Step 1 - Adjusting Your JPA Domain Model to XAP
Before You Begin
We recommend that you do the following before starting this step of the Tutorial:
Make yourself familiar with the JPA specification and OpenJPA.
Read this page to learn about moving to a distributed data model
Working with JPA
JPA stands for Java Persistence API. This API was created in order to standardize Object - Relational Mapping APIs, saving the developer the pain of learning specific implementations APIs If you are not familiar with JPA, it highly recommended making yourself acquainted with it (This would be a good place to start) . GigaSpaces’ JPA support is built on top of is actually an adapter layer between the JPA and JPQL APIs and the OpenSpaces API and XAP services.
GigaSpaces XAP JPA
While GigaSpaces JPA supports a large portion of the JPA standard, there are limitations and differences that are caused by the nature of XAP’s distributed implementation.
Embedded Relationships Only
GigaSpaces XAP only manages embedded relationships between entities. That means that the JPA API layer will not manage automatically any relationships based on keys. The application code will have to take care of maintaining such relationships. While JPA @OneToMany and @OneToOne annotations will be interpreted by XAP as owned (embedded) relationships, the @ManyToMany cannot be mapped into an embedded model and therefore is not supported (it will simply be ignored).
Another important point to note is using JOIN queries; Since JOINs are actually done on embedded objects and obviously in the same memory partition, JOIN has no special toll on performance as long as you define the right indexes.
Other Limitations
There are some other limitations to GigaSpaces JPA, most notably:
- Non-String auto generated Ids - At this point, cluster wide unique IDs of types other than
java.lang.Stringwill not be automatically generated by JPA. We will later show how to generate cluster wide unique IDs for the application. - Native queries - the current JPA implementation does not support native OpenSpaces queries (it will be supported in XAP 8.0.1).
- Lazy loading - the JPA layer can only read the entire object graph in full. It cannot read parts of the object graph. We will see how the PetClinic application deals with it by running the JPA code in the same JVM as the space using Space Based Remoting
- JPQL outer joins are also not supported. For the complete list of limitation please refer to this page
The Application Modules
The original Pet Clinic application is packaged as a single WAR file and deployed on a single JVM. The Spring MVC front end of the application is using a DAO object (Clinic) to access the data. The DAO hides the usage of JPA from the web layer. With XAP we want to make the application scalable at all layers, therefore we will split the application into 3 modules:
- The Web module, which does not change from the original PetClinic implementation. It uses the same Spring MVC architecture and implementation and will use the same DAO interface to access the data. However, this module will be deployed on to the GigaSpaces runtime environment as a Web Processing Unit. In doing so, we ensure that no matter how large the traffic of the application will be; the application will be able to serve it by scaling out and adding more instances of the web application as the load increases. It will also be able to scale in by shutting them down when load decreases.
- The Processor module. This module is where the data tier resides. It holds the entire application data set, partitioned over several JVMs. The data is collocated with the DAO JPA implementation in order to access and manipulate the data locally. So each JVM contains an instance of the DAO implementation, which operates only on the local data set, providing in-memory speeds. Using the Space infrastructure, the web module transparently invokes some or all of those instances, depending on the use case. This ensures the scalability of your business logic and data layers. The data layer can scale up by rebalancing the partitions over additional resources according to the load. Collocating the business logic with application’s data eliminates the use of physical I/O and significantly speeds up the application. In addition, each primary partition can be synchronized with one or more backup partitions to ensure high availability. The number of partitions and their backups is external to the application’s code, and can be changed at deployment time.
- The common module is actually just a build unit with the classes shared between the web module and the processor module. In contains the domain model classes and the Clinic DAO interface definition. It is part of both web and processor deployments units.
