Data Types, Schema Types and Schema Evolution
What Kinds of Data Stores are Available in GigaSpaces?
When a Data Store object is defined in GigaSpaces, the object can be defined as a Space Object or a Space Document.
Within each object type, the data schema can be defined with:
- Fixed or static properties (columns), sometimes referred to as schema on write,
- Dynamic properties, sometimes referred to as schema on read, or
- Hybrid, a combination of both fixed and dynamic properties.
The choice of object type and schema definition can have a profound impact on an application's memory footprint and processing speed, and on the procedure required to make a change in the schema.
Schema Evolution - Changing a Schema
When a change is required to the underlying structure or schema of an object, this change process is referred to as Schema Evolution.
There are three general approaches for schema evolution:
- Use of dynamic properties -- define a data store that has dynamic, schema-on-read properties
- In-place schema evolution redeploying the space -- define a data store that has fixed, schema-on-write properties -- requires downtime
- Side-by-Side Schema Evolution -- define a data store with any combinstion of dynamic and fixed properties -- no downtime.
A summary of these three methods of Schema Evolution is shown in the table below.
| Schema Evolution method | Property Type | Resource usage during schema transformation | Memory footprint of properties | Requires downtime? | Schema strategy | Schema transformation duration | Data transformation | Index functionality |
|---|---|---|---|---|---|---|---|---|
| Option A: Use of dynamic properties | Dynamic | Low | Some overhead | No | In place | Immediate | Null fields by default to v1,v2 holds the new schema | Only equality index, no range index |
| Option B: In-place schema evolution redeploying the space
Time-consuming -- undeploy the data store and any PUs that use the data store; modify the schema; redeploy. |
Dynamic and fixed | Low | None | Yes | In place | Dependent on the space size and network bandwidth to the external DB | All v1 is transformed to v2 | Any index |
| Option C: Side-by-Side Schema Evolution
Create a new data store without downtime. |
Dynamic and fixed | Double the normal memory and CPU requirements | None | No | Side by side | Minutes to hours | All v1 is transformed to v2 | Any index |
Schema Evolution by Use of Dynamic Properties
The easiest way to achieve schema evolution is via dynamic properties - each entry can store a set of dynamic properties, which are not bound by the type schema. In this case schema evolution is automatic - your app simply starts writing entries with additional properties. No change is required in the space.
The downside is that the memory requirement increases - because there's no schema for those properties, each entry's memory footprint is larger.
In-place Schema Evolution with Downtime
This approach is to undeploy the GigaSpacesservice, modify the schema in the external database, and then re-deploy the GigaSpaces service. This will initial-load the modified schema and data.
This results in an efficient footprint in memory, but requires some downtime while the data store is being copied.
Side-by-Side Schema Evolution
Side-by-Side Schema Evolution can make the process of changing a fixed schema efficient and painless.
Side-by-Side Schema Evolution works by creating a mirror service and copying the original space (V1) to the new space (V2). The copying process is done via a Kafka![]() Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. messaging layer and does not require the Space
Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. messaging layer and does not require the Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. or stateful services that use the Document Store to be offline. Note that the V1 and V2 spaces co-exist side-by-side. External users are redirected to the new service, and the old service is closed.
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. or stateful services that use the Document Store to be offline. Note that the V1 and V2 spaces co-exist side-by-side. External users are redirected to the new service, and the old service is closed.
While the copying process is underway, all requests are logged for later processing with the new V2 object. No data is lost. There is no downtime and no requirement to make the space offline.
Because Side-by-Side Schema Evolution makes online changes to a fixed-schema object, the object’s schema can be updated from time to time -- providing much of the flexibility of a Space Document.
The resulting object has all of the advantages of a fixed schema -- optimal read/write processing and minimal memory footprint -- without a need for the system to interpret dynamic fields.
Schema Changes Allowed with Side-by-Side Schema Evolution
The following types of changes can be performed:
- Add a new field
- Remove an existing field
- Change the field type of an existing field
When is Side-by-Side Schema Evolution the Right Approach?
Side-by-Side Schema Evolution is a powerful tool to use in your production environment when the following requirements are important in your system:
- Occasional changes to an object’s fixed schema.
- No down time -- during the Side-by-Side Schema Evolution process, all services and processes using the object continue to run.
