Caching Scenarios
GigaSpaces IMDG supports three kinds of caching mechanisms:In-line Cache, Side Cache and Client Side Cache. Using GigaSpaces IMDG as a cache provides you the following benefits:
- Low latency - In-Memory Data access time without any disk usage.
- Data access layer elasticity - Scale out/up on demand to leverage additional machine resources.
- Less load on the database layer - Since the cache will isolate the database from the application somewhat, you will have less contention generated at the database layer.
- Continuous High-Availability - Zero downtime of your data access layer with the ability to survive system failures without any data loss.
Both the In-line cache and the Side cache support the common deployment topologies: replicated, partitioned and primary-backup partitioned.
In-line Cache
With this mechanism, the IMDG is the system of record. The database data is loaded into the IMDG when it is started. The IMDG is responsible for loading the data and pushing updates back into the database. The database can be updated in synchronously or asynchronously.
- When running in
all-in-cachecache policy mode, all data is loaded from the database into the cache once it is started. - When running in
LRUcache policy mode, a subset of the data is loaded from the database into the cache when it is started. Data is evicted from the cache based on available memory or a maximum amount of cache objects. Once there is a cache miss, the cache looks for the data within the underlying data-source. If matching data is found, it is loaded into the cache and delivered to the application.
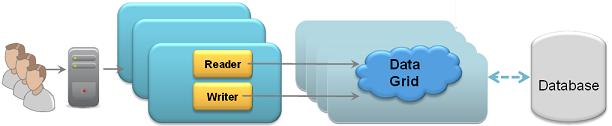
The in-line cache is implemented using the following configurations:
- Read-through and Write-through - For persisting the cache data synchronously.
- Write-behind - Mirror - For persisting the cache data asynchronously.
Persistence logic can either be the out-of-the-box Hibernate external data source or any custom persistence logic that implements the Space Persistency extension points.
The in-line cache ensures maximum performance when fetching data where the database is outside the critical path of the application transaction. (This makes more sense than it might seem: database contention is a primary source of application performance failure.)
For best performance you should use the ALL-IN-CACHE cache policy with the write-behind mirror. This will ensure maximum hit rate when accessing the cache. With this mode, you should make sure the cache can accommodate all the data you will access.
The in-line cache mechanism is widely used with the following GigaSpaces APIs:
- GigaSpace API - GigaSpaces native Object/SQL API.
- Map API - GigaSpaces Key/Value (JCache/Hashtable) API.
When you should use an in-line cache?
An in-line cache is very useful when:
- The total size of data stored within the database (or any other data source) is equal or less than the amount of data stored in memory. Ideally, you’d use the
ALL_IN_CACHEcache policy mode. - The original data model of the data within the database (or any other data source) is similar to the data model of the objects in memory. Space Persistency will work very well: the data will be loaded automatically from the database into the cache and every change to the data in the cache will be propagated to the database behind the scenes.
Side Cache
With this mechanism, the application is responsible for maintaining the data in the cache:
- The application attempts to read an object from the cache.
- If the object is found within the cache, the application uses it.
- If the object isn’t found within the cache - The application fetches it from the database and the the application writes it into the cache. Another option is to turn on the space Data source and allow it to load the data on cache miss in a lazy manner.
- The next time the application attempts to fetch the same object, it will be read from the cache - unless the object has been expired, evicted ore removed explicitly.
