror-service
</prop>
</props>
</os-core:properties>
</os-core:space>
Implementing a Custom Mirror Data Source
XAP has a built in Hibernate Space Persistency implementation which is a SpaceSynchronizationEndpoint extension. You can implement your own Mirror very easily to accommodate your exact needs. See example below:
package mypackage;
public class MirrorSpaceSynchronizationEndpoint extends SpaceSynchronizationEndpoint {
private String parameter;
public void setParameter(String parameter) {
this.parameter = parameter;
}
@Override
public void onOperationsBatchSynchronization(OperationsBatchData batchData) {
for (DataSyncOperation operation : batchData.getBatchDataItems()) {
switch (operation.getDataSyncOperationType()) {
case WRITE:
// new entry has been written
break;
case UPDATE:
// entry was updated
break;
case REMOVE:
// entry was removed
break;
case CHANGE:
// entry was modified using change API
break;
}
}
}
}
And here is how this can be configured within the mirror configuration:
<bean id="mirrorSpaceSynchronizationEndpoint" class="mypackage.MirrorSpaceSynchronizationEndpoint">
<property name="parameter" value="some value"/>
</bean>
<os-core:embedded-space id="space" space-name="mirror-service" schema="mirror"
space-sync-endpoint="mirrorSpaceSynchronizationEndpoint" />
<bean id="mirrorSpaceSynchronizationEndpoint" class="mypackage.MirrorSpaceSynchronizationEndpoint">
<property name="parameter" value="some value"/>
</bean>
<bean id="space" class="org.openspaces.core.space.EmbeddedSpaceFactoryBean">
<property name="name" value="mirror-service" />
<property name="schema" value="mirror" />
<property name="spaceSyncEndpoint" ref="mirrorSpaceSynchronizationEndpoint" />
</bean>
In order to use the data source as the read mechanism for the cluster Space that connects to the mirror, a SpaceDataSource extension needs to be implemented.
Throwing java.lang.RuntimeException from the onTransactionSynchronization or onOperationsBatchSynchronization methods of the SpaceSynchronizationEndpoint implementation will signal the primary to keep the replicated data within its redo log and retry the replication operation. Your code should support this in case it fails (for example database transaction failure).
Multiple Mirrors
In some cases you may need to asynchronously persist data both into a relational database and a file, or persist the data into a relational database and transfer some of the data into some other system.
In such a case you may need to have multiple mirrors. In order to implement this, you should have one base mirror (for example the Hibernate Space Persistency) and extend it to include the extra functionality you may need.
See the Mirror Monitor for a simple example how such approach should be implemented.
There are cases with large space clusters or with systems that produce large volume of activity where the amount of activity performed by a clustered space would require a distributed (multi-instance) mirror setup.
See the Distributed Mirror for an example how to configure this scenario.
Handling Mirror Exceptions
Since the space synchronization endpoint configured for the mirror service communicates with the database, it may run into database related errors, such as constraint violations, wrong class mappings (if the Hibernate-based space synchronization endpoint implementation is used), or other database-related errors.
By default, these errors are propagated to the replicating space (primary space instance), and will appear in its logs. In such a case, the primary space will try to replicate the batch the caused the error to the mirror service again, until it succeeds (meaning that no exception has been exposed to the user’s application code).
