Availability Biased
This page is for users who are starting the (Grid Service Manager) GSM![]() Grid Service Manager.
This is is a service grid component that manages a set of Grid Service Containers (GSCs). A GSM has an API for deploying/undeploying Processing Units. When a GSM is instructed to deploy a Processing Unit, it finds an appropriate, available GSC and tells that GSC to run an instance of that Processing Unit. It then continuously monitors that Processing Unit instance to verify that it is alive, and that the SLA is not breached. and Lookup Service (LUS
Grid Service Manager.
This is is a service grid component that manages a set of Grid Service Containers (GSCs). A GSM has an API for deploying/undeploying Processing Units. When a GSM is instructed to deploy a Processing Unit, it finds an appropriate, available GSC and tells that GSC to run an instance of that Processing Unit. It then continuously monitors that Processing Unit instance to verify that it is alive, and that the SLA is not breached. and Lookup Service (LUS![]() Lookup Service.
This service provides a mechanism for services to discover each other. Each service can query the lookup service for other services, and register itself in the lookup service so other services may find it.) separately and not using the GS Manager
Lookup Service.
This service provides a mechanism for services to discover each other. Each service can query the lookup service for other services, and register itself in the lookup service so other services may find it.) separately and not using the GS Manager
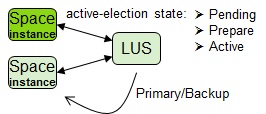
In this leader election implementation, Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. instances register themselves with the LUS. The Space instances then undergo an active-election process, to discover current Space instances and elect a primary instance.
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. instances register themselves with the LUS. The Space instances then undergo an active-election process, to discover current Space instances and elect a primary instance.
The active-election process is a 3-phase procedure:
- Pending
- Prepare
- Active
Split Brain and Primary Resolution
Split Brain Scenario
Split brain occurs when there are two or more primary instances running for the same partition. In most cases the reason for such behavior would be a network disruption that does not allow each Space instance to communicate with all lookup services running. Usually, each Space instance will communicate with a different lookup service rather all of them (two in most cases).
During this split, clients may communicate with each primary as its master data copy updating the data within the Space. If the active GSM also loses connectivity with both lookup services, it may provision a new backup.
When the connection between all instances of a given partition and all lookup services is re-established and a split brain is identified (more than a single primary instance is defined for a given partition), the system determines which instance will remain the primary, and which will be demoted to a backup instance. The data within the instance that is demoted to backup is dropped.
The primary resolution may involve several steps, which are described in detail below. The purpose of each step is to try and calculate the most recent primary and its data consistency level. If the primary can't be determined in the first step (results are equivalent - a tie), then the second step is executed (tie break). If the primary can't be determined in the second step, the third step is executed (second tie break). After a primary is elected, the other instance is demoted to backup mode and it recovers all the data from the primary.
Data resolution occurs between two different clusters using the WAN gateway as a replication channel. In this case, a conflict resolution is executed.
Primary Resolution
GigaSpaces provides built-in recovery policies after a split brain has been detected. The default "discard-least-consistent" policy determines which instance should remain as primary and which instance should be demoted. However, the "suspend-partition-primaries" policy suspends all interaction with both instances until the split brain is resolved manually.
The recovery policy can be configured using the Space os-core:properties element. The value is one of the policy names. If none is specified, the default "discard-least-consistent" policy is applied.
<os-core:space id="space" url="/./space">
<os-core:properties>
<prop key="space-config.split-brain.recovery-policy.after-detection">
suspend-partition-primaries
</prop>
</os-core:properties>
</os-core:space>
Discard Least Consistent Policy
The instance that is found to be "least consistent" is discarded and instantiated again in the data grid as a backup Space. The policy has three steps that are described below.
Resolution - Step 1
Each primary instance is inspected by checking for multiple properties, and an inconsistency ranking is calculated. The instance with the lowest ranking is elected as the primary. If both instances receive the same ranking (inconsistency level), step two is executed.
The inconsistency level is calculated using the mirror's active primary identity and various replication statistics. Since the mirror doesn't allow multiple primary instances for the same partition, it can be useful in the inconsistency level calculation.
Resolution - Step 2
Each instance is inspected for the exact time it was elected to be a primary (the election time is stored within the lookup service). All lookup services are inspected during this process. The instance that was elected to be a primary first remains the primary. If both instances were elected at the same time, or if the election time can't be determined due to discrepancies in the lookup service registration, step three is executed.
Resolution - Step 3
The system reviews the primary instance names, and the one whose name has the lowest lexical value remains the primary.
Suspend Partition Primaries Policy
With this policy, both primary instances are suspended (see Quiesce for reference) awaiting manual resolution. The policy has three steps that are described below.
Resolution - Step 1
Upon discovery of a split brain, each primary instance enters a Self-Quiesce mode, suspending all interaction with the Space. Only interactions of a proxy that is applied with the Quiesce token are allowed. The Quiesce token is the name of the Space (as apposed to the default auto-generated token) to ease coding logic via the Admin API upon split-brain detection.
