Big Data
In this part of the tutorial will introduce you to XAP’s Big Data interface. Will show you how you can use Cassandra and other Big-Data storage systems to archive data or use them for space persistence.
Archive Container
The archive container is used to transfer historical data into Big-Data storage. The typical scenario is when streaming vast number of raw events through the Space, enriching them and then moving them to a Big-Data storage. Typically, there is no intention of keeping them in the space nor querying them in the space.
- The Archive Container automatically moves objects from the Space to the Big-Data storage.
- The Archive Container configures the set of objects to be archived.
- The Archive Container supports Space fail-over, and Big-Data storage unavailability.
- The persisted objects, can then be read by 3rd party tools directly from the Big-Data storage.
- Big-Data storage is abstracted with the interface.
The Archive Container differs from Space Persistency in the following ways:
- Persisted objects are not read back from the Big-Data storage into the Space.
- Objects are persisted from multiple partitions in parallel directly to the Big-Data storage (not going through the Space Persistency).
- Archive Container uses the Polling Container behind the scenes, which can be co-located with each space partition.
Cassandra Integration
The Apache Cassandra Project™ is a scalable multi-master database with no single points of failure. The Apache Cassandra Project provides a highly scalable second-generation distributed database, bringing together Dynamo’s fully distributed design and Bigtable’s ColumnFamily-based data model.
XAP provides out of the box support for Cassandra and uses the Hector Library to communicate with the Cassandra cluster. Lets take our online payment system; every transaction that is performed in our application creates an Audit Record. Each one of these records will be persisted in Cassandra for future auditing reviews. First, lets defining the archive container:

......
xmlns:os-archive="http://www.openspaces.org/schema/archive"
........
http://www.openspaces.org/schema/archive http://www.openspaces.org/schema/10.1/archive/openspaces-archive.xsd">
<!-- Enable scan for OpenSpaces and Spring components -->
<context:component-scan base-package="xap.tutorial.cassandra" />
<!-- Enable support for @Archive annotation -->
<os-archive:annotation-support />
<!-- Register the Space Type ---->
<os-core:embedded-space id="space" name="auditSpace">
<os-core:space-type type-name="AuditRecord">
<os-core:id property="id" />
<os-core:routing property="id" />
</os-core:space-type>
</os-core:embedded-space>
<os-core:distributed-tx-manager id="transactionManager" />
<os-core:giga-space id="auditSpace" space="space" tx-manager="transactionManager" />
<os-archive:cassandra-archive-handler
id="cassandraArchiveHandler" giga-space="auditSpace" hosts="127.0.0.1"
port="9160" keyspace="audit" write-consistency="QUORUM" />
And here is the actual polling container definition:
@Archive(batchSize = 100)
public class AuditArchiveContainer {
@DynamicEventTemplate
public SQLQuery<SpaceDocument> getTemplate() {
final SQLQuery<SpaceDocument> dynamicTemplate =
new SQLQuery<SpaceDocument>("AuditRecord", "");
return dynamicTemplate;
}
}
The example above removes 100(takeMultiple) AuditRecord objects from space at a time and writes them into Cassandra. The archive operation is performed on the bean that implements the ArchiveOpertaionHandler interface, in this case the CassandraArchiveOperationHandler bean.
Only Space Documents are supported for the event template. You can still write POJOs to the space, but the
@EventTemplate used for taking objects from the space must be a SpaceDocument.Attribute Mapping
By default when serializing object/document properties to column values, the following serialization logic is applied:
- If the type of the value to be serialized matches a primitive type in Cassandra it will be serialized as defined by the Cassandra primitive type serialization protocol.
- Otherwise, the value will be serialized using standard java Object serialization mechanism.