To override and extend this behavior, you can implement an exception handler that will be called when an exception is thrown from the Mirror back to the primary space. This exception handler can log the exception at the mirror side, throw it back to the space, ignore it or execute any user specific code. Here is an example of how this is done using the org.openspaces.persistency.patterns.SpaceSynchronizationEndpointExceptionHandler provided with OpenSpaces:
<bean id="hibernateSpaceSynchronizationEndpoint"
class="org.openspaces.persistency.hibernate.DefaultHibernateSpaceSynchronizationEndpointFactoryBean">
<property name="sessionFactory" ref="sessionFactory"/>
</bean>
<bean id="exceptionHandler" class="eg.MyExceptionHandler"/>
<bean id="exceptionHandlingSpaceSynchronizationEndpoint"
class="org.openspaces.persistency.patterns.SpaceSynchronizationEndpointExceptionHandler">
<constructor-arg ref="hibernateSpaceSynchronizationEndpoint"/>
<constructor-arg ref="exceptionHandler"/>
</bean>
<os-core:embedded-space id="space" space-name="mirror-service" schema="mirror"
space-sync-endpoint="exceptionHandlingSpaceSynchronizationEndpoint"/>
With the above, we use the SpaceSynchronizationEndpointExceptionHandler, and wrap the DefaultHibernateSpaceSynchronizationEndpoint with it (and pass that to the space). On the SpaceSynchronizationEndpointExceptionHandler, we set our own implementation of the ExceptionHandler, to be called when there is an exception. With the ExceptionHandler you can decide what to do with the Exception: “swallow it”, execute some logic, or re-throw it.
A configured mirror will repeatedly try to store things in the DB. In the case on unrecoverable failure (imagine an invalid mapping or a constraint issue), this can cause the redo log to grow, eventually resulting in overflow of the redo to disk, and then, when the predefined disk capacity is exhausted, leading to a rejection of any non-read space operation (similar to how the memory manager works). The exception that clients will see in this case is RedologCapacityExceededException (which inherits from ResourceCapacityExceededException).
The application can handle this by using the ExceptionHandler at the mirror EDS level. It can count the number of consecutive failures returned from the DB and when a certain threshold is reached, log it somewhere and move on, for example.
That said, the easiest thing to do is test your persistence in the mirror.
Mirror Behavior with Distributed Transactions
When using the Distributed Transaction Manager and persisting data through the mirror service, each partition sends its transaction data to the Mirror on commit. The mirror service receives the replication messages in bulk from each partition that participated in the transaction. In order to keep database data consistent when persisting the data, these bulks should to be consolidated at the mirror service.
This can be achieved by :
- Setting the following property in the mirror configuration:
<os-core:embedded-space id="space" space-name="mirror-service" schema="mirror" space-sync-endpoint="spaceSynchronizationEndpoint">
<os-core:properties>
<props>
<prop key="space-config.mirror-service.operation-grouping">
group-by-space-transaction
</prop>
</props>
</os-core:properties>
</os-core:embedded-space>
By default this property is set to group-by-replication-bulk and executeBulk() groups several transactions and executes them together. The group size is defined by the mirror replication bulk-size.
Setting this property will cause a SpaceSynchronizationEndpoint.onTransactionSynchronization invocation for each transaction separately.
Getting the Transaction Metadata
The following demonstrates how the transaction metadata can be retrieved:
public class MySpaceSynchronizationEndpoint extends SpaceSynchronizationEndpoint {
public void onTransactionSynchronization(TransactionData transactionData) {
TransactionParticipantMetaData metaData = transactionData.getTransactionParticipantMetaData();
int participantId = metaData.getParticipantId();
int participantsCount = metaData.getTransactionParticipantsCount();
TransactionUniqueId transactionId = metaData.getTransactionUniqueId();
// ...
}
}
Notes:
onOperationsBatchSynchronization()/onTransactionSynchronizationare called concurrently, so implementations should take concurrency into consideration.- Non-transactional operations are grouped according to the replication policy (
bulk-sizeandinterval-millis) and sent to the Mirror Service. - Transactional and non-transactional items are not mixed.
Starting with XAP 9.0.1 a new transaction participant meta data interface has been introduced. The new interface describing the transaction’s unique id which consists of the transaction’s id and the transaction manager id who have created it:
/**
* Represents a transaction meta data for a specific transaction participant.
* @since 9.0.1
*/
public interface TransactionParticipantMetaData {
/**
* The id of the space that committed the transaction.
* @return the participantId
*/
public int getParticipantId();
/**
* Number of participants in the transaction
* @return the participantsCount
*/
public int getTransactionParticipantsCount();
/**
* The id of the transaction
* @return the transactionId
*/
public TransactionUniqueId getTransactionUniqueId();
}
/**
* Represents a transaction unique id constructed from the transaction manager which created the transaction
* Uuid and the transaction id.