The logs will show a message similar to:
... "Space instance [gigaSpace_container1:gigaSpace] is in Quiesce state until split-brain is resolved - Quiesce token [gigaSpace]"
Resolution - Step 2
Now that both instances are suspended, manual intervention is needed in order to choose the correct primary, extract data from the cluster, etc. These actions can be done via the CLI, GigaSpaces Management Center, or the Admin API. With the Admin API, you can be alerted when a split brain is detected.
//configure the alert
AlertManager alertManager = admin.getAlertManager();
alertManager.configure(new SpacePartitionSplitBrainAlertConfigurer().enable(true).create());
//be notified
alertManager.getAlertTriggered().add(new AlertTriggeredEventListener() {
public void alertTriggered(Alert alert) {
if (alert instanceof SpacePartitionSplitBrainAlert) {
... //do somthing
Space space = ... //obtain reference
GigaSpace gigaSpace = space.getGigaSpace();
gigaSpace.setQuiesceToken(new DefaultQuiesceToken(space.getName()));
... //do something with the gigaSpace
}
}
Resolution - Step 3
The last part of the policy is to remove the unwanted primary instance. This is best achieved by restarting the instance either from the GigaSpaces Management Center or the Admin API.
//obtain the processing unit This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity. instance reference
ProcessingUnitInstance instance = ...
instance.restartAndWait();
This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity. instance reference
ProcessingUnitInstance instance = ...
instance.restartAndWait();
After the instance is removed, the remaining primary must be un-quiesced to resume incoming interactions. This can be done via CLI command or the Admin API on the Processing Unit.
//obtain the Processing Unit reference
ProcessingUnit pu This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity. = ...
pu.unquiesce(new QuiesceRequest("split-brain resolved"));
Common Causes of Split Brain
Below are the most common causes for split brain scenarios and ways to detect them.
-
JVM
Java Virtual Machine. A virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. Garbage Collection spikes - when a full GC happens, it has a "stop-the-world" effect on both the GigaSpaces and application components (and holding internal clocks and timing), and external interactions.- Using JMX or other monitoring tools you can monitor the JVM Garbage Collection activity. A full GC of longer than 30 seconds should trigger an alert. You can use the Admin API to fetch the full GC events. If the GC takes more than 10 seconds, it will be logged as a warning in the GSM/GSC Grid Service Container.
This provides an isolated runtime for one (or more) processing unit (PU) instance and exposes its state to the GSM./GSA Grid Service Agent.
This is a process manager that can spawn and manage Service Grid processes (Operating System level processes) such as The Grid Service Manager, The Grid Service Container, and The Lookup Service. Typically, the GSA is started with the hosting machine's startup. Using the agent, you can bootstrap the entire cluster very easily, and start and stop additional GSCs, GSMs and lookup services at will. log file.
- Using JMX or other monitoring tools you can monitor the JVM Garbage Collection activity. A full GC of longer than 30 seconds should trigger an alert. You can use the Admin API to fetch the full GC events. If the GC takes more than 10 seconds, it will be logged as a warning in the GSM/GSC
-
High (>90%) CPU utilization - this can cause various components (also external to GigaSpaces) to compete for CPU clock resources, such as keep-alive mechanisms (which can miss events, triggerering initialization of redundant services or false alarms), IO/network lack of available sockets, OS fails to release resources etc. Scenarios of constant (more than a minute) utilization of over 90% CPU should be avoided.
- You can use the out-of-the-box CPU monitoring component (which uses
- You can use the out-of-the-box CPU monitoring component (which uses
-
Network outages/disconnections - As discussed, disconnections between the GSMs or GSMs and GSCs can cause any of the GSMs to begin behaving like "islands". This term is described in detail below.
- Use a network monitoring tool to monitor network outages/disconnections and reconnections on the machines that host the GSMs and GSCs. Whatever tool you use should report and alert on the exact date/time of the event.
Islands
When network or failure events occur, the system can start to exhibit unexpected behavior, also called Islands, which are extreme scenarios that require special handling. You may encounter one of the following two islands scenarios:
- A server running one of the GSMs that is managing some of the PUs is disconnected from the network, and later reconnects with the network. The GSM (which is still a primary) tries to redeploy the failed PUs. The result depends on which of the two GSMs was the primary at the point of disconnection. If the primary GSM is on the island with the GSCs, its backup GSM will become a primary until the network disconnection is resolved. When the network is repaired, the GSM detects that the "former" primary is still managing the services, and returns to backup state. But if the reverse is true, and the primary GSM lost connection with its PUs due to network disconnection or any other failure, it will behave as the primary and try to redeploy as soon as a GSC is available. This can lead to inconsistent mapping of services and an inconsistent system.
- A more complex form of "islands" is if GSCs are available on both islands, leading both GSMs to behave as primaries and deploy the failed PUs. Reconciling at this point needs to take data integrity into account.
The solution for these scenarios is to manually reconcile the cluster. Terminate one GSM, and with only one remaining managing GSM restart the GSCs hosting the backup space instances. As a last step, start the second GSM (which will serve as the backup GSM).
Troubleshooting
For troubleshooting information for Availability Biased leader election, see the discussion in Failure Detection.