Topologies
Different applications might have different caching requirements. Some applications require on-demand loading from an external, slower data source, due to limited memory; others use the cache for read-mostly purposes; transactional applications need a cache that handles both write and read operations, maintains consistency and serves as the application’s system of record.
In order to address these different requirements, GigaSpaces provides an in-memory data grid that is policy-driven. Most of the policies do not affect the actual application code, but rather affect the way each data grid instance interacts with other instances.
This section explains the topologies supported by XAP - replicated, partitioned and master-local.
GigaSpaces Data Grid - Basic Terms
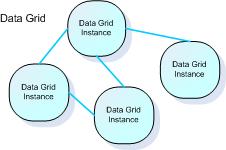
- Space (data grid) instance - an independent data storage unit. The Space is comprised of all the space instances running on the network.
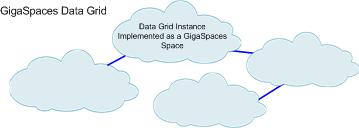
- Space - GigaSpaces data grid implementation. A distributed, shared, memory-based repository for objects. A space runs in a space container - this is usually transparent to the developer.
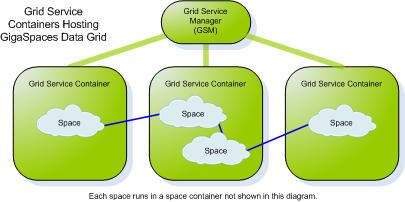
- GigaSpaces Container (GSC) - a generic container that can run one or more processing units. A space instances usually runs within processing unit. The GSC is launched on each machine that participates in the space cluster, and hosts the space instances.
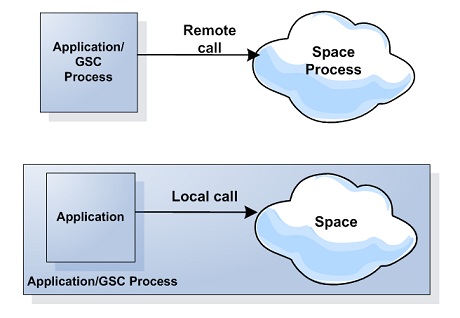
- Replication - a relationship in which data is copied between two or more space instances, with the aim of having the same data in some or all of them.

Synchronous replication - replication scheme in which space client applications are blocked until their changes are propagated to all peer spaces. This guarantees higher data consistency between space instances, at the expense of reduced performance since clients have to wait for the replication to complete before the operation is finished.
Asynchronous replication - replication mode in which changes are propagated to peer space instances in the background, using separate thread(s) that are used to receive the write request from the clients. Applications clients do not have to wait for their changes to be propagated to other space instances. With asynchronous replication the client does not block until all the data has been replicated, and the space can optimize the replication by batching multiple updates into a single network call. Therefore this options performs better and allows for higher throughput. On the other hand, data is less consistent between space instances and takes longer to get propagated.
Partitioning - new data or operations on data are routed to one of several space instances (partitions). Each space instance holds a subset of the data, with no overlap. Partitioning is done according to n routing field in the data object. Each object written to the space defines a routing field whose value is used to determine the partition to which the object will be sent. The space client side proxy guarantees that if two object have the same value set for the routing field they will end up in the same partition, regardless o how many partitions are running.

- Topology - a specific configuration of space instances. For example, a replicated topology is a configuration in which all space instances replicate data between one another. In GigaSpaces, space topologies are defined by clustering policies (explained in the following section).
Replication Configuration For more details on how to configure the replication mechanisms of the Space, please refer to this page in the Administrator’s Guide.