- Optimal read/write access after the schema change, with minimal memory footprint
- Support for various services deployments strategies for A/B testing and gradual deployment of new services and versions
Installation Requirements and Considerations for Side-by-Side Schema Evolution
Side-by-Side Schema Evolution is currently available for in-memory Space Documents. Support for Space Objects and for MemoryXtend![]() Related to Data Tiering. The MemoryXtend (blobstore) storage model allows an external storage medium (one that does not reside on the JVM heap) to store the GigaSpaces Space data and is designed for operational workloads. It keeps all indexes in RAM for better performance. will be added in a future release.
Related to Data Tiering. The MemoryXtend (blobstore) storage model allows an external storage medium (one that does not reside on the JVM heap) to store the GigaSpaces Space data and is designed for operational workloads. It keeps all indexes in RAM for better performance. will be added in a future release.
Since Side-by-Side Schema Evolution uses Kafka as the data messaging layer, the user must provide their own Kafka cluster. We require the Kafka connection string of the user’s existing Kafka installation.
Capacity planning should include the CPU and RAM resources to accommodate both spaces, V1 and V2 side-by-side during the Schema Evolution process.
Three Building Blocks of Side-by-Side Schema Evolution
The SpaceTypeSchemaAdapter API
This API is used to convert data from the V1 schema to the V2 schema.
public interface SpaceTypeSchemaAdapter extends Serializable {
SpaceDocument adaptEntry(SpaceDocument spaceDocument);
SpaceTypeDescriptor adaptTypeDescriptor(SpaceTypeDescriptor spaceTypeDescriptor);
String getTypeName();
}
The type adapter is implemented by the user for each type they plan to adapt. The typeName is used to fetch the specific type adapter.
In order to use it in schema evolution, the adapter(s) must be present in the CLASSPATH of the new service.
Dynamic Space Data Source Loading
The SpaceDataSource API is an existing feature that enables loading data from an external data source (database, s3 etc.) upon service deployment. (see here).
With dynamic data source loading, the service can load the data source at any given time. This API also allows an optional adaptation of the data during the loading.
The API starting point is the GigaSpacesclass, where a new asyncLoad method was introduced:
/** * Loads data from a {@Link com.gigaspaces.datasource.SpaceDataSource} on demand
* The Space data source is created with {@Link com.gigaspaces.datasource.SpaceDataSourceFactory }
* Loaded data can be adapted using the {@Link com.gigaspaces.datasource.SpaceTypeSchemaAdapter }
* @param spaceDataSourceLoadRequest {@Link SpaceDataSourceLoadRequest}
* @return A future containing the details of the Load operation affect which arrived asynchronously.
* @since 15.5.0 */
AsyncFuture<SpaceDataSourceLoadResult> asyncLoad(SpaceDataSourceLoadRequest spaceDataSourceLoadRequest);
The data load request contains two pieces of data: the connection to the data source and an (optional) collection of type adapters.
public class SpaceDataSourceLoadRequest {
private final SpaceDataSourceFactory factory;
private final Map<String,SpaceTypeSchemaAdapter> adaptersMap = new HashMap<>();
public SpaceDataSourceLoadRequest(SpaceDataSourceFactory factory) { this.factory = factory; }
public SpaceDataSourceLoadRequest addTypeAdapter(SpaceTypeSchemaAdapter typeAdapter) {
adaptersMap.put(typeAdapter.getTypeName(), typeAdapter);
return this;
}
public SpaceDataSourceFactory getFactory() { return factory; }
public Map<String, SpaceTypeSchemaAdapter> getAdaptersMap() { return adaptersMap; }
The data source connection is wrapped in the SpaceDataSourceFactory interface:
public interface SpaceDataSourceFactory extends Serializable {
SpaceDataSource create();
}
The product provides a packaged implementation for a MongoDB data source:
public class MongoSpaceDataSourceFactory implements SpaceDataSourceFactory {
private static final long seriaLVersionUID = 2696958279935086850L;
private String _db;_host;
private int _port;
Kafka Bridge Between Space and External Database
The mirror service is responsible for persisting Space data to a user-defined endpoint (database, files etc.). There is a single mirror instance per service, and data from all partitions is funneled to it.
In a regular usage of the mirror, the data is persisted directly to the user-defined endpoint. The new enhanced mirror uses Apache Kafka as a buffer between the mirror and the physical endpoint.
Apache Kafka is a highly available, scalable message-based application with parallel multi-message writes/reads (in Kafka terminology, producer/consumer). Instead of persisting Space data directly to the endpoint, data is persisted to Kafka as a Kafka message. Another mirror process is responsible for consuming the Kafka messages and persisting them to the “real” endpoint.
