SpaceDeck – StreamSQL Implementation
StreamSQL allows to SpaceDeck![]() GigaSpaces intuitive, streamlined user interface to set up, manage and control their environment. Using SpaceDeck, users can define the tools to bring legacy System of Record (SoR) databases into the in-memory data grid that is the core of the GigaSpaces system. to implement a low code (SQL) approach to define and operate with ad-hoc data flows, such as read from Kafka
GigaSpaces intuitive, streamlined user interface to set up, manage and control their environment. Using SpaceDeck, users can define the tools to bring legacy System of Record (SoR) databases into the in-memory data grid that is the core of the GigaSpaces system. to implement a low code (SQL) approach to define and operate with ad-hoc data flows, such as read from Kafka![]() Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. and write directly to Space
Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. and write directly to Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. or read from one Kafka topic and write to another Kafka topic.
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. or read from one Kafka topic and write to another Kafka topic.
StreamSQL operations activities can be defined using SQL statements, for example:
-
Define structure of messages in a Kafka topic as a table - CREATE TABLE.
-
Define a data flow (stream of data or pipeline) as INSERT AS SELECT statement.
-
Perform a join of data flow from different Kafka topics using a standard SQL join statement.
For additional information refer to the DI StreamSQL page.
For an StreamSQL overview refer to the streamSQL overview page.
Example 1: Kafka to Space with Aggregation
-
Go to the Data Query menu.
-
Run the following CREATE TABLE statement:
-
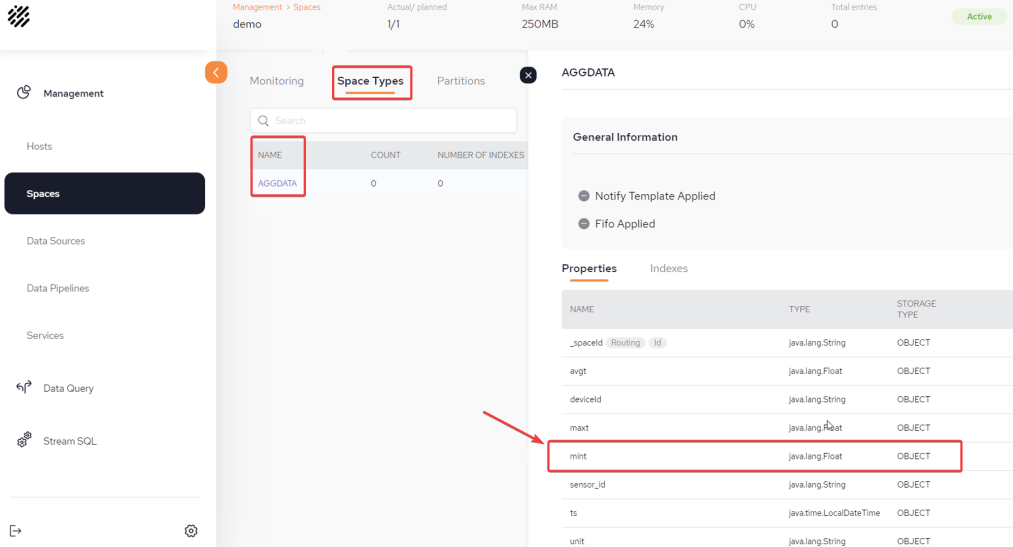
From the Space menu, validate via Space Details - Space Types that the object in the Space has been created correctly - in this example AGGDATA:
-
From the main Stream SQL menu screen, click Create New Stream + to create a new stream.
