Deterministic Deployment
When a deploying a data grid, primary and backup instances will be provisioned in an arbitrary manner across the available machines running GSA/GSCs. You don’t have a control where these will be physically located as the primary election mechanism determines the primary and backup instances location at the deploy time (first instance per partition elected as the primary).
In some cases you would like to determine the primary and backup instances location in an explicit manner. A simple approach would be to use zones, having one specific zone to host the primary instances and another zone to host the backup instances. These zones do not determine specific physical machines to host the primary/backup instances, but logical group of GSCs associated with a specific zone once started. Usually, the zone might reflect machines located in specific different racks or different data centers that are nearby having very fast and reliable connectivity in between.
When Deterministic Deployment should be used?
The Primary-Backup Zone Controller approach intended to be used with read mostly scenarios (80% read) where the latency between the sites is extremely low (below one-two milliseconds) with high bandwidth capacity.
Having primary and backup instances on different remote sites that are far away from each other is not a recommended approach with read/write applications. In this case primary and backup instances should be located within the same LAN with high speed connectivity and high capacity bandwidth to allow the primary replicate data as fast as it can to the backup to minimize the replication overhead on the application behavior.
When there is a requirement to leverage remote sites for disaster recovery or remote clients access - most systems will have their data grid primary and backup instances (using synchronous replication mode) within the same LAN (Master data grid) with another grid and its data-grid (not sharing the same lookup service and GSM with the master data grid) running as a slave data grid where the WAN Replication Gateway used to replicate data between the Master and Slave Data-Grid asynchronously. With multi-master architecture the WAN Replication Gateway may run a conflict resolver to handle concurrent updates of the same object in both sites.
Controlling Primary/Backup Location
The Primary-Backup Zone Controller used with Deterministic Deployment should be deployed with the data grid PU. It allows you to specify a specific zone for primary instances and a different zone for backup instances. Once the Primary-Backup Zone Controller deployed/started it relocates all the primary instances into GSCs associated with the primary zone and later relocates all the backup instances into GSCs associated with the backup zone. The Primary-Backup Zone Controller periodically checks the status of the deployed data grid and relocates relevant instances as needed.
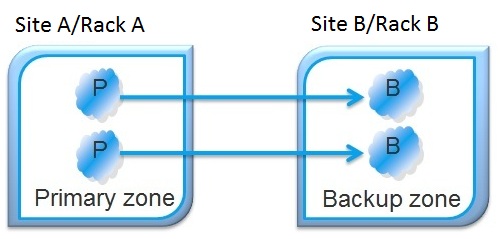
Example
This example deploys a partitioned data grid with two partitions and a backup where Zone A hosting primary instances:
sla.xml
<os-sla:sla cluster-schema="partitioned-sync2backup"
number-of-instances="2" number-of-backups="1" max-instances-per-zone="A/1,B/1"
primary-zone="A">
<os-sla:requirements >
<os-sla:zone name="A"/>
<os-sla:zone name="B"/>
</os-sla:requirements>
</os-sla:sla>
pu.xml
Add the following snippet to your PU.
<bean id="primaryZoneController" class="org.openspaces.pu.sla.PrimaryZoneController" >
<property name="primaryZone" value="A" />
</bean>
Setup the zones
Define two zones (zone1,zone2) need to be defined:
Start Zone A
set GSC_JAVA_OPTIONS=-Dcom.gs.zones="A"
gs-agent gsa.gsc 2 gsa.lus 0 gsa.gsm 0
export GSC_JAVA_OPTIONS=-Dcom.gs.zones="A"
./gs-agent.sh gsa.gsc 2 gsa.lus 0 gsa.gsm 0
Start Zone B
set GSC_JAVA_OPTIONS=-Dcom.gs.zones="B"
gs-agent gsa.gsc 2 gsa.lus 0 gsa.gsm 0
export GSC_JAVA_OPTIONS=-Dcom.gs.zones="B"
./gs-agent.sh gsa.gsc 2 gsa.lus 0 gsa.gsm 0
Deploy the PU
Deploy your PU from CLI or UI. See CLI example.
When deployed all primary instances will be allocated in zone A and backups in zone B. If primary fails the order will be restored by using restart.
Multiple primary zones
Several primary zones can be specified:
primary-zone="A,C,D"
Primary instances will be provisioned in the configured order - A,C,D.
Limitations
- Deterministic deployment supports only clusters with singe backup (X,1).
- Deterministic deployment requires to set max-instances-per-zone to 1.
In the above example: max-instances-per-zone=“A/1,B/1.