This enhancement provides endpoint persistence, reduced service processing time, and a smaller memory consumption. With Kafka as a buffer, failures in the physical endpoint will not affect the service functionality. This enhancement also enables stopping the endpoint persistence for extended periods of time (relevant for V1->V2 traffic redirection).
Integrating the Mirror with Kafka
Prerequisites:
- A running Kafka cluster
- A physical Space synchronization endpoint
- The gs-Kafka jar located under GS_HOME/lib/optional/Kafka should be copied to GS_HOME/lib/optional/pu-common before service deployment
- The mirror service jar should be packaged with the Kafka-clients jar
A new Kafka endpoint implementation is now part of the GigaSpacesproduct. Its bootstrap requires the Kafka cluster connection data AND the physical endpoint connection data. The physical endpoint is defined as the primary endpoint, as shown below.
<bean id="mongoClientConnector"
class="com.gigaspaces.persistency.MongoClientConnectorBeanFactory">
<property name="db" value="v1-db" />
<property name="config">
<bean id="config" class="com.mongodb.MongoClient">
<constructor-arg value="127.0.1.1" type="java.lang.String" />
<constructor-arg value="27017" type="int" />
</bean>
</property>
</bean>
<bean id="mongoSpaceSyncEndpoint"
class="com.gigaspaces.persistency.MongoSpaceSynchronizationEndpointBeanFactory">
<property name="mongoClientConnector" ref="mongoClientConnector" />
</bean>
<bean id="kafkaSpaceSynchronizationEndpoint" class="org.openspaces.persistency.kafka.KafkaSpaceSynchronizationEndpointBeanFactory" >
<property name="primaryEndpoint" ref="mongoSpaceSyncEndpoint"/>
<property name="kafkaBootstrapServers" value="127.0.1.1:9092"/>
<property name="topic" value="v1-space-topic"/>
</bean>
On service deployment, Space data will be written as Kafka messages to a newly-created Kafka topic called “<service-name>-topic”. The consumption process will consume the message of this topic, and write them to the primary endpoint.
Pausing the Primary Endpoint
As discussed above, the Kafka mirror allows pausing persistence to the primary endpoint without performance penalty. This pause/resume is done by manually undeploying the mirror service and deploying an new mirror service with the following configuration:
<bean id="kafkaSpaceSynchronizationEndpoint" class="org.openspaces.persistency.kafka.KafkaSpaceSynchronizationEndpointBeanFactory" >
<property name="primaryEndpoint" ref="TopgoSpaceSyncEndpoint",-->
<property name="kafkaBootstrapServers" value="127.0.1.1:9092"/>
<property name="topic" value="v1-space-topic"/>
</bean>
By commenting out the primary endpoint, space data will be persisted only to Kafka. To resume primary endpoint persistence, one should just redeploy the original mirror service.
Kafka Mirror with Multiple Synchronization Endpoints
In the Kafka synchronization endpoint, the user can add secondary persistence endpoints. Each endpoint starts a new consumer process that consumes the mirror messages and persists them to the endpoint. By design, each secondary endpoint persists data from the last message persisted to the primary endpoint, which means it doesn’t consume all previous messages.
The final building block of SE is the new GigaSpaceSynchronizationEndpoint implementation. In this implementation, the Space acts as a persistence endpoint to another service. The implementation also allows data to be adapted before writing it to the Space endpoint. After deployment, traffic from the source service will be replicated and adapted to the target service, including write, update and removal of entries.
Configuration of the Endpoint
Configuration uses the following information:
- The Space name (required)
- A collection of zero or n custom type adapters that adapt source service types (optional)
- Target service lookup groups (optional)
<bean id="targetSpaceEndpoint"
class="org.openspaces.persistency.space.GigaSpaceSynchronizationEndpointBeanFactory">
<property name="targetSpaceName" value="myTargetSpace" />
<property name="lookupGroups" value="my-lookup-group" />
<property name="lookupLocators" value="localhost:4174" />
<property name="spaceTypeSchemaAdapters">
<util:list>
<ref bean="personDocumentSchemaAdapter"/>
</util:list>
</property>
</bean>
How to Implement Side-by-Side Schema Evolution
- Starting point: A long running service with mirror persistence (referred to as V1).
- Finishing point:
- A new service running side-by-side with the long running service (referred to as V2).
