SpaceDeck – Data Sources
Data Sources define the origin of data in the System of Record. A data source is a reference to a particular database or data store.
It is a logical representation of the connection to the actual source.
When we define a data pipeline definition, we will include a reference to a particular data source, and to a particular set of tables and fields in that data source.
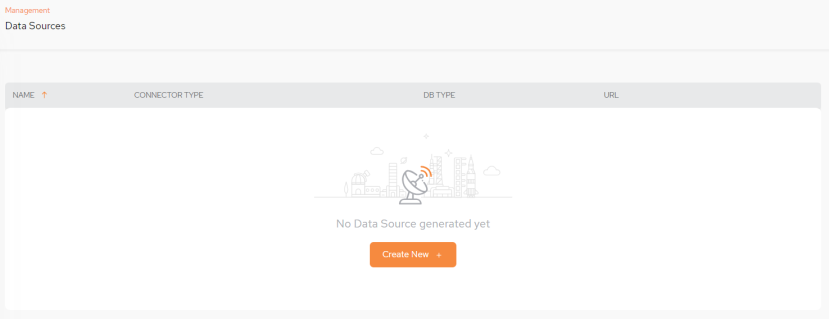
Data Source Main Screen
The initial Data Sources screen.
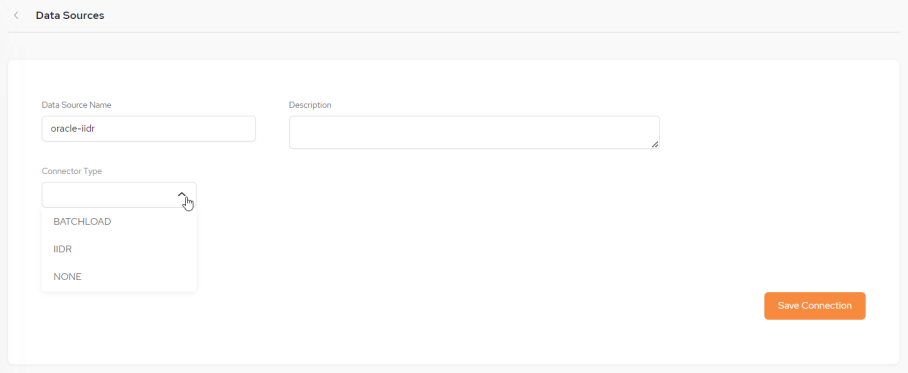
Setting Up a New Data Source
To setup a new Data Source click Create New +: or New + if a data source already exists.
The initial Configuration screen will then be displayed.
Data Sources Fields
-
NAME – The name you define for the data source
The data source name is not case sensitive and has no limits for naming
-
CONNECTOR TYPE – The connector type - select either IIDR
 IBM Infosphere Data Replication.
This is a solution to efficiently capture and replicate data, and changes made to the data in real-time from various data sources, including mainframes, and streams them to target systems. For example, used to move data from databases to the In-Memory Data Grid. It is used for Continuous Data Capture (CDC) to keep data synchronized across environments., BATCHLOAD or None.
IBM Infosphere Data Replication.
This is a solution to efficiently capture and replicate data, and changes made to the data in real-time from various data sources, including mainframes, and streams them to target systems. For example, used to move data from databases to the In-Memory Data Grid. It is used for Continuous Data Capture (CDC) to keep data synchronized across environments., BATCHLOAD or None.For using Batch Load, the following configuration parameter needs to be used the helm command during Kubernetes
An open-source container orchestration system for automating software deployment, scaling, and management of containerized applications. installation. global.batchload.enabled=true
Data Source - IIDR
If you select Connector Type IIDR the following setup screen is displayed:
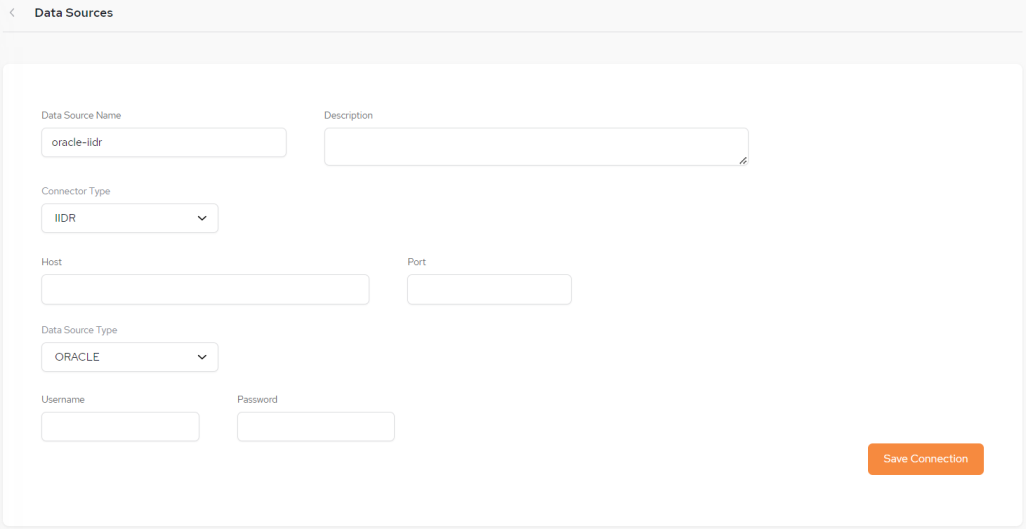
Data Sources - IIDR Setup Fields
-
Date Source Name – The name you define for the data source.
