GigaSpaces Ops Manager
For more information see the Ops Manager section in our User Guide.
The GigaSpaces Ops Manager is an enterprise-grade management platform that can be implemented for GigaSpaces-based applications across on-premise, cloud, and Kubernetes![]() An open-source container orchestration system for automating software deployment, scaling, and management of containerized applications. environments. Ops Manager is a robust web interface that provides visibility and real-time information about your GigaSpaces clusters and their services. It enables you to better monitor your clusters, and perform troubleshooting activities by analyzing various performance metrics, and reviewing alerts with defined thresholds. You can drill down to the partition level and create dump files, to review service log files for root-cause analysis.
An open-source container orchestration system for automating software deployment, scaling, and management of containerized applications. environments. Ops Manager is a robust web interface that provides visibility and real-time information about your GigaSpaces clusters and their services. It enables you to better monitor your clusters, and perform troubleshooting activities by analyzing various performance metrics, and reviewing alerts with defined thresholds. You can drill down to the partition level and create dump files, to review service log files for root-cause analysis.
In addition to real-time monitoring and troubleshooting capabilities, Ops Manager enables you to review and analyze data that resides within the cluster. Use Ops Manager to review Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model.-related information, such as object types and properties, and execute various queries as part of data discovery.
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model.-related information, such as object types and properties, and execute various queries as part of data discovery.
Accessing Ops Manager in a Secure Environment
When using role-based authentication, Ops manager uses three properties to authenticate the user and allow access to Ops manager functions
- User name
- Password
- Role
The set of features available depends on the role assigned to the user:
- Admin (superuser) – has access to all capabilities, including features related to service orchestration
 This is the automated configuration, management, and coordination of computer systems, applications, and services. Orchestration strings together multiple tasks in order to execute and easily manage a larger workflow or process. These processes can consist of multiple complex tasks that are automated and can involve multiple systems. Kubernetes, used by GigaSpaces, is a popular open source platform for container orchestration., that have a high impact on the environment and resource consumption (e.g. scale up/down of service partitions).
This is the automated configuration, management, and coordination of computer systems, applications, and services. Orchestration strings together multiple tasks in order to execute and easily manage a larger workflow or process. These processes can consist of multiple complex tasks that are automated and can involve multiple systems. Kubernetes, used by GigaSpaces, is a popular open source platform for container orchestration., that have a high impact on the environment and resource consumption (e.g. scale up/down of service partitions). - Manager – deploys services and connects with client applications and other components such as databases, ETL Extract, Transform, Load
The process of combining data from multiple sources into a large, central repository. In GigaSpaces this is the Space.’s etc. A manager will deploy and test for the proper function and performance. A manager may also analyze the data behavior within the Space.
- Viewer – data expert with a goal to view, interact with and query the data.
See GigaSpaces Ops Manager Authorization for details on system features that are available based on the user role.
When using role-based authentication, Ops Manager initially displays a login screen:
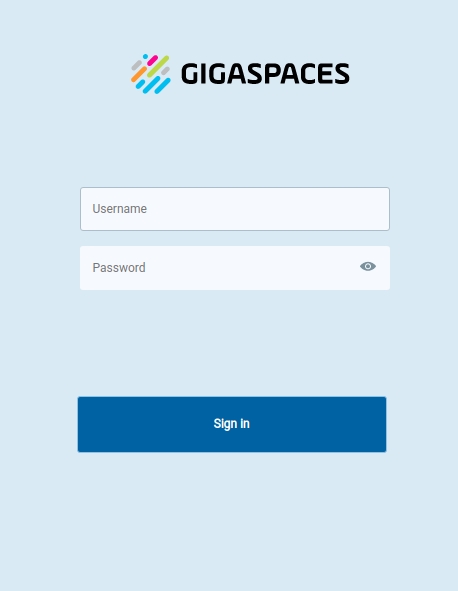
Enter a value user name and password, and press Sign In.
See Security Concepts for details on setting up users and passwords.