-
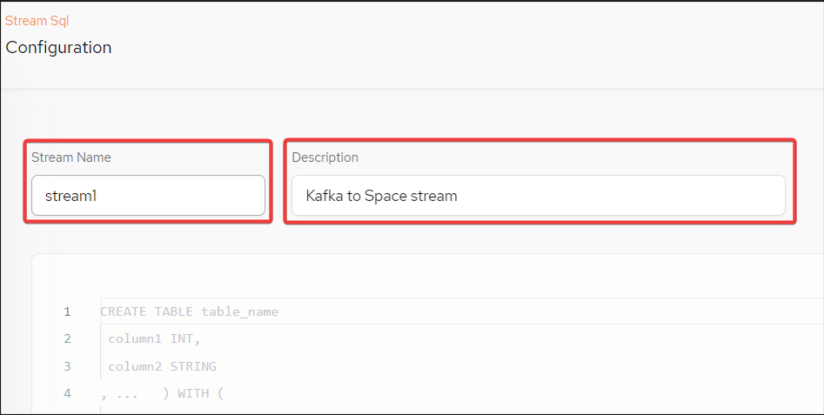
Provide the Stream Name and Description:
-
In the text window of the Stream SQL, create the following SQL queries (7, 8 and 9 below).
-
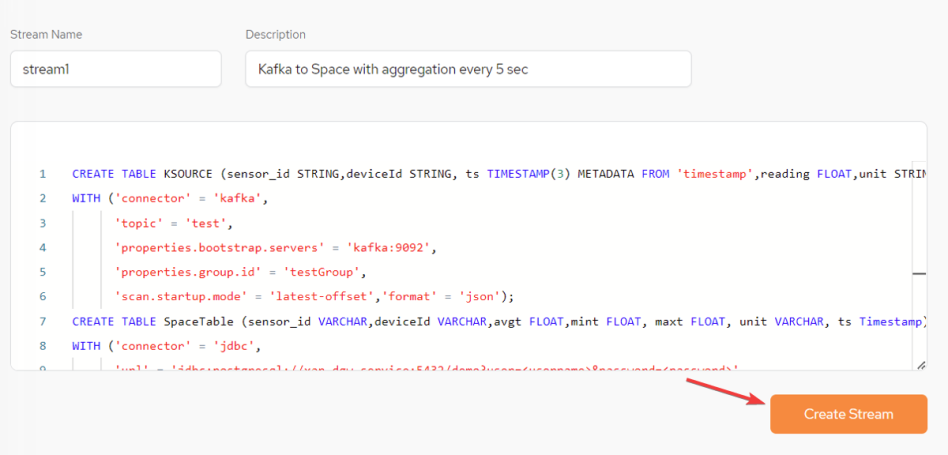
Use a CREATE TABLE statement to define the Kafka topic as a table. All properties are defined as columns and Kafka details are also provided:
-
Use a CREATE TABLE statement to define a Space as a target:
-
Use an INSERT SELECT statement to define a continuous flow of events from Kafka to the Space:
-
After the statements above have all been written together to the StreamSQL text window, click Create Stream:
-
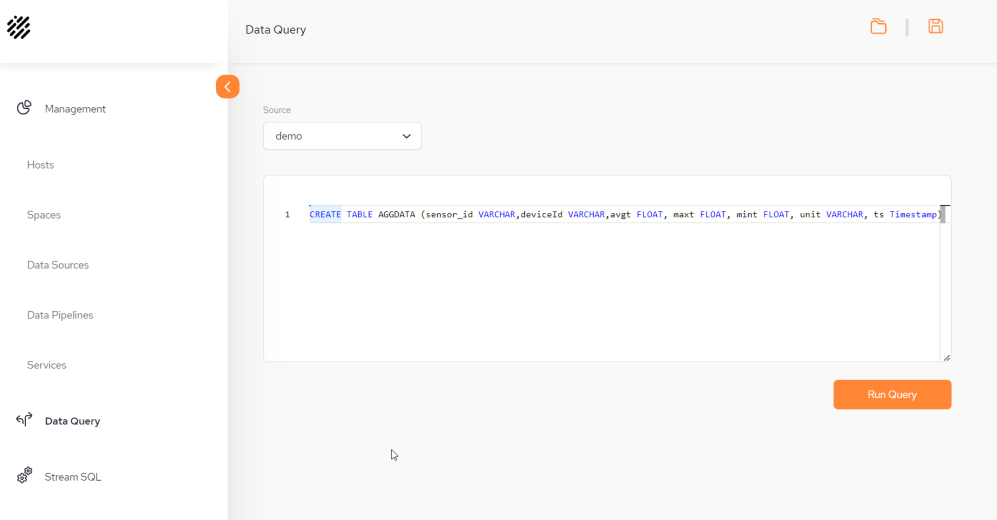
From the StreamSQL menu, run an SQL Query to query the aggregation data in the Space. For the example above, run:
CREATE TABLE AGGDATA (sensor_id VARCHAR,
deviceId VARCHAR,
avgt FLOAT,
maxt FLOAT,
mint FLOAT,
unit VARCHAR,
ts Timestamp)
All SQL statements should be submitted together with a semicolon delimiter.