- All of the old data has been loaded and adapted to the new service.
Summary of Flow:
- Enhancing V1 mirror service with kafka bridge
- Temporarily disabling V1 primary persistence endpoint
- Loading V1 primary endpoint to V2, adapting the data on loading
- Using Kafka and the GigaSPaceSynchronizationEndpoint API to replicate and adapt V1 traffic to V2.
Prerequisites:
- An available Apache Kafka cluster
- An implementation of SpaceTypeSchemaAdapter for each evolved type found in the running service
Step 1: Initial Load of Database with Schema V2
In this step, data from the original database (with schema V1) is copied to database with schema V2. During this copy process, each row of data from schema V1 is transformed to the format of schema V2.
During the initial load process, any new data written to the schema V1 database is saved in the Kafka buffer.
- Deploy the V2 service, packaged with the type adapter implementations.
- If V1 mirror service is not using Kafka as a bridge, undeploy the existing mirror.
- Redeploy the mirror enhanced with Kafka, with the persistence endpoint defined as thethe disabled (paused) primary endpoint - see Data Types, Schema Types and Schema Evolution.
- This will result in space data persisted only to Kafka. This is only a temporary situation.
- With the primary endpoint disabled, it is possible to perform the dynamic space data source loading from V1 primary endpoint to V2 service. (put link to this feature section)
The result of this flow is explained in the diagram below.
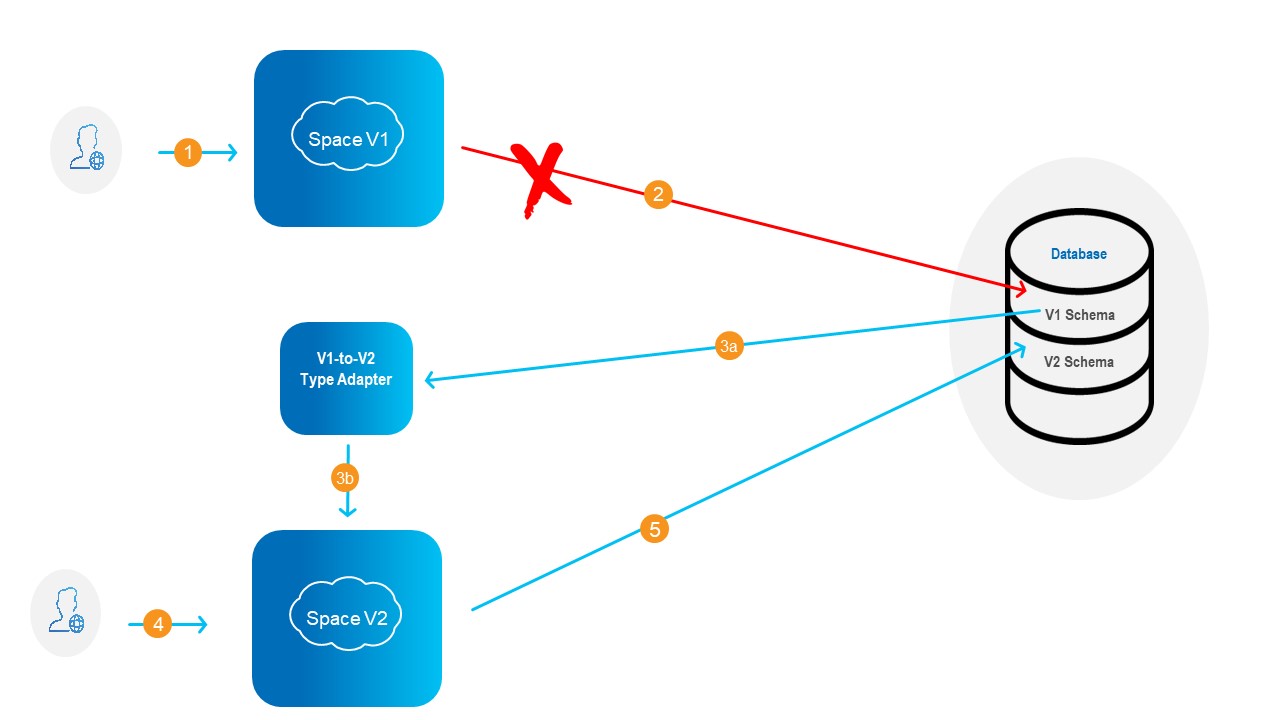
- Client interacts with Space V1.