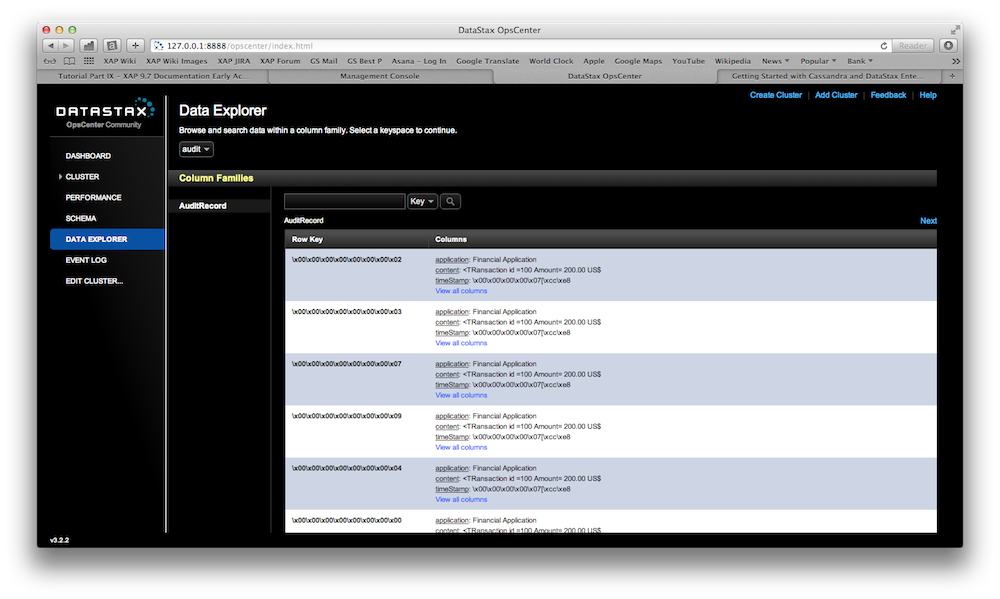
Lets look at an example how the default attribute mapping works. We have Audit Records we want to persist in Cassandra:
package xap.tutorial.audit.model;
import com.gigaspaces.document.SpaceDocument;
public class AuditRecord extends SpaceDocument {
private static final String TYPE_NAME = "AuditRecord";
private static final String ID = "id";
private static final String TIMESTAMP = "timeStamp";
private static final String USERNAME = "userName";
private static final String APPLICATION = "application";
private static final String CONTENT = "content";
public AuditRecord() {
super(TYPE_NAME);
}
public Long getId() {
return super.getProperty(ID);
}
public void setId(Long id) {
super.setProperty(ID, id);
}
public Long getTimeStamp() {
return super.getProperty(TIMESTAMP);
}
public void setTimeStamp(Long timeStamp) {
super.setProperty(TIMESTAMP, timeStamp);
}
public String getApplication() {
return super.getProperty(APPLICATION);
}
public void setApplication(String application) {
super.setProperty(APPLICATION, application);
}
public String getAuditContent() {
return super.getProperty(CONTENT);
}
public void setAuditContent(String auditContent) {
super.setProperty(CONTENT, auditContent);
}
public String getUserName() {
return super.getProperty(USERNAME);
}
public void setUserName(String userName) {
super.setProperty(USERNAME, userName);
}
}
When one of these objects is persisted in Cassandra, the following default column mapping is performed:
| Property | Column Name (and type) |
| auditRecord.id | (row key) (type: Long) |
| auditRecord.timeStamp | timeStamp (type: Long) |
| auditRecord.application | application (type: UTF8) |
| auditRecord.auditContent | auditContent(type: UTF8) |
| auditRecord.userName | userName (type: UTF8) |
The attributes will be mapped to the AuditRecord column family in Cassandra. Notice that the embedded class User was flattened and its properties are flattened as columns.
It is possible to override this default behavior by providing a custom implementation.
