Asynchronous Persistency - Write Behind
The XAP Mirror Service provides reliable asynchronous persistency. This allows you to asynchronously delegate the operations conducted with the In-Memory-Data-Grid (IMDG) into a backend database, significantly reducing the performance overhead.
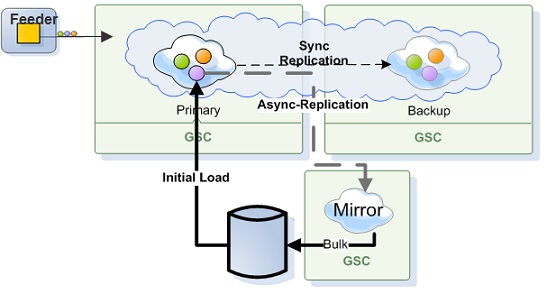
The Mirror service ensures that data will not be lost in the event of a failure. This way, you can add persistency to your application just by running the Mirror Service, without touching the real-time portion of your application in either configuration or code. This service provides fine-grained control of which object needs to be persisted.
The mirror does need a backup since it does not hold any state. The actual state of the latest committed database transaction stored within the primary and the backup space instances, not in the Mirror. Essentially, the Mirror acts as a dispatcher and push the changes done at the space (all primary partitions) into the Database (or any other data source) in an asynchronous reliable manner. In case of a failure of the Mirror, it will be restarted automatically and the primary instances will playback the un-committed transactions while the Mirror was down. The Mirror PU (like any deployed service) is mobile. It can run on any machine running a GSC, so the GSM will pick one of the existing GSCs to provision the missing Mirror PU.
If from some reason the SLA you applied forcing the Mirror PU to run on a specific machine that is unavailable (for example on a specific zone which does not have any running containers), the primary and backup will hold the transaction data within their redo log queue in memory. In some point they will store it on file until the Mirror machine will be restarted.
You should not deploy the mirror in clustered mode nor have multiple instances of it. It should have a single instance as part of its SLA configuration.
Enabling the Mirror Service involves the following:
- The Data-Grid Processing Unit Mirror Settings
- The Mirror Service Processing Unit Settings
The above share the same Space Persistency settings but have different space settings. See the NHibernate Space Persistency for details how to use the built-in HibernateExternalDataSource.
The Data-Grid Processing Unit
The cluster-config.mirror-service space settings specify the interaction between the IMDG primary spaces and the Mirror Service. The mirror="true" space element tag enables the replication mechanism from the IMDG Primary spaces to the Mirror Service. Once the mirror="true" is specified, all IMDG members will be Mirror aware and will be delegating their activities into the Mirror service. The IMDG primary instance will replicate the operations that have been logged within the primary redo log every interval-millis amount of time or interval-opers amount of operations. Both of these mechanisms are always active and the first one that is breached triggers the replication event.
If you are not using the mirror="true" with the Data-Grid PU, you should use the following property instead:
cluster-config.mirror-service.enabled=true
The IMDG Mirror replication settings includes the following options:
| Property | Description | Default |
|---|---|---|
| cluster-config.mirror-service.url | used to locate the Mirror Service. In case you change the name of the Mirror Service specified as part of the Mirror PU, you should modify this parameter value to facilitate the correct Mirror service URL. | jini://*/mirror-service_container/mirror-service |
| cluster-config.mirror-service.bulk-size | The amount of operations to be transmitted in one bulk (in quantity and not actual memory size) from an active IMDG primary to the Mirror Service. | 100 |
| cluster-config.mirror-service.interval-millis | The replication frequency - Replication will happen every interval-millis milliseconds |
2000 |
| cluster-config.mirror-service.interval-opers | The replication buffer size - Replication will happen every interval-opers operations. |
100 |
| cluster-config.groups.group.repl-policy.repl-original-state | The replication reconciliation mode - This settings should be enabled to ensure that write/take operations or multiple updates for the same space object will be sent to the mirror and not will be discarded when sent within the same batch. | true |
| cluster-config.mirror-service.on-redo-log-capacity-exceeded | Available options: block-operations - all cluster operations that need to be replicated (write/update/take) are blocked until the redo log size decreases below the capacity. (Users get RedoLogCapacityExceededException exceptions while trying to execute these operations.) drop-oldest - the oldest packet in the redo log is dropped. See the Controlling the Replication Redo Log for details. |
block-operations |
| cluster-config.mirror-service.redo-log-capacity | Specifies the total capacity of replication packets the redo log can hold for a mirror service replication target. See the Controlling the Replication Redo Log for details. |
1000000 |
| cluster-config.groups.group.repl-policy.async-replication.async-channel-shutdown-timeout | Determines how long (in ms) the primary space will wait before replicating all existing redo log data into its targets before shutting down. | 300000 ms |
The Mirror Service may receive replication events from multiple active primary partitions. Each active partition sends its operations to the Mirror service via a dedicated replication channel. The Mirror handles incoming replication requests simultaneously. Every Primary Space sending its operations to the Mirror Service in the same order the operations have been executed allowing the Mirror preserve the consistency of the data within the data source.