* @since 9.0.1
*/
public interface TransactionUniqueId
{
/**
* @return The transaction manager which created the transaction {@link Uuid}.
*/
Uuid getTransactionManagerId();
/**
* @return The transaction id.
*/
Object getTransactionId();
}
Mirror Distributed Transaction Consolidation - Atomic Transaction Delegation
Once a the entire distributed transaction content arriving from each data grid partition participating in the transaction into the mirror to be persist, you may consolidate it to perform one database transaction rather several separate database transactions. This keeps the database data consistent and reduce database overhead.
Distributed transaction consolidation is configured via the space configuration using the cluster-config.groups.group.repl-policy.processing-type property.
In the following example we configure a space using its pu.xml to have transaction consolidation mode as enabled:
Since 9.1.0 - Distributed transaction consolidation is enabled by default.
<os-core:embedded-space id="space" space-name="mySpace">
<os-core:properties>
<props>
<prop key="cluster-config.groups.group.repl-policy.processing-type">
multi-source
</prop>
</props>
</os-core:properties>
</os-core:embedded-space>
As specified in the example above, it is required to set the cluster-config.groups.group.repl-policy.processing-type property to multi-source.
The cluster-config.groups.group.repl-policy.processing-type may have the following values:
global-order- Do not maintain any ordering. Mirror consolidation is not executed.multi-source- Maintain ordering per partition. Transaction consolidation is executed.
In order to take advantage of this feature, mirror operation grouping should be set to group-by-space-transaction in mirror pu.xml:
<os-core:embedded-space id="space" space-name="mirror-service"
schema="mirror" space-sync-endpoint="spaceSynchronizationEndpoint">
<os-core:properties>
<props>
<prop key="space-config.mirror-service.operation-grouping">
group-by-space-transaction
</prop>
</props>
</os-core:properties>
</os-core:embedded-space>
Distributed Transaction Consolidation Example:
public class MySpaceSynchronizationEndpoint extends SpaceSynchronizationEndpoint {
@Override
public void onTransactionSynchronization(TransactionData transactionData) {
if (transactionData.isConsolidated()) {
// this is a consolidated distributed transaction...
ConsolidatedDistributedTransactionMetaData metaData = transactionData.getConsolidatedDistributedTransactionMetaData();
}
}
@Override
public void onTransactionConsolidationFailure(ConsolidationParticipantData participantData) {
// intercept transaction consolidation failure & decide whether to commit or abort this participant data
if (sunnyDay)
participantData.commit();
else
participantData.abort();
}
}
With the above example the ‘participantData.commit()` call assumes the logic accepting each transaction participant data to be persist separately despite a failure with the transaction consolidation. ‘participantData.abort()’ indicates the logic must have all transaction participant’s data to be fully consolidated.
Distributed transaction consolidation is done by waiting for all the transaction participants’ data to arrive the mirror from all relevant data grid partitions before processed by the mirror and persisting into the database.
In some cases certain distributed transaction participants data might be delayed due-to network delay or disconnection and therefore may cause delays in replication into the mirror. In order to prevent this delay, you may set a timeout parameter that indicates how much time the mirror will wait the for distributed transactions participants data to arrive before processing the data individually for each participant.
Please note that while waiting for a distributed transaction to entirely arrive the mirror, replication isn’t waiting but keeping the data flow and preventing from conflicts to happen.
The following example demonstrates how to set the timeout for waiting for distributed transaction data to arrive, it is also possible to set the amount of new operations to perform before processing data individually for each participant:
<os-core:embedded-space id="space" space-name="mirror-service" schema="mirror" space-sync-endpoint="spaceSynchronizationEndpoint">
<os-core:properties>
<props>
<prop key="space-config.mirror-service.operation-grouping">
group-by-space-transaction
</prop>
<prop key="space-config.mirror-service.distributed-transaction-processing.wait-timeout">120000</prop>
<prop key="space-config.mirror-service.distributed-transaction-processing.wait-for-operations">100</prop>
</props>
</os-core:properties>
</os-core:embedded-space>
Distributed transaction participants’ data will be processed individually if ten seconds have passed and all of the participants data has not arrived or if 20 new operations were executed after the distributed transaction.