Data Grid Topologies
GigaSpaces XAP supports the following data grid topologies:
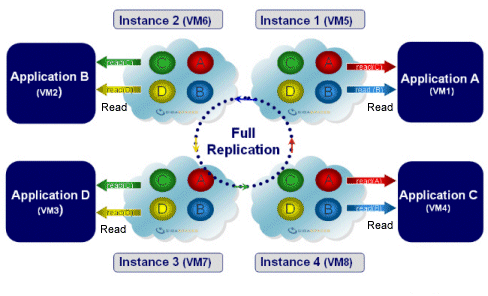
Replicated
| Description | Two or more space instances with replication between them. |
|---|---|
| Common Use | Allowing two or more applications to work with their own dedicated data store, while working on the same data as the other applications. Also allows for load distribution between multiple space instances in read-intensive scenarios |
| Options | Replication can be synchronous (slower but with better consistency) or asynchronous (faster but less reliable, as it does not guarantee consistency and immediate replication). Space instances can run on the same JVM as the application (embedded - allows faster read access) or in a separate process (remote - allows multiple applications to use the space, easier management). |
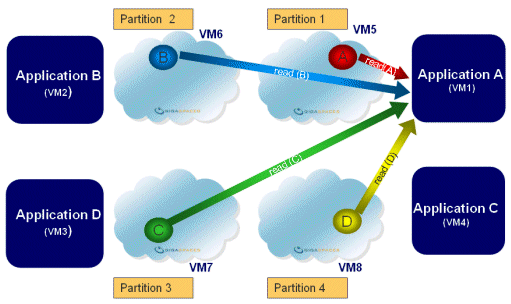
Partitioned
| Description | Data and operations are split between two or more space instances (partitions) according to a routing field defined in the data. | |
|---|---|---|
| Common Use | Allows the In-Memory Data Grid to hold large volumes of data, even if it is larger than the memory of a single machine, by splitting the data across several partitions. | |
| Options | With/without backup space instance for each partition. - Business logic can be collocated with each partition and act on the data of the local partition. This is one of the principles of the SBA paradigm |
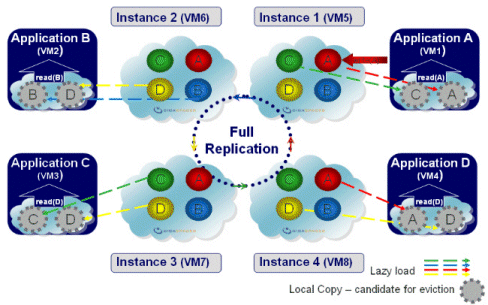
Local Cache
| Description | Each client has a lightweight, embedded cache (space instance), which is initially empty. Upon the first time data is read, it is loaded from a master space to the local cache (this is called lazy loading); the next time the same data is read, it is fetched quickly from the local cache without network access. Later on data is either updated from the master or evicted from the cache. |
|---|---|
| Common Use | Boosting read performance for frequently used data. A useful rule of thumb is to use a local cache when over 80% of all operations are repetitive read operations. |
| Options | The master cache can be clustered in any of the other topologies: replicated, partitioned, etc. |
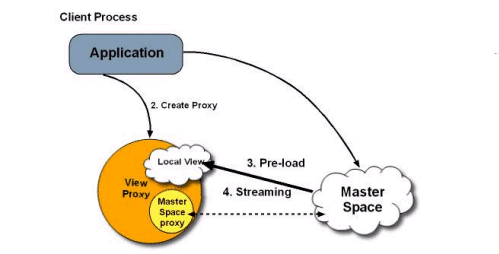
Local View
| Description | Each client has a lightweight, embedded cache (space instance), which contains a subset of the mater space’s data. The client defines which data is cached using a collection of SQL queries, and the master space pushes the matching data to the client’s cache. |
|---|---|
| Common Use | Achieving maximal read performance for a predetermined subset of the data. |
| Options | The master cache can be clustered in any of the other topologies: replicated, partitioned, etc. |
The topologies above are provided in the GigaSpaces product as predefined cluster schemas. The schema names are:
- Synchronous replication -
sync-replicated - Asynchronous replication -
async-replicated - Partitioned with backup -
partitioned-sync2backup
The local cache and local view topologies do not need their own schemas, because they are defined on the client side.
Split Brain
A partitioned space topology with no backups should not be used in production. Running an XAP space with no backups may cause split brain and data inconsistency issues.