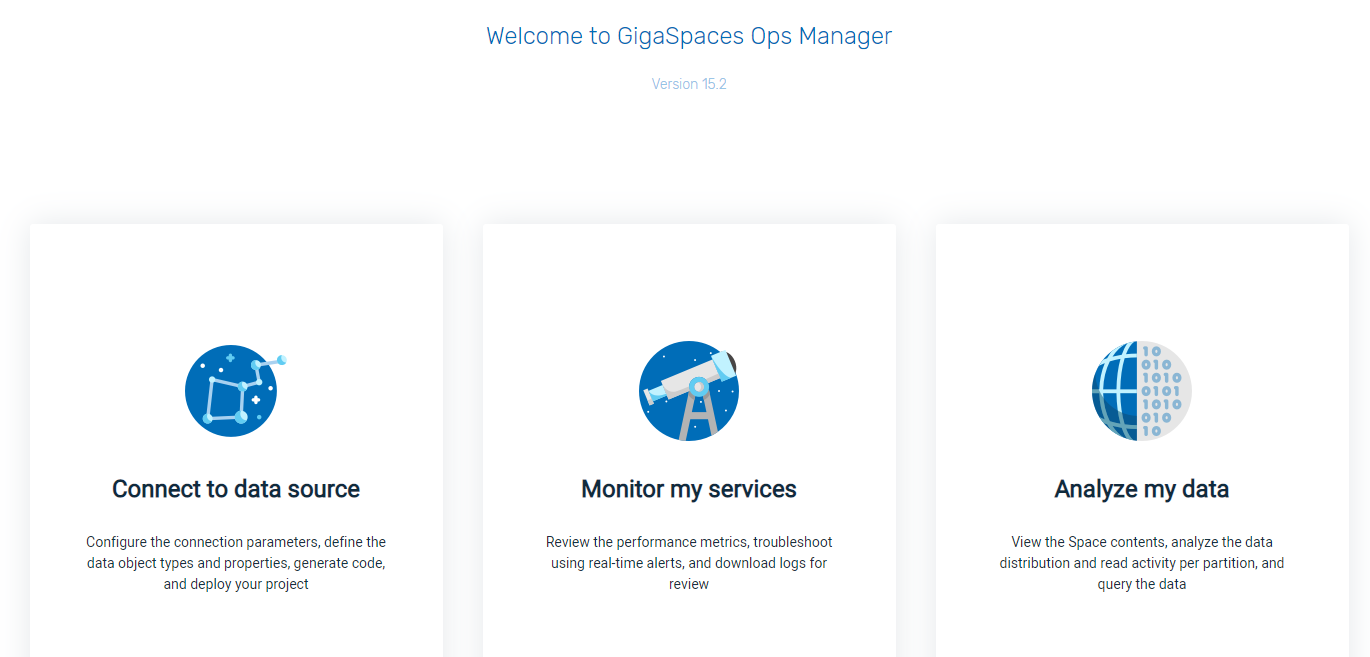
Ops Manager Features
The Ops Manager allows you to perform the basic functions of GigaSpaces using an intuitive, GUI-based interface.
The user can perform the following functions:
Connect to a Data Source — Connect XAP![]() GigaSpaces eXtreme Application Platform.
Provides a powerful solution for data processing, launching, and running digital services and XAP Skyline
GigaSpaces eXtreme Application Platform.
Provides a powerful solution for data processing, launching, and running digital services and XAP Skyline![]() A highly customizable developer platform that allows building scalable HA with high throughput and ultra-low latency Java applications running on Kubernetes clusters to a traditional SQL database or data warehouse and load the selected data. Use the generated Blueprint
A highly customizable developer platform that allows building scalable HA with high throughput and ultra-low latency Java applications running on Kubernetes clusters to a traditional SQL database or data warehouse and load the selected data. Use the generated Blueprint![]() Java project templating framework provided by DIH for developers, a bueprint, or class, contains a set of attributes and behaviors that define an object. to deploy the Space application with its configuration to the XAP and XAP Skyline data platforms.
Java project templating framework provided by DIH for developers, a bueprint, or class, contains a set of attributes and behaviors that define an object. to deploy the Space application with its configuration to the XAP and XAP Skyline data platforms.
Monitor my services — Review the real-time performance of the system, and enable an IT administrator or developer to easily monitor the health of all its service types. Receive real-time availability and resource alerts immediately when they appear.
Analyze my data — Enables an IT administrator or developer to review the Space data, drill down to its object types and analyze the data by executing queries using the SQL editor.
Accessing Ops Manager
The Ops Manager is deployed along with the Manager and the REST![]() REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style. Manager API, and uses the same entry point. In order to open Ops Manager in your browser and view your GigaSpaces environment, you need to access the Manager's IP address on port 8090, or use localhost if your environment is deployed on a local agent.
REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style. Manager API, and uses the same entry point. In order to open Ops Manager in your browser and view your GigaSpaces environment, you need to access the Manager's IP address on port 8090, or use localhost if your environment is deployed on a local agent.
If you had a previous version of GigaSpaces, when you used the Manager IP address and port in the URL field of your browser to access the REST Manager API (http://<MANAGER_IP>:8090/), you were automatically redirected to http://<MANAGER_IP>:8090/v2. This information may be stored in your browser cache and prevent you from opening Ops Manager. If this occurs, clear your browser cache to enable access to Ops Manager. If you want to open the REST Manager API, use the http://<MANAGER_IP>:8090/v2 URL.
If you aren't familiar with general GigaSpaces terminology, see the General Terms and Concepts topic in the Product Overview.