| Attribute | Default Value |
|---|---|
| space-config.mirror-service.distributed-transaction-processing.wait-timeout | 60000 milliseconds |
| space-config.mirror-service.distributed-transaction-processing.wait-for-operations | unlimited (-1 = unlimited) |
Note that by setting the cluster-config.groups.group.repl-policy.processing-type property to multi-source all reliable asynchronous replication targets for that space will work in distributed transaction consolidation mode (For example: Gateway Sink).
Setting both dist-tx-wait-timeout-millis and dist-tx-wait-for-opers to unlimited (or very high value) is risky and may cause replication backlog accumulation due to a packet which is unconsolidated and waits for consolidation which may never occur due to various reasons.
Usage Scenarios
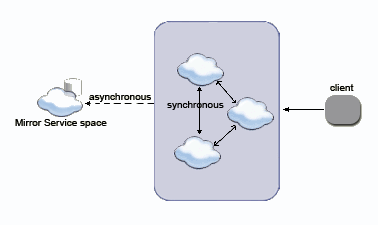
Writing Synchronously to the Mirror Data Source
The following is a schematic flow of a synchronous replicated cluster with three members, which are communicating with a Mirror Service:
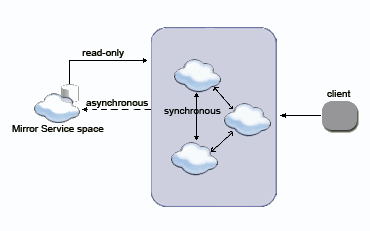
Reading from the Data Source
The Mirror Service space is used to asynchronously persist data into the data source. As noted elsewhere, the Mirror is not a regular space, and should not be interacted with directly. Thus, data can’t be read from the data source using the Mirror Service space. Nonetheless, the data might be read by other spaces which are configured with a space data source.
The data-grid pu.xml needs to be configured to use an space data source which, when dealing with a Mirror, is central to the cluster.
Here is a schematic flow of how a Mirror Service asynchronously receives data, to persist into an data source, while the cluster is reading data directly from the data source.
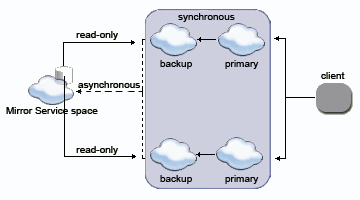
Partitioning Over a Central Mirror Data Source
When partitioning data, each partition asynchronously replicates data into the Mirror Service. Each partition can read back data that belongs to it (according to the load-balancing policy defined).
Here is a schematic flow of how two partitions (each a primary-backup pair) asynchronously interact with a data source:
Considerations and Known Issues
- The Mirror Service cannot be used with a single space. It is supported with the
async-replicated, andpartitionedcluster schemas. - The Mirror Service is a single space which joins a replication group. The Mirror Service is not a clustered space or part of the replication group declaration.
- When the Mirror Service is loaded, it does not perform memory recovery. See the reliability section for more details.
- Transient Entries are not persisted into the data source, just as in any other persistent mode.
- You should have one Mirror Service running per Data-Grid cluster.
- The Mirror Service cannot be clustered. Deploying it as a Processing unit ensures its high-availability.
- The Mirror does not load data back into the space. The
SpaceDataSourceimplementation of the space should be used to initialize the space when started.
Space persistency considerations also apply to the Mirror Service.
Troubleshooting
Log Messages
The space persistency logging level can be modified as part of the <XAP Root>\config\log\xap_logging.properties file. By default, it is set to java.util.logging.Level.INFO:
com.gigaspaces.persistent.level = INFO
Logging is divided according to java.util.logging.Level as follows:
| Level | Description |
|---|---|
| INFO | The default level for informative messages. |
| CONFIG | Mirror Service-relevant configuration messages. |
| FINER | Fairly detailed messages of: - Entering and exiting interface methods (displaying the parameter’s toString() method) - Throwing of exceptions between the space and the underlying implementation. |
Failover Handling
This section describes how the GigaSpaces Mirror Service handles different failure scenarios. The following table lists the services involved, and how the failure is handled in the cluster.
