Consistency Biased
In this mode the Active Election process requires that a quorum of Zookeeper nodes, each space instance is elected as primary/backup according to the Zookeeper right image.
Dependencies
In order to use this feature, include the ${XAP_HOME}/lib/platform/zookeeper/xap-zookeeper.jar file on your classpath or use maven dependencies:
<dependency>
<groupId>com.gigaspaces</groupId>
<artifactId>xap-zookeeper</artifactId>
<version>12.0.1</version>
</dependency>
For more information on dependencies see Maven Artifacts
What is Zookeeper?
ZooKeeper is a distributed, hierarchical file system that facilitates loose coupling between clients and provides an eventually consistent view of its znodes, which are like files and directories in a traditional file system. It provides basic operations such as creating, deleting, and checking existence of znodes, also It provides an event-driven model in which clients can watch for changes to specific znodes. ZooKeeper achieves high availability by running multiple ZooKeeper servers, called an ensemble, with each server holding an in-memory copy of the distributed file system to service client read requests. Each server also holds a persistent copy on disk.
ZooKeeper is already used by Apache HBase, HDFS, and other Apache Hadoop projects to provide highly-available services.
Zookeeper leader selector
XAP is using Apache Curator leader selector recipe which implements a distributed lock with notifications mechanism using Zookeeper.
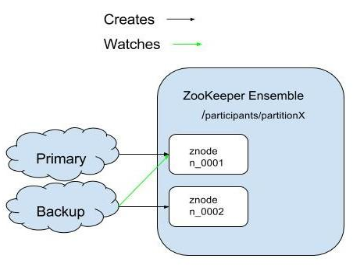
- A znode, say “/participants/partitionX”
- All participants of the election process create an ephemeral-sequential node on the same election path.
- The node with the smallest sequence number is the leader.
- Each “follower” node listens to the node with the next lower seq number.
- Upon leader removal go to election path and find a new leader, or become the leader if it has the lowest sequence number.
- Upon session expiration (disconnection) check the election state and go to election if needed, in case of disconnection the primary space instance is moved to Quiese mode and will be restarted.
Configuration
The first step is to configure and run Zookeeper servers.
Then add to your pu.xml the following leader-selector configuration:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:os-core="http://www.openspaces.org/schema/core"
xmlns:leader-selector="http://www.openspaces.org/schema/zookeeper"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.1.xsd
http://www.openspaces.org/schema/core http://www.openspaces.org/schema/12.0/core/openspaces-core.xsd
http://www.openspaces.org/schema/zookeeper http://www.openspaces.org/schema/12.0/zookeeper/openspaces-zookeeper.xsd">
<leader-selector:zookeeper id="zookeeper"/>
<os-core:embedded-space id="space" name="mySpace">
<os-core:leader-selector ref="zookeeper"/>
</os-core:embedded-space>
<os-core:giga-space id="gigaSpace" space="space" />
</beans>
| Property | Description | Default | Use |
|---|---|---|---|
| curator connection timeout. | 15000 millisecond | optional | |
| session-timeout | curator session timeout | 10000 millisecond | optional |
| session-timeout | curator session timeout | 10000 millisecond | optional |
| retries | curator number of retries. Operations on a ZooKeeper cluster can fail. Best practices dictate that these operations should be retried. Curator has a Retry Loop mechanism. | 10 | optional |
| curator sleep between retrie | 1000 millisecond | optional |
Partition Split-Brain
Zookeeper leader selector avoids split-brain instances, through quorum, If the primary is not in the majority, that primary is frozen(or Quiesce) until the network is connected and the frozen primary is terminated automatically.