Side cache without External Data Source:
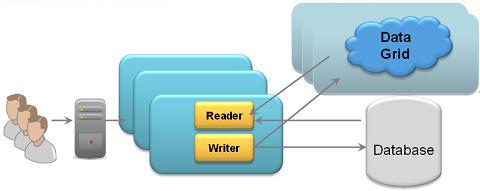
Side cache with External Data Source:
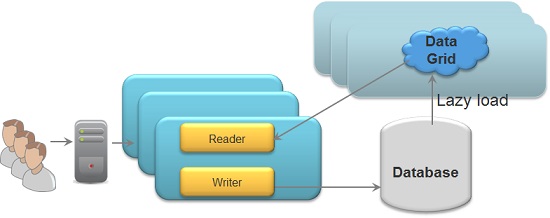
With a Side Cache architecture there is no Mirror. The application responsible to write changes to the database. Data is evicted or expired from the space by writing it with a finite lease (TTL). There are two options how data is loaded into the space:
- By running in
LRUcache policy mode having the space configured with external data source, loading data on cache miss and also via initial load. - By running in
ALL_IN_CACHEcache policy mode, (you many have also external data source to enable initial load), having the application first trying to read from the space. If can’t find relevant data in the space reading from the DB and writing it explicitly to the space , to be used later again.
The Side cache scenario is widely used with the following GigaSpaces APIs:
- GigaSpace API - GigaSpaces native Object/SQL API.
- Map API - GigaSpaces Key/Value (JCache/Hashtable) API.
- JDBC API - GigaSpaces native JDBC driver.
- memcached API - Using any memcached client (Java , C# , C , C++..). See memcached libraries page for the different programming languages supporting the memcached protocol that may be used with GigaSpaces server memcached implementation.
- Hibernate - Leveraging GigaSpaces as Hibernate 2nd Level Cache.
When you should use a side cache?
A side cache is very useful when:
- The total amount of data stored in the database (or any other data source) is relatively much higher than the amount of data stored in-memory. In such a case, you should be running the space in
LRUcache policy mode. - The original data model of the data within the database (or any other data source) is very different than the data model of the objects in-memory. In such a case the built-in Space Persistency implementation may not be relevant. A customized mapping logic should be implemented at the client application side to load data from the database and push it into the cache.
Client Cache
Together with the in-line cache and side cache scenarios, you can also use client cache. This client cache may host data loaded from any IMDG partition. The client cache data access does not involve any serialization or network calls.
When using client cache, you use a two-layered cache architecture: The first layer runs locally, within the client, and the second layer runs in the remote IMDG. The remote IMDG may use any of the supported deployment topologies.
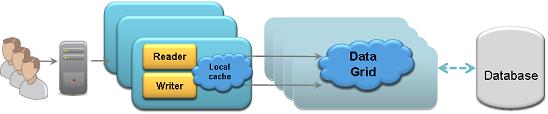
In-line cache with a client cache:
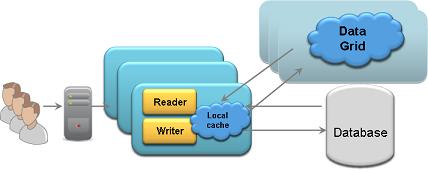
Side cache with a client cache:
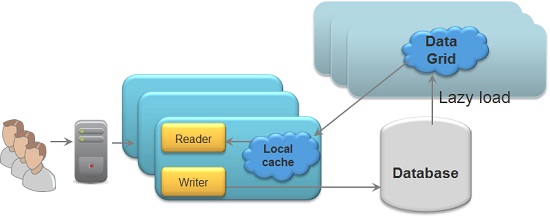
Side cache using External Data Source with a client cache:
The client cache size is limited to the client process heap size. The client-side cache is updated automatically once the master copy of the object within the IMDG is updated. The client cache can be implemented using the following configurations:
- Local Cache - On-demand client cache loading data based on client activity. This type of client cache evicts data once the client available memory drops below a configurable value.
- Local View - Pre-fetch client cache loading data based on set of SQL queries. This client cache does not evict data. This client cache is designed to be read-only and support both queries and reads based on ID.
Client cache is not enabled by default.
When you should use a Client Cache?
Client side cache should be used when most of the application activities (above 80%) involves reading data (a read-mostly scenario). When having repeated read activities for the same data (using readById operation), client cache will provide excellent performance boost (up to 100 times faster when compared to when a client cache is not being used). You should not use client cache when having a relatively large amount of data updates or removal operations since the overhead of the client cache updates will impact the overall application performance.