The client continues to interact with Space V1 during this initial load process. Space V1 is continuously available. - Paused -- Updates to database with schema V1 are captured by Kafka but not used to update the database at this time.
This data will be written to database with schema V1 and database with schema V2, after the initial load is complete. - Data is loaded (copied) from database with schema V1 to Space V2, undergoing a transformation via the Type Adapter..
- Client interacts with Space V2.
The client continues to interact with Space V2 during this initial load process. Space V2 is continuously available. - Data changes from Space V2 are mirrored into database with schema V2.
Step 2: Transition to Steady-State with Schema V1 and Schema V2
- Undeploy the temporary mirror used in the previous step.
- Deploy the final, steady-stateV1 mirror service, with the following configuration:
- The primary endpoint is re-enabled (unpaused)
- The V2 space defined as a secondary endpoint, using the GigaSpaceSynchronizationEndpoint (put link to section). Naturally, all the type adapters are included in the secondary endpoint configuration.
- Once final mirror is deployed, all V1 traffic will be replicated and adapted to V2.
This is illustrated in the diagram below.
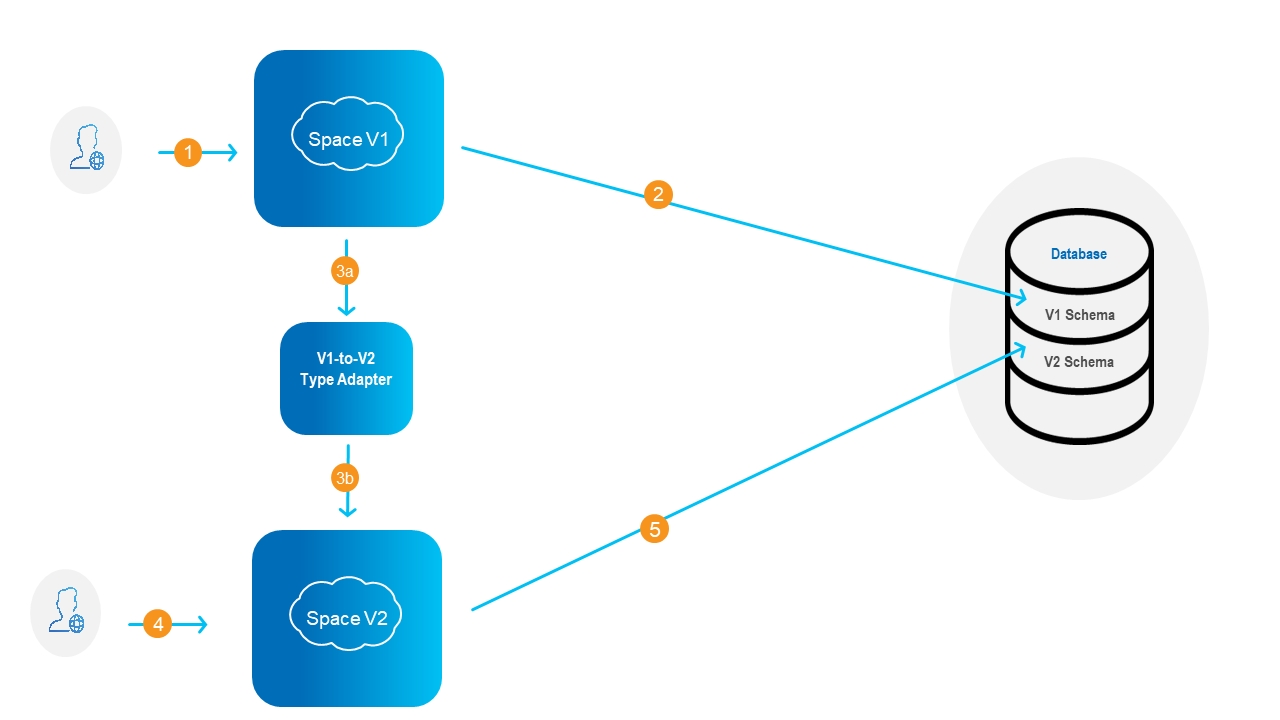
- Client interacts with stateful service (i.e. service that contains a space).
- Data changes from space V1 are mirrored into database with schema V1.
- Data changes are streamlined into service V2, using a user-defined Type Adapter.
- Client interacts with service V2.
- Data changes from space V2 are mirrored into database with schema V2.