<ProcessingUnit>
<EmbeddedSpaces>
<add Name="space" Mirrored="true">
<ExternalDataSource Type="GigaSpaces.Practices.ExternalDataSource.NHibernate.NHibernateExternalDataSource"
Usage="ReadOnly">
<!-- NHibernate-specific config goes here -->
</ExternalDataSource>
<Properties>
<!-- Use ALL IN CACHE - No Read Performed from the database in lazy manner-->
<add Name="space-config.engine.cache_policy" Value="1"/>
<add Name="cluster-config.cache-loader.external-data-source" Value="true"/>
<add Name="cluster-config.cache-loader.central-data-source" Value="true"/>
<add Name="cluster-config.mirror-service.url" Value="jini://*/mirror-service_container/mirror-service"/>
<add Name="cluster-config.mirror-service.bulk-size" Value="100"/>
<add Name="cluster-config.mirror-service.interval-millis" Value="2000"/>
<add Name="cluster-config.mirror-service.interval-opers" Value="100"/>
<add Name="cluster-config.groups.group.repl-policy.repl-original-state" Value="true"/>
</Properties>
</add>
</EmbeddedSpaces>
</ProcessingUnit>
The above example:
- Configures the Space to connect to its mirror Space. By default, it will lookup a mirror Space called
mirror-service. - Configures the Space to only read data from the data source. This means that all destructive operations will be delegated into the database via the Mirror service.
- Configures the Data-Grid to use a data source that is central to the cluster. This means that both primary and backup IMDG instances will interact with the same data source.
See the Space Persistency Properties and the NHibernate Space Persistency for full details about the EDS properties the you may configure.
You must use a Data-Grid cluster schema that includes a backup (i.e. partitioned) when running a Mirror Service. Without having backup, the Primary IMDG Spaces will not replicate their activities to the Mirror Service. For testing purposes, in case you don’t want to start backup spaces, you can use the partitioned cluster schema and have 0 as the number of backups - this will still allow the primary spaces to replicate their operations to the Mirror.
If you wish to change the mirror service name please refer to Async Persistency - Mirror - Advanced.
Enabling replication into the mirror without starting the Mirror will generate a backlog within the primary space (and backup). Please avoid running in this configuration.
The Mirror Processing Unit
The Mirror Service is constructed using the Mirrors tag. The Mirror Service itself is not a regular Space. It is dispatching the operations which have been replicated from the IMDG primary spaces to the data source (i.e. Database). The Mirror Service should be constructed as a separate processing unit, which includes only its definition.
The Mirror settings includes the following options:
| Property | Description | Default |
|---|---|---|
| OperationGrouping | Options: group-by-space-transaction - Mirror delegating each transaction separately to the data source (database). group-by-replication-bulk - Mirror delegating all replicated items as one bulk to the data source (database). See the Mirror behavior with Distributed Transactions for details |
group-by-replication-bulk |
| SourceSpace Name | The name of source space (cluster) this mirror serves | NONE, must be supplied |
| SourceSpace Partitions | The number of partitions in source space (cluster) this mirror serves | NONE, must be supplied |
| SourceSpace Backups | The number of backups per partition in source space (cluster) this mirror serves | NONE, must be supplied |
The following configuration shows how to configure a processing unit, to act as the Mirror Service:
<ProcessingUnit>
<Mirrors>
<add Name="mirror-service" OperationGrouping="group-by-replication-bulk">
<SourceSpace Name="mySpace" Partitions="2" Backups="1"/>
<ExternalDataSource Type="GigaSpaces.Practices.ExternalDataSource.NHibernate.NHibernateExternalDataSource">
<!-- NHibernate-specific config goes here -->
</ExternalDataSource>
</add>
</Mirrors>
</ProcessingUnit>
- The above configuration constructs a Mirror Service using GigaSpaces built-in NHibernate Space Persistency.
- The name of the Mirror Space is important. The
mirror-serviceis the default name for a mirror Space, which is then used by the IMDG to connect to its mirror. - The configuration above should exist within the mirror PU
pu.configfile.