Learn moreDeploying an example
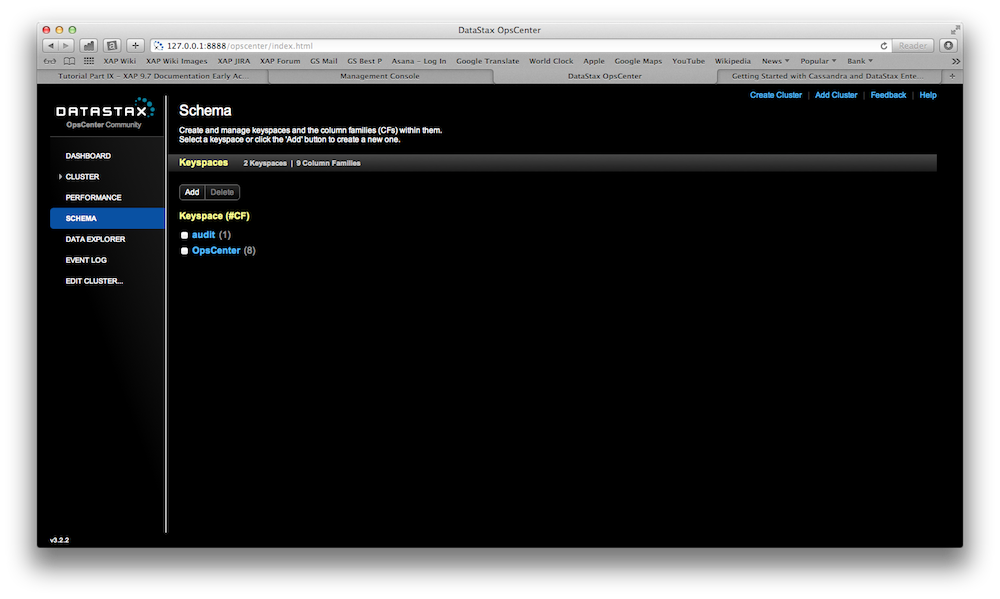
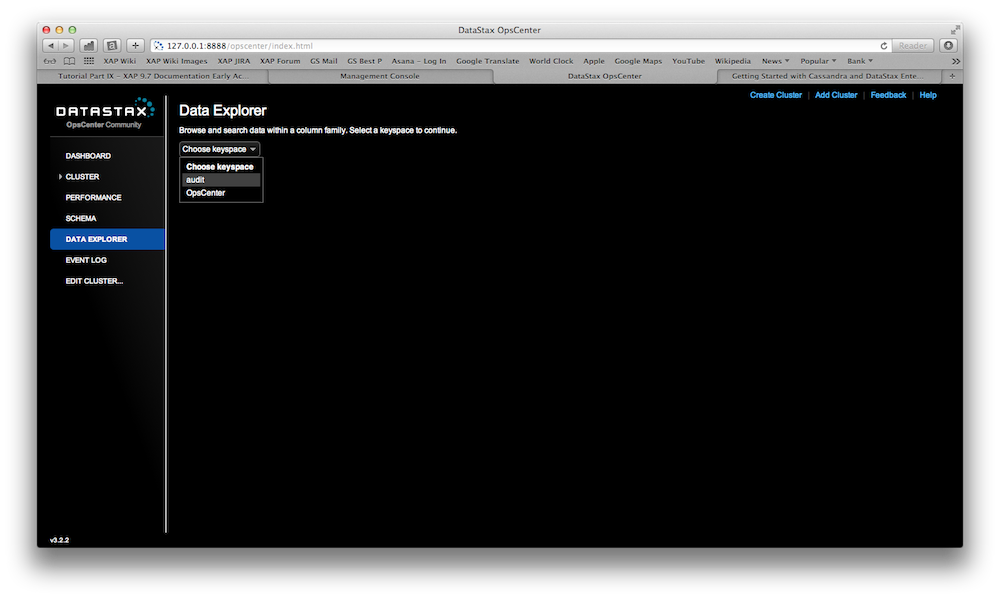
There is a fully working example on GitHub. You can download, build and execute it. Here are the steps how you would deploy it and inspect XAP and Cassandra using the OpsCenter.