-
Description – A free-format description of the data source.
-
Connector Type – In our example, for an Oracle database, IIDR has been selected.
-
Host – The Host for the data source.
-
Port – The Port assigned for the data source.
-
Data Source Type - Options are ORACLE, MSSQL, DB2ZOS, DB2I
-
Username and Password – The credentials for accessing the data source.
Enter the configuration details and click Save Connection, The new data source will now be listed on the main Data Sources screen.
Data Source - Batch Load
Refer to our batch load page for more details.
If you select Connector Type BATCHLOAD the following setup screen will be displayed:
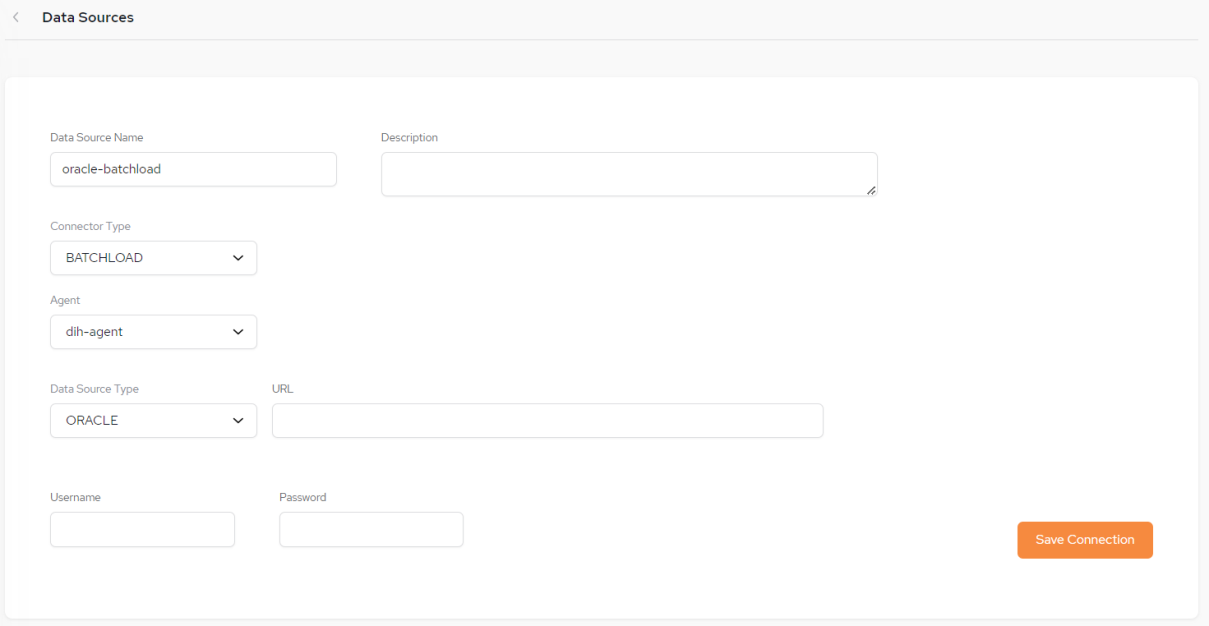
Data Sources - Batch Load Setup Fields
-
Date Source Name – The name you define for the data source.
-
Description – A free-format description of the data source.
-
Connector Type – In our example, for an Oracle database, BATCHLOAD has been selected.
-
Agent - Select the batch load agent being used (use a different agent for each pipeline).
For using batch load, the following configuration parameters need to be used the helm command during Kubernetes helm umbrella installation.
global.batchload.enabled=true. If an additional agent is required, the this helm command needs to be used:global.batchload-agent.enabled=true. For installing an agent and controlling its name:global.batchload-agent.agent.name=[name of agent] -
Data Source Type - Currently only ORACLE is available.
-
URL - URL of the Data Source.
-
Username and Password – The credentials for accessing the data source.
Enter the configuration details and click Save Connection, The new data source will now be listed on the main Data Sources screen.
Deleting a Data Source
There is an option to delete a data source by clicking the kebab menu (vertical three-dot menu) on the far right of the main Data Sources menu and clicking Delete Data Source:

Next Step – Using the Data Source in a Data Pipeline
After you create the data source, you can define a data pipeline using that data source.