Active services are green , while failed services are red .
| Active/Failed Services | Cluster Behavior |
|---|---|
| * Primary
- Backup - Mirror - Database |
* The primary and backup spaces, each include a copy of the mirror replication queue (which is created in the backup, as part of the synchronized replication between the primary and the backup). - The mirror doesn’t acknowledge the replication until the data is successfully committed to the database. - Every time the primary gets an acknowledgment from the mirror, it notifies the backup of the last exact point in the replication queue where replication to the mirror was successful. - This way, the primary and backup space include the same copy of the data and are also in sync with whatever data was replicated to the mirror and written to the database. |
| * Primary
- Backup - Mirror - Database |
* The backup space holds all the information in-memory, since the replication channel between them is synchronous. - The backup space is constantly notified of the last exact point in the replication queue where replication to the mirror was successful. This means that it knows specifically when the failure occurred. Therefore, it replicates the data received from that point onwards, to the mirror. - One possible scenario is that the same Entry is sent to the mirror, both by the primary and the backup space. However, the mirror handles this situation, so no data is lost or duplicated. - If the primary space is restarted (typically by the Service Grid infrastructure), it recovers all of the data from the backup space. Once the primary has retrieved all data from the backup, it continues replicating as usual. No data is lost. |
| * Primary
- Backup - Mirror - Database |
* The primary keeps functioning as before: replicating data to the mirror and persisting data asynchronously, so no data is lost. - The primary space is constantly notified of the last exact point in the replication queue where replication to the mirror was successful. This means that it knows specifically when the failure occurred. Therefore, it replicates the data received from that point onwards to the mirror. - One possible scenario is that the same Entry is sent to the mirror both by the primary and the backup space. However, the mirror handles this situation, so no data is lost or duplicated. - If the backup space is restarted (typically by the Service Grid infrastructure), it recovers all of the data from the primary space. Once the backup has retrieved all data from the primary, it continues replicating as usual. No data is lost. |
| * Primary
- Back Up - Mirror - Database |
* The primary and backup spaces accumulate the Entries and replicate them to their mirror replication queue (which is highly available since they both share it). - When the mirror is restarted, replication is resumed from the point it was stopped, prior to the failure. No data is lost. |
| * Primary
- Backup - Mirror - Database |
* The primary space is constantly synchronized with the mirror, which stops sending acknowledgments or starts sending errors to it. - The primary and backup spaces accumulate the Entries and replicate them to their mirror replication queue (which is highly available since they both share it). - When the database is restarted, the mirror reconnects to it and persistency is resumed from the point it was stopped, prior to the failure. No data is lost. |
Unlikely Failure Scenarios
The following failure scenarios are highly unlikely. However, it might be useful to understand how such scenarios are handled by GigaSpaces. This is detailed in the table below.
Active services are green , while failed services are red .
| Active/Failed Services | Cluster Behavior |
|---|---|
| * Primary
- Backup - Mirror - Database |
* Data which has already been saved in the database is safe. - Data held in the mirror replication queue still exists in the backup, so no data is lost. |
| * Primary
- Backup - Mirror - Database |
* Data which has already been saved in the database is safe. - Data held in the mirror replication queue still exists in the backup, so no data is lost. |
| * Primary
- Backup - Mirror - Database |
Same as above – no data is lost. |
| * Primary
- Backup - Mirror - Database |
Same as above – no data is lost. |
| * Primary
- Backup - Mirror - Database |
* Data which has already been saved in the database is safe. - Data queued in the mirror replication queue still exists in the primary and the backup, so no data is lost. |
| * Primary
- Backup - Mirror - Database |
* All data that was successfully replicated to the mirror (and hence persisted to the database) is safe. - Data queued in the mirror replication queue in the primary and backup spaces is lost. - If you encounter this scenario, a configuration with two backups per partition should be considered. |