Mirror Undeploy
When cluster is un deployed, the mirror service must be un deployed last. This will ensure that all data is persisted properly through mirror async persistency. Before primary space is un deployed/redeployed, all data changes are flushed to mirror. This operation is limited by timeout that can be configured using the following property:
<!-- default value is 5 minutes -->
<add Name="cluster-config.groups.group.repl-policy.async-replication.async-channel-shutdown-timeout" Value="300000"/>
Optimizing the Mirror Activity
The database update rate by the Mirror is a function of the number of IMDG partitions, database update speed with a single thread, database transaction size, network latency between the Mirror and the Database, hibernate overhead (if hibernate is being used as the persistence mechanism), relevant table indexed columns, and the database record size. Also, when distributed transactions are used with the IMDG, this may improve the database update rate (since multiple partitions will be sending their updates to the Mirror, which can batch all cumulative updates to the database), but this will impact the IMDG transaction latency.
You might want to tune the IMDG and the Mirror activity to push data into the database faster. Here are some recommendations you should consider:
- Optimize the Space Class structure to include fewer fields. Less fields means less overhead when the IMDG replicates the data to the Mirror Service.
- Tune the
bulk-size,interval-millisandinterval-opersto perform the replication in larger batches and less frequently. This means you should increase thebulk-size,interval-millisandinterval-opersto have larger values than the defaults. The exact values depends with the network speed, the average size of the objects and the database configuration and machine speed. Here is an example for a configuration that is relevant for IMDG with relatively small objects (less than one K) and high rate of operations (more than 10,000 operations per second for partition):
<add Name="cluster-config.mirror-service.bulk-size" Value="10000"/>
<add Name="cluster-config.mirror-service.interval-millis" Value="5000"/>
<add Name="cluster-config.mirror-service.interval-opers" Value="50000"/>
With the above configuration the primary partition will replicate its redo log activities to the Mirror service every 5 seconds or every 50,000 operations. The replication will occur in batches of 10,000 objects per batch.
- Tune the data source to commit data into the database in batches.
- Optimize the database transaction support.
- Implement a Mirror Service that will write the incoming data into a CSV file. This should be faster than writing data into the database. Later import the data into the database. (normally very fast operation)
- Increase the database maximum connections.
- Optimize Hibernate mapping and configuration. Using a proper Hibernate ID generator is crucial for getting optimum performance.
- Use PARTIAL_UPDATE (see Partial Update). Updates to an object that are performed using the PARTIAL_UPDATE modifier can be executed on the mirror as partial update as well. This can increase the performance in case a lot of updates are performed on a large object. To use this optimization you need to set the following space property:
<add Name="cluster-config.mirror-service.supports-partial-update" Value="true"/>
Mirror Monitoring
The activity of the mirror service can be monitored using the Administration and monitoring API. This API exposes statistics on operations that were executed by the mirror and can be used to monitor the mirror throughput and health status.
You may view Mirror and its replication statistics via the GigaSpaces Management Center. Move into the Space Browser tab, click the top tree Spaces icon, right click the table columns title area on the right panel, select the columns you would to view as part of the table and click OK.
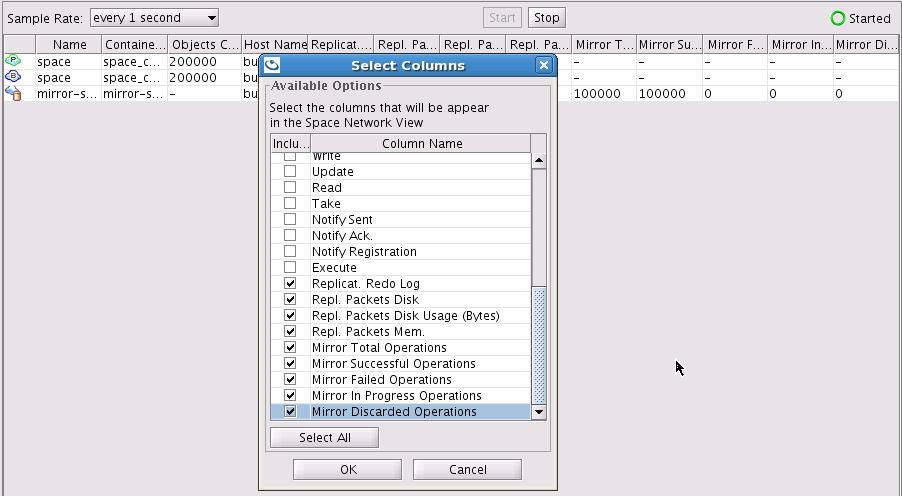
See also the Mirror Monitor JMX utility for graphical mirror service monitoring via JMX