Synchronous Replication
In a synchronous replication, the client receives acknowledgement for any replicated operations only after all the space instances in the replication group have performed the operation. This topology is most fitting for the Primary backup topology, where the application needs a guarantee that during a failure of the primary space instance, no already executed operations or saved data will be lost. As a result, this replication type has the highest performance penalty because each operation is not completed until all the target space instances in the group have received and acknowledge the operation.
How to Turn on Synchronous Replication?
In general you should have the cluster-config.groups.group.repl-policy.replication-mode property set to sync. See below example:
<os-core:embedded-space id="space" space-name="mySpace">
<os-core:properties>
<props>
<prop key="cluster-config.groups.group.repl-policy.replication-mode">sync</prop>
</props>
</os-core:properties>
</os-core:embedded-space>
When to Use Synchronous Replication
Synchronous replication is most beneficial in the following scenarios:
- Whenever an application must replicate highly sensitive, mission critical data as soon as it arrives at the source space.
- Whenever any space operation must be duplicated with 100% data integrity to the target space.
How Synchronous Replication Works
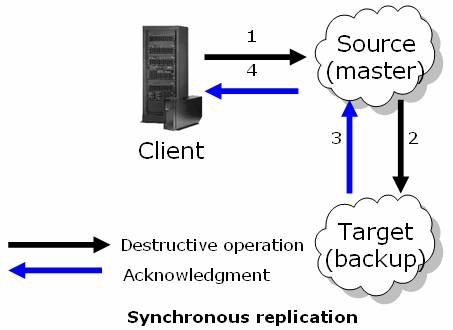
- A destructive space operation is called.
The source space:
- Performs the operation.
- Replicates the operation to all the targets and wait for acknowledgement from the targets.
The target space receives a replication packet:
- Makes sure parallel operations are processed in the correct order.
Once the replication packet is processed, the target space sends a confirmation to the source space.
The source space sends acknowledgement to the client.
Handling Disconnections and Errors
When a replication target space instance is unavailable (disconnection) or some error occurred during the processing of the replication data at the target, a synchronous replication channel (between the source and the specific target space instance) moves to asynchronous operating state. During that time, all the replicated operations are accumulated at a backlog (named replication redolog) and a special worker attempts to replicate the items from the redolog to the target space instance in batches. This worker will succeed sending the accumulated replication data once the connection is re-established or the error is resolved at the target and once the redolog is replicated, the channel will return to synchronous operation state. During the asynchronous operating state time period, the client will receive acknowledgements for the operations without them being replicated, thus not halting the cluster when a replication target is down.
The current operating mode of a replication channel can be retrieved via the Administration and Monitoring API by getting the Space Instance Replication Statistics of the specific replication channel and calling the following getter OutgoingChannel.getOperatingMode()
Behavior During Recovery
In the previous scenario, a target space instance might become unavailable because it has been restarted or relocated due to various reason (failure, manual/automatic relocation). In the default settings, when that target space instance will restart, it will perform a recovery from a source space instance. In primary backup topology it will be the primary space instance, in active active topology it can be any space instance. During the recovery process the replication channel will operate in asynchronous state until the redolog is replicated as in the above scenario. The target space instance will not be available until the source channel operating state was restored to synchronous, thus making sure that once the target space is available and visible, a backup or other space instance target is fully synchronized with its source.
Throttling
When a synchronous replication channel is operating in asynchronous state, a special throttling takes place that will throttle the replicated operation rate to make sure two things:
- Once the target is reachable or the error is resolved, the redolog increase rate will be lower than the asynchronous replication completion. That is to make sure the asynchronous state will end at a finite time.
- In order to try and maintain a consistent throughput so that the application will not gain a dramatic performance boost because the replication is disconnected, and have more operation at risk.
This throttling can be configured with the following parameters:
| Property | Description | Default Value |
|---|---|---|
| cluster-config.groups.group.repl-policy.sync-replication.throttle-when-inactive | Boolean value. Set to true if you want to throttle replicated operations when the channel is in-active (disconnection) |
true in primary backup false in full sync replicated |
| cluster-config.groups.group.repl-policy.sync-replication.max-throttle-tp-when-inactive | Integer value. If the above is true, this will specify the maximum operations per second the throttle will maintain when the channel is in-active (disconnection), if the last measured throughput when the channel was active was higher than that, the measured throughput will be used instead. | 50,000 operations/second |
To change the default replication settings you should modify the space properties when deployed. You may set these properties via the pu.xml or programmatically. Here is an example how you can set the replication parameters when using the pu.xml:
<os-core:embedded-space id="space" space-name="mySpace">
<os-core:properties>
<props>
<prop key="cluster-config.groups.group.repl-policy.sync-replication.throttle-when-inactive">false</prop>
</props>
</os-core:properties>
</os-core:embedded-space>
Asynchronous Operating State Related Configuration
While the replication channel is operating at asynchronous state due to the reasons mentioned above, the worker that sends the data from the redolog asynchronously is affected by the following configuration (which also relates to asynchronous replication):
| Property | Description | Default Value |
|---|---|---|
| cluster-config.groups.group.repl-policy.async-replication.repl-chunk-size | Number of packets that are replicated as a single chuck each time. | 500 |
| cluster-config.groups.group.repl-policy.async-replication.repl-interval-millis | Time (in milliseconds) to wait from last replication iteration if there are no more packets to replicate (while disconnected) or if the last iteration was not successful due to error | 3000 [ms] |
Splitting Replication of Large Batches into Smaller Batches
When performing batch operations (writeMultiple, takeMultiple, clear), using a synchronous replication mode , the actual data (space objects/UID) is replicated to the target spaces in batches during the single space operation. This is done in order to avoid to issues, one of them is to run out of memory due to all the data that is generated in the redolog for the replication or cause the redolog capacity limitation being breached. For example, when performing the take (clear) operation, you don’t necessarily know how many space objects exist in the space, and all of these need to be removed. Therefore, these operations are split into several chunks, thus providing better memory usage, stability, and scalability.
Splitting large batches into chunks is defined using the cluster-config.groups.group.repl-policy.sync-replication.multiple-opers-chunk-size parameter. This parameter default value is 10000. This means that by default the operation is performed using chunks of 10000 objects each. To split the replication activity into smaller chunks, you can do so by overriding this property, for instance, using the pu configuration file.
<os-core:embedded-space id="space" space-name="mySpace">
<os-core:properties>
<props>
<prop key="cluster-config.groups.group.repl-policy.sync-replication.multiple-opers-chunk-size">5000</prop>
</props>
</os-core:properties>
</os-core:embedded-space>
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
<section name="GigaSpaces" type="GigaSpaces.Core.Configuration.GigaSpacesCoreConfiguration, GigaSpaces.Core"/>
</configSections>
<GigaSpaces>
<SystemProperties>
<add Name="cluster-config.groups.group.repl-policy.sync-replication.multiple-opers-chunk-size" Value="5000"/>
</SystemProperties>
</GigaSpaces>
</configuration>
Splitting large batches into smaller chunks is not supported for transactional operations.