Cache Refresh Options
When running the cache in LRU cache policy mode, you may need to expire or evict the cache data. This will make sure you will not load the cache with unnecessary data. Another reason to expire or evict the cache data is to make sure the memory allocated for the cache (JVM heap size) can accommodate the most valuable objects your applications needs.
Here are few options you may use to refresh the cache:
- Eviction - You may configure the space to evict data by running in LRU eviction policy.
- Lease expiration - You may write objects into the space with a specific time to live (lease duration).
- Programmatic expiration - You may expire the object using:
net.jini.core.lease.Lease.cancel()- You can get the Lease object as a result of a write operation for a new object.GigaSpace.writeoperation for an existing object (update) using a short lease time. See the GigaSpace interface write operation for details.- Take operation with TakeModifiers.EVICT_ONLY mode. See the GigaSpace interface take operation for details.
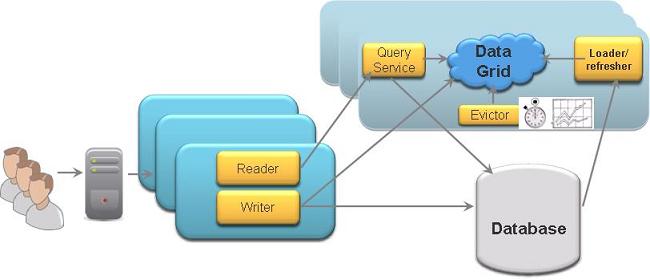
Refresh data using LRU and Timer
With this approach data is pushed into the cache in a periodic manner via a timer. The Timer will be fetching relevant data that was recently updated within the database and pushing it into the cache.
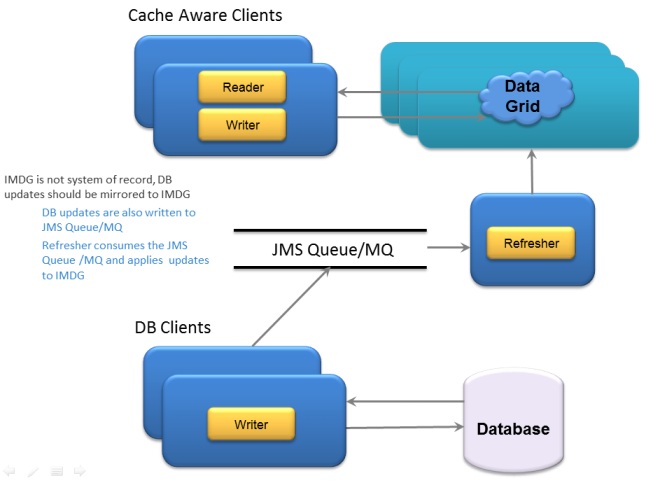
Refresh data using a Queue
Any updates made to the database are also written to a queue. Refresher client consumes the messages on the queue and applies these changes to space.
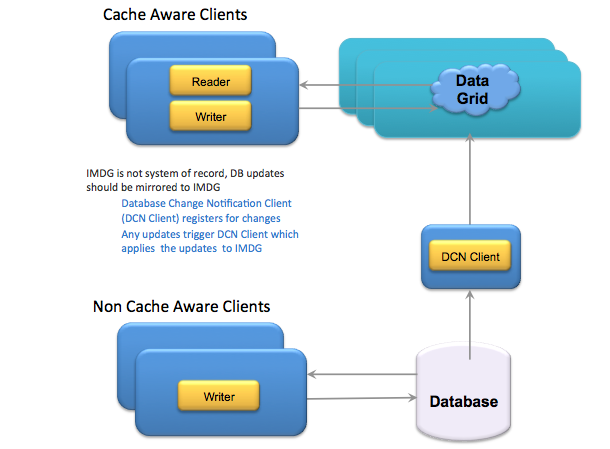
Refresh data using Database Change Notifications
Oracle and few other databases support Database Change Notifications where a client can register a listener for changes to data. Any changes made to the database will trigger the listener defined in a DCN Client. Listener can in turn write these messages into the space.