Consistency Biased
In distributed computing, consistency-biased leader election is established using an odd number of coordinators (usually 3). Having an odd number ensures that if a network segmentation occurs, there will be no draw between the segments - the majority of coordinators (e.g. 2) will be in one segment, and the minority (e.g. 1) in the other. This allows each segment to play its role and ensure consistency:
- If the minority segment holds leadership, it will relinquish it, and will suspend itself until it rejoins the majority.
- The majority segment will select a new leader if needed, knowing that the minority will relinquish the previous leader.
In XAP, consistency-biased leader election is used when the space is deployed on an environmenent managed by a XAP Manager cluster - each manager contains an embedded Zookeeper node, and together they provide the necessary environment to ensure consistency.
What is Zookeeper?
Apache ZooKeeper is a centralized service providing distributed synchronization, which can be used for various use cases in distributed systems such as leader election, configuration, distributed locks and more. It is highly reliable and widely used across the industry, both in open source projects (e.g. Apache HBase, Apache Kafka) and large companies (e.g. Yahoo, Rackspace).
There’s no need to download or setup Zookeeper - it’s packaged with XAP and automatically started & monitored by the XAP Manager.
Usage
When a space is deployed on an environment managed by a XAP Manager, consistency-biased leader election is automatically enabled.
Configuration
The default configuration is valid for most environments and applications. You can change it if you need to decrease/increase failover time (i.e. the duration between a primary fails and a backup accepts leadership in its place), using the following space properties:
| Property | Description | Default |
|---|---|---|
space-config.leader-election.zookeeper.session-timeout |
Session timeout (in milliseconds) | 8000 |
space-config.leader-election.zookeeper.connection-timeout |
Connection timeout (in milliseconds) | 5000 |
space-config.leader-election.zookeeper.retry-timeout |
Retry timeout, in case operation fails | Integer.MAX_VALUE |
space-config.leader-election.zookeeper.retry-interval |
Interval between retries (in milliseconds) | 1000 |
A shorter failover time is a two-edged sword - it can cause short network disconnections to trigger failover for no need, harming system’s stability. Changing those defaults should be done carefully and adjusted to your network capabilities and applicative requirements
Under The Hood
XAP is using Apache Curator leader selector recipe which implements a distributed lock with notifications mechanism using Zookeeper.
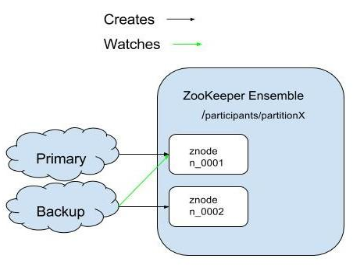
- A znode, say “/participants/partitionX”
- All participants of the election process create an ephemeral-sequential node on the same election path.
- The node with the smallest sequence number is the leader.
- Each “follower” node listens to the node with the next lower seq number.
- Upon leader removal go to election path and find a new leader, or become the leader if it has the lowest sequence number.
- Upon session expiration (disconnection) check the election state and go to election if needed, in case of disconnection the primary space instance is moved to Quiese mode and will be restarted.
Partition Split-Brain
Zookeeper leader selector avoids split-brain instances, through quorum, If the primary is not in the majority, that primary is frozen(or Quiesce) until the network is connected and the frozen primary is terminated automatically.