CREATE TABLE KSOURCE (sensor_id STRING,deviceId STRING, ts TIMESTAMP(3) METADATA FROM 'timestamp',reading FLOAT,unit STRING,WATERMARK FOR ts AS ts - INTERVAL '5' SECOND)
WITH ('connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = 'kafka:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset','format' = 'json');
CREATE TABLE SpaceTable (sensor_id VARCHAR,deviceId VARCHAR,avgt FLOAT,mint FLOAT, maxt FLOAT, unit VARCHAR, ts Timestamp)
WITH ('connector' = 'jdbc',
'url' = 'jdbc:postgresql://xap-dgw-service:5432/demo?user=<username>, &password=<password>'
'table-name' = 'AGGDATA'); Make sure that the correct username and password credentials are used to connect to the data gateway.
insert into SpaceTable (ts,deviceId,sensor_id,avgt,maxt,mint,unit) select TUMBLE_START(ts, INTERVAL '5' SECOND) AS ts,deviceId,sensor_id,avg(reading),max(reading),min(reading),unit
from KSOURCE
group by TUMBLE(ts, INTERVAL '5' SECOND),deviceId,sensor_id,unit;
SELECT * from AGGDATA order to ts desc
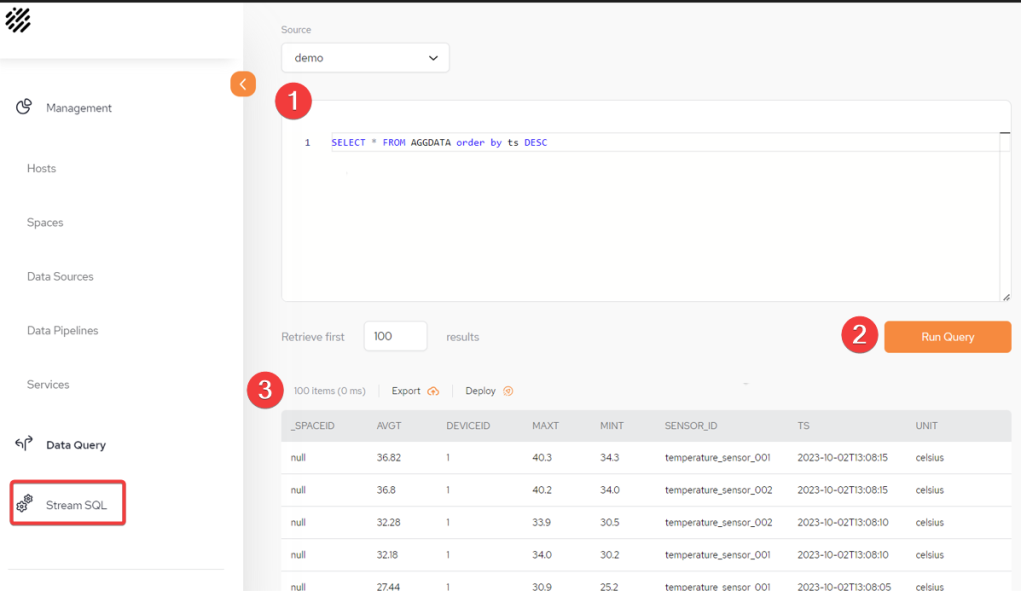
1 Write the query in the StreamSQL text window.
2 Run the Query.
3 Results of the Query.
Example 2: Kafka to Kafka with Aggregation
In this example, temperature data from sensors is consumed from a Kafka topic. This is aggregated using a standard SQL statement. An alert is raised only if the average temperature is above a certain threshold. An alert is a message that is published to a dedicated alerts topic in Kafka.
