XAP
XAP Overview
Introduction
XAP![]() GigaSpaces eXtreme Application Platform.
Provides a powerful solution for data processing, launching, and running digital services is GigaSpaces high-speed, distributed in-memory data storage and processing grid. The platform co-locates applications and data, offering ultra-low latency, high-throughput transaction and stream processing. XAP offers unique capabilities that are not available in simple caching solutions, such as full SQL compatibility, mufti-criteria queries, dynamic server-side processing, full data integrity and policy-driven data tiering.
GigaSpaces eXtreme Application Platform.
Provides a powerful solution for data processing, launching, and running digital services is GigaSpaces high-speed, distributed in-memory data storage and processing grid. The platform co-locates applications and data, offering ultra-low latency, high-throughput transaction and stream processing. XAP offers unique capabilities that are not available in simple caching solutions, such as full SQL compatibility, mufti-criteria queries, dynamic server-side processing, full data integrity and policy-driven data tiering.
XAP provides a highly-reliable, distributed, in-memory storage and processing engine. Essentially, it is an in-memory data grid designed to support millisecond-level latency and millions of operations per second, providing for thousands of services, and hundreds to thousands of concurrent users. This solution makes the implementation of distributed applications above the Space simpler and less intrusive, enabling efficient building of highly scalable and highly performing applications.
Architecture
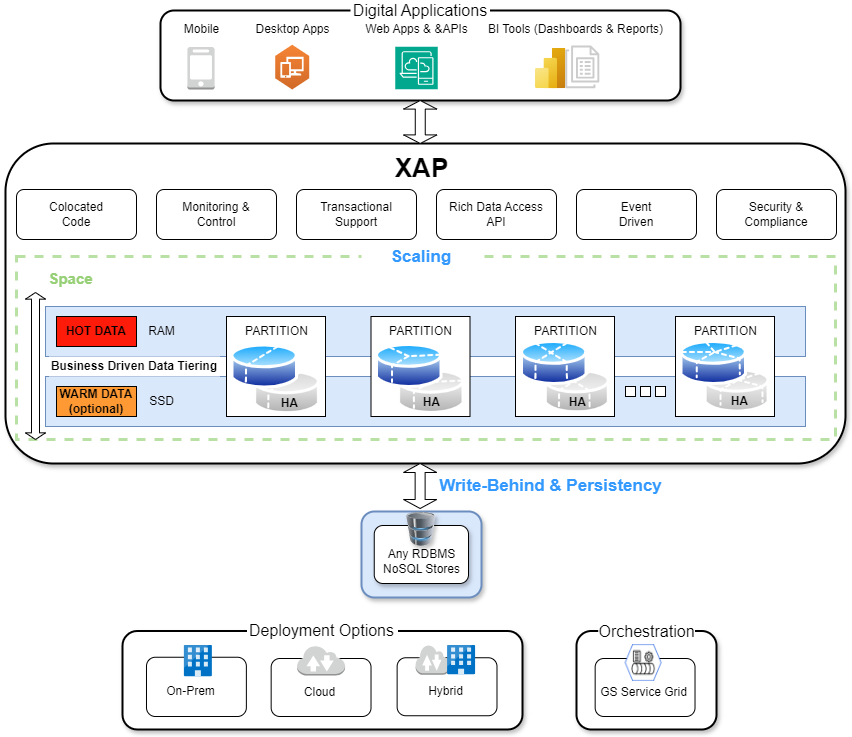
Architecture of XAP
Refer to our XAP and XAP Skyline![]() A highly customizable developer platform that allows building scalable HA with high throughput and ultra-low latency Java applications running on Kubernetes clusters functionality page for more details.
A highly customizable developer platform that allows building scalable HA with high throughput and ultra-low latency Java applications running on Kubernetes clusters functionality page for more details.
XAP offers:
-
High availability, replication and persistence with optional data persistence and multi-datacenter replication
-
Full data life-cycle management on RAM, SSD/Flash and external data stores, also supporting data tiering: hot (in memory) and warm (SSD).
-
Supports an unlimited number of advanced indexes such as Exact, Range, Collections, Compound, Text, and Geospatial for optimal performance together with full SQL-99 coverage. Unlike key-value stores that may need to duplicate the entire data store for each defined index, XAP only creates additional indexing data structures on one instance of data.
-
Ensures data consistency and reliability across distributed environments by employing ACID
 In the context of databases and data storage systems, a transaction is any operation that is treated as a single unit of work, which either completes fully or does not complete at all, and leaves the storage system in a consistent state.
ACID is an acronym that refers to the set of 4 key properties that define a transaction: Atomicity, Consistency, Isolation, and Durability. If a database operation has these ACID properties, it can be called an ACID transaction.-compliant transactions to maintain data integrity.
In the context of databases and data storage systems, a transaction is any operation that is treated as a single unit of work, which either completes fully or does not complete at all, and leaves the storage system in a consistent state.
ACID is an acronym that refers to the set of 4 key properties that define a transaction: Atomicity, Consistency, Isolation, and Durability. If a database operation has these ACID properties, it can be called an ACID transaction.-compliant transactions to maintain data integrity. For information about ACID compliance, read our blog on How to Achieve ACID Compliance on Distributed, Highly Available Systems.
-
Supports a variety of data models, including POJO, Documents, and Key/Value
-
Seamlessly scales up and out with no downtime when the Space
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. is H/A. -
Can be deployed on-premises, in the cloud, or in a hybrid environment using its own service grid orchestration
This is the automated configuration, management, and coordination of computer systems, applications, and services. Orchestration strings together multiple tasks in order to execute and easily manage a larger workflow or process. These processes can consist of multiple complex tasks that are automated and can involve multiple systems. Kubernetes, used by GigaSpaces, is a popular open source platform for container orchestration. mechanism -
Easily integrates with BI tools.
XAP runs server side processing, providing the high performance of advanced operations and avoiding data retrieval back to the client side. Aggregation is performed in-memory, on relevant data only, regardless of total data size. It uses Space-Based Architecture (SBA![]() Space-Based Architecture.
This architecture implementation is a set of Processing Units, with the following properties: Each processing unit instances holds a partitioned space instance and one or more services that are registered on events on that specific partition. Together they form an application cluster. Utlized by Utilized GigaSpaces cloud-native IMDG.) as a primary design pattern. With SBA, applications are built out of a set of self-sufficient units, known as Processing Units (PU
Space-Based Architecture.
This architecture implementation is a set of Processing Units, with the following properties: Each processing unit instances holds a partitioned space instance and one or more services that are registered on events on that specific partition. Together they form an application cluster. Utlized by Utilized GigaSpaces cloud-native IMDG.) as a primary design pattern. With SBA, applications are built out of a set of self-sufficient units, known as Processing Units (PU![]() This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity.). These units are completely independent of each other, so that an application can scale without increasing complexity, just by adding more units. SBA is based on the Tuple Space paradigm. SBA follows many of the principles of Service-Oriented Architecture and Event-Driven Architecture, as well as elements of grid computing.
This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity.). These units are completely independent of each other, so that an application can scale without increasing complexity, just by adding more units. SBA is based on the Tuple Space paradigm. SBA follows many of the principles of Service-Oriented Architecture and Event-Driven Architecture, as well as elements of grid computing.