Try it out
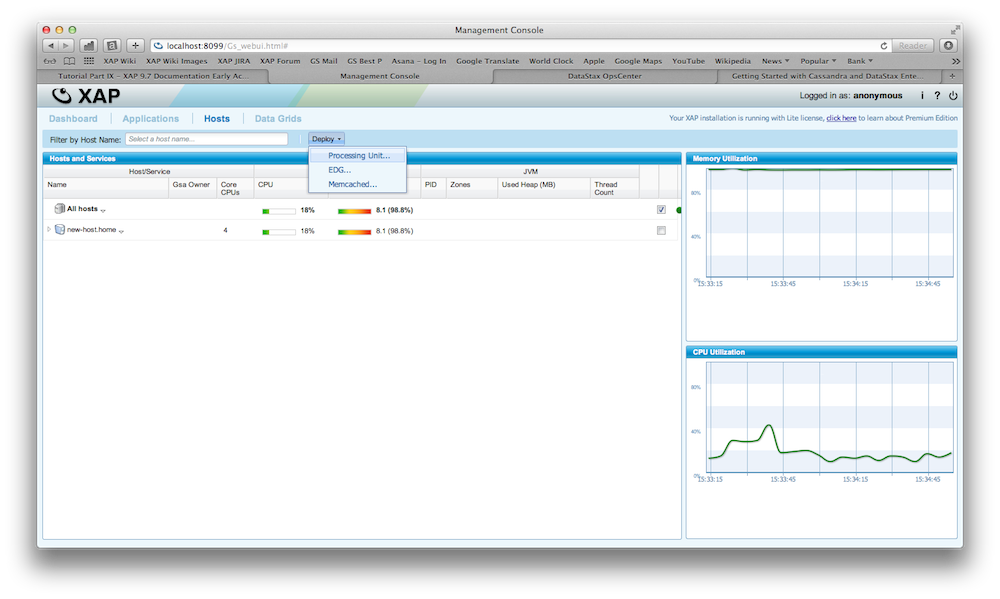
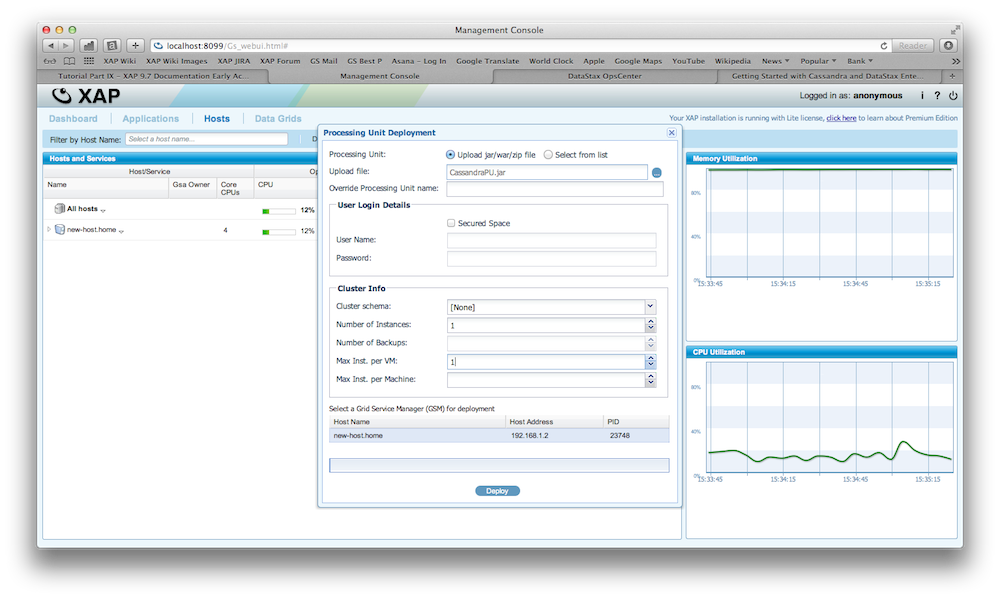
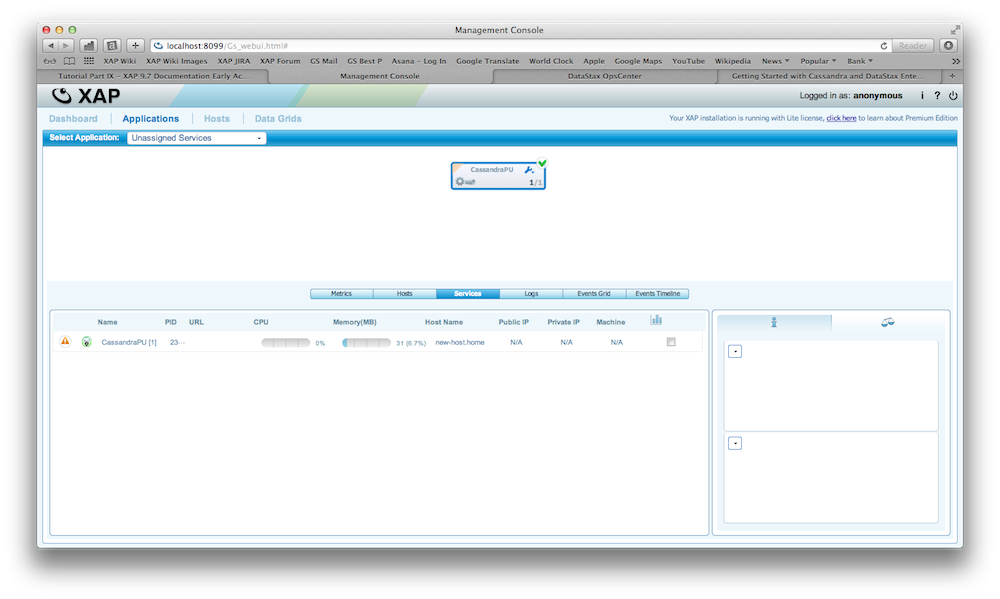
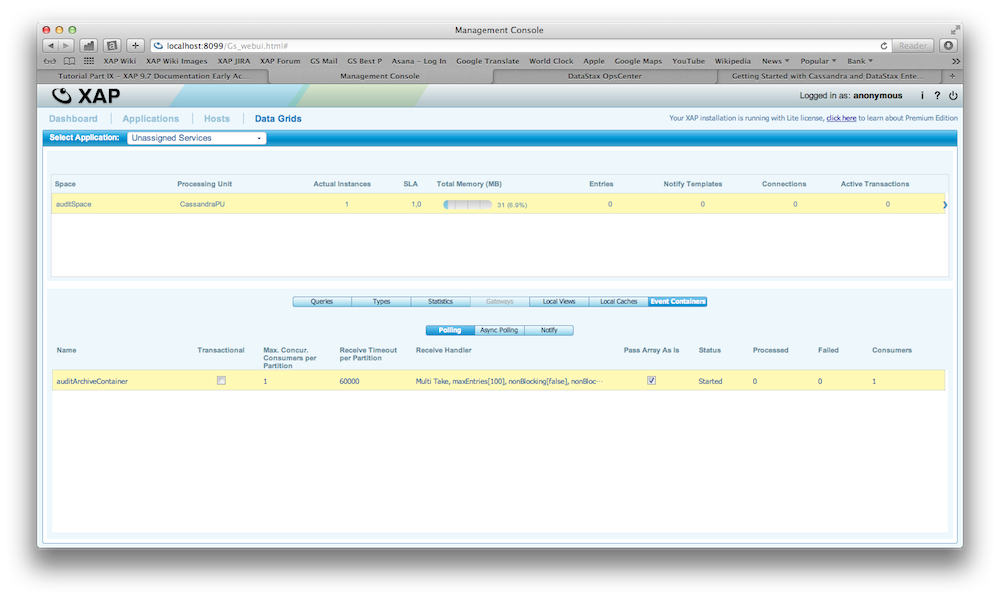

Write your own Archive Container
You can implement your own Archive Container to use your NoSQL backend or RDBMS for storing your information. Your class just needs to implement the ArchiveOperationHandler interface.
Space Persistency
The XAP Mirror Service provides reliable asynchronous persistency. This allows you to asynchronously delegate the operations conducted with the In-Memory-Data-Grid (IMDG) into a backend database, significantly reducing the performance overhead. XAP comes with built in implementations of Space Data Source and Space Synchronization Endpoint for Cassandra, called CassandraSpaceDataSource and CassandraSpaceSynchronizationEndpoint, respectively.

Mongo Integration
XAP provides out of the box support for the MongoDB.
Learn more