-
From the main StreamSQL menu screen, click Create New Stream + to create a new stream.
-
In the text window of the StreamSQL, create the following SQL queries.
-
Use a CREATE TABLE statement to define the Kafka source topic as a source table. All properties are defined as columns and Kafka details are also provided:
-
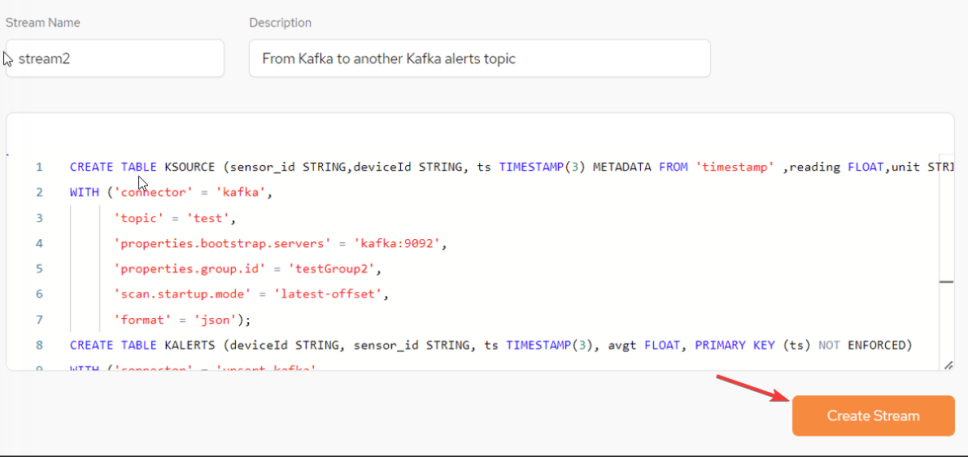
Use a CREATE TABLE statement to define a Kafka alerts topics as a target table:
-
Use an INSERT SELECT statement to define a continuous flow of events from the Kafka source topic to the Kafka target topic. All events have an average temperature above 36.6:
-
After the statements above have all been written together to the StreamSQL text window, click Create Stream:
All SQL statements should be submitted together with a semicolon delimiter.
CREATE TABLE KSOURCE (sensor_id STRING,deviceId STRING, ts TIMESTAMP(3) METADATA FROM 'timestamp',reading FLOAT,unit STRING,WATERMARK FOR ts AS ts - INTERVAL '1' SECOND)
WITH ('connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = 'kafka:9092',
'properties.group.id' = 'testGroup2',
'scan.startup.mode' = 'latest-offset',
'format' = 'json');
CREATE TABLE KALERTS(deviceId STRING, sensor_id STRING, ts TIMESTAMP(3), avgt FLOAT, PRIMARY KEY (ts) NOT ENFORCED)
WITH ('connector' = 'upsert-kafka',
'topic' = 'sensorsAlertsAvgTemp',
'properties.bootstrap.servers' = 'kafka:9092',
'properties.group.id' = 'testGroup2',
'key.format' = 'json',
'value.format' = 'json');
insert into KALERTS (ts,deviceId,sensor_id,avgt) select TUMBLE_START(ts, INTERVAL '5' SECOND) AS ts,deviceId,sensor_id,avg(reading) as avgt
from KSOURCE
group by TUMBLE(ts, INTERVAL '5' SECOND),deviceId,sensor_id,unit
having avg(reading) > 36.6;