Another way to look at the above modules is to compare them to a database client calling stored procedures on the database. However, with XAP, the entire scenario is written in java, using JPA, and is deployed on to a single, unified platform. In order for the web application to access the remote interface, we need to add a configuration file, exposing the Clinic DAO instances across the data grid cluster as a remote service to the web application. You can learn more about XAP Remoting services here
The Application Data Model
Now let’s review the considerations and changes in the application data model when accommodating it for partitioned deployment. The application domain model class diagram is depicted in the following diagram:
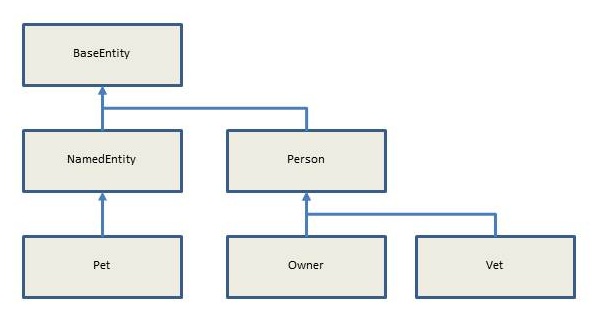
And here’s how the entities are related to one another:
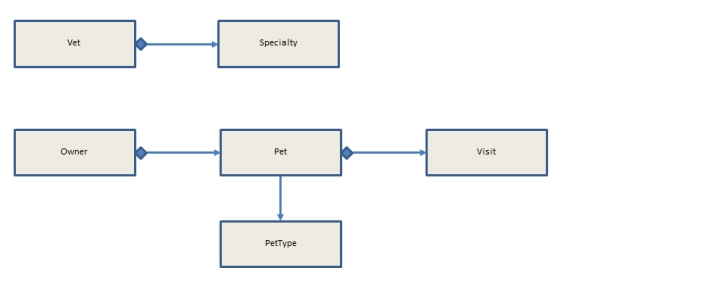
As you can see the application’s data model assumes the following relationships:
- Each vet has one or more specialties (one to many)
- Each owner has one or more pets (one to many)
- Each pet has one pet type (one to one)
- Each pet has one or more visits (one to many)
Distributing the Data
TO distribute the data, the first thing we want to decide is how to partition this data. As we don’t have here any association between Vet and Visit or Vet and Pet, it is rather an easy task. We should partition the Vets independently of all other entities, and we should partition the Owners, Pets and Visit in a manner that each Owner will be located on the same partition with her pets and their visits.
There are 2 remaining types here, however, that can cause a problem: PetType and Specialty. Both of these types have one to many relationships with Vet and Pet respectively. So we need to duplicate them or manage the relationship in code and risk non-scalable scenarios since the same PetType can be referenced by multiple Pets, potentially residing in different partitions.
Since in this example the PetType and vet’s Specialty are final by nature, we overcome this problem by using embedded Enums. This enables the partitioning and also has minimal footprint, as Enums are static (following the Flightweight design pattern).
Had we needed to support an open set of PetTypes or vet Specialties, we would have needed to duplicate this information across all partitions for the sake of performance and scalability
As for the Pet and Visit entities - since each of them is only reference by a single entity type: Visit by Pet and Pet by Owner, we can use embedded relationships.
Preparing the Entities for XAP
In order to use these entities with XAP we need to introduce the following changes to them:
- JPA annotations should be placed on getters and not on attributes
- When JPA’s
@Idor@EmbededIdare used, add@SpaceIdannotation. Use the autoGenerate = false since the IDs will be generate by another service as explained below - When a JPA’s
@Transientis used, you must add@SpaceExcludeannotation - Use
@OneToOneand@OneToManyand not@Embeddablealthough it’s an embedded relationship - Use
CascadeType.ALLwith all relationships - Add
@SpaceRoutingto the appropriate getters to control the partitioning of your data model. In our example this annotation is placed on theBaseEntity.getId()method. If we don’t put this annotation explicitly, XAP JPA will use the@SpaceIdmember as default space routing key. - It is recommended to use Java’s primitive wrappers rather than primitives for entity properties. We don’t recommend using primitives when storing classes to the spaces as a specific null value needs to be specified for them. This is more error prone.
- Add indexes to you data using
@SpaceIndex. In thePetClinicapplication queries search forOwnerby last name so it makes sense to index thegetLastName()method in thePersonbase type. You can also index properties of entities contained in collections; for example, we have indexed theOwner. getPetsInternal()method. When indexing a property of an entity in a collection, you need to specify it name. In this example thePetcollection is indexed based on the Pet’s Id property and therefore the indexing path is “[*].id”. The ability to index collection of complex objects is a new and powerful features of XAP 8.0
@SpaceIndex(path = "[*].id", type = SpaceIndexType.BASIC)
@OneToMany(cascade = CascadeType.ALL)
protected Set<Pet> getPetsInternal() {
if (this.pets == null) {
this.pets = new HashSet<Pet>();
}
return this.pets;
}
What’s Next?
Step Two - Implementing the PetClinic Data Access Layer - Shows how to utilize XAP’s unique capabilities to implement the data access layer in a scalable manner.