Data Integration (DI) Layer
Data Integration![]() The Data Integration (DI) layer is a vital part of the Digital Integration Hub (DIH) platform. It is responsible for a wide range of data integration tasks such as ingesting data in batches or streaming data changes. This is performed in real-time from various sources and systems of record (SOR. The data then resides in the In-Memory Data Grid (IMDG), or Space, of the GigaSpaces Smart DIH platform. (DI
The Data Integration (DI) layer is a vital part of the Digital Integration Hub (DIH) platform. It is responsible for a wide range of data integration tasks such as ingesting data in batches or streaming data changes. This is performed in real-time from various sources and systems of record (SOR. The data then resides in the In-Memory Data Grid (IMDG), or Space, of the GigaSpaces Smart DIH platform. (DI![]() The Data Integration (DI) layer is a vital part of the Digital Integration Hub (DIH) platform. It is responsible for a wide range of data integration tasks such as ingesting data in batches or streaming data changes. This is performed in real-time from various sources and systems of record (SOR. The data then resides in the In-Memory Data Grid (IMDG), or Space, of the GigaSpaces Smart DIH platform.) is the gateway for incoming data into the Data Integration Hub (DIH
The Data Integration (DI) layer is a vital part of the Digital Integration Hub (DIH) platform. It is responsible for a wide range of data integration tasks such as ingesting data in batches or streaming data changes. This is performed in real-time from various sources and systems of record (SOR. The data then resides in the In-Memory Data Grid (IMDG), or Space, of the GigaSpaces Smart DIH platform.) is the gateway for incoming data into the Data Integration Hub (DIH![]() Digital Integration Hub.
An application architecture that decouples digital applications from the systems of record, and aggregates operational data into a low-latency data fabric.) system. The DI components are delivered as part of the GigaSpaces DIH Package.
Digital Integration Hub.
An application architecture that decouples digital applications from the systems of record, and aggregates operational data into a low-latency data fabric.) system. The DI components are delivered as part of the GigaSpaces DIH Package.
DI contains four components which are responsible for reading and analyzing Kafka![]() Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. messages and for pushing them into the Space
Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. messages and for pushing them into the Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model..
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model..
DI Layer Overview
The DI Module is illustrated as follows:
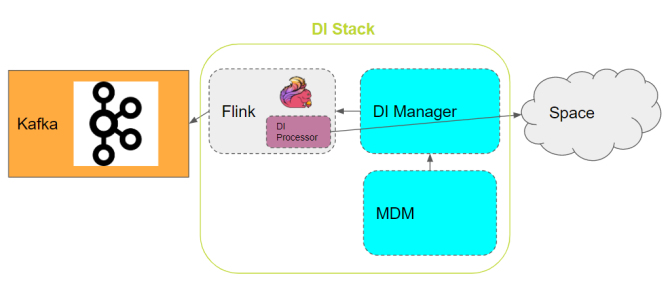
1. Apache Flink
GigaSpaces uses Apache Flink![]() Apache Flink is an open-source, unified stream-processing and batch-processing framework developed by the Apache Software Foundation. The core of Apache Flink is a distributed streaming data-flow engine written in Java and Scala. Flink executes arbitrary dataflow programs in a data-parallel and pipelined manner. as it is an open source framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink is designed to run in all common cluster environments, performing computations at in-memory speed and at any scale. It is also a powerful and fast framework for stream processing. It also allows deployment of different types of applications at run-time. In addition, Flink supports streaming and batch mode, which is useful for periodic batch updates. One of the most common types of applications that are powered by Flink are Data Pipeline
Apache Flink is an open-source, unified stream-processing and batch-processing framework developed by the Apache Software Foundation. The core of Apache Flink is a distributed streaming data-flow engine written in Java and Scala. Flink executes arbitrary dataflow programs in a data-parallel and pipelined manner. as it is an open source framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink is designed to run in all common cluster environments, performing computations at in-memory speed and at any scale. It is also a powerful and fast framework for stream processing. It also allows deployment of different types of applications at run-time. In addition, Flink supports streaming and batch mode, which is useful for periodic batch updates. One of the most common types of applications that are powered by Flink are Data Pipeline![]() A series of data processing steps, including extraction, transformation, and loading (ETL), that move data from its source to a destination system. Data pipelines are essential for integrating and managing data flows. Applications, which is why we chose to use it in our Smart DIH
A series of data processing steps, including extraction, transformation, and loading (ETL), that move data from its source to a destination system. Data pipelines are essential for integrating and managing data flows. Applications, which is why we chose to use it in our Smart DIH![]() Smart DIH allows enterprises to develop and deploy digital services in an agile manner, without disturbing core business applications. This is achieved by creating an event-driven, highly performing, efficient and available replica of the data from multiple systems and applications, solution.
Smart DIH allows enterprises to develop and deploy digital services in an agile manner, without disturbing core business applications. This is achieved by creating an event-driven, highly performing, efficient and available replica of the data from multiple systems and applications, solution.
Extract transform load (ETL![]() Extract, Transform, Load
The process of combining data from multiple sources into a large, central repository. In GigaSpaces this is the Space.) is a common approach used to convert and move data between storage systems. Often, ETL jobs are periodically triggered to copy data from transactional database systems to an analytical database or data warehouse. Data pipelines serve a similar purpose as ETL jobs in that they transform and enrich data and can move it from one storage system to another, However, they operate in a continuous streaming mode instead of being periodically triggered.
Extract, Transform, Load
The process of combining data from multiple sources into a large, central repository. In GigaSpaces this is the Space.) is a common approach used to convert and move data between storage systems. Often, ETL jobs are periodically triggered to copy data from transactional database systems to an analytical database or data warehouse. Data pipelines serve a similar purpose as ETL jobs in that they transform and enrich data and can move it from one storage system to another, However, they operate in a continuous streaming mode instead of being periodically triggered.
Additional Information: Apache Flink.
2. Metadata Manager (MDM)
The Metadata Manager (MDM) is a stateful data service which communicates with external components via REST APIs![]() REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style.. It can be deployed as a standalone application. It uses Zookeeper
REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style.. It can be deployed as a standalone application. It uses Zookeeper![]() Apache Zookeeper. An open-source server for highly reliable distributed coordination of cloud applications. It provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. The goal is to make these systems easier to manage with improved, more reliable propagation of changes. (ZK) as a persistent data store.
Apache Zookeeper. An open-source server for highly reliable distributed coordination of cloud applications. It provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. The goal is to make these systems easier to manage with improved, more reliable propagation of changes. (ZK) as a persistent data store.
Functionality
The MDM stores, edits and retrieves information for the following:
-
The source table structure
-
The structure mapping to the space type
-
The data types conversion maps
-
The configurations of the DI Manager and Pipeline, which are DI layer components
-
The created and dropped types in the Space
The MDM refreshes its metadata on-demand from sources into the MDM data store (ZK). The MDM compares and repairs stored metadata against created objects and in Space. The MDM also provides information about stored metadata over REST![]() REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style. to the UI and DI Manager.
REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style. to the UI and DI Manager.
3. DI Processor
The DI Processor is a Java library deployed to the Flink cluster. It is operated by the Flink Task Manager and is part of the Flink job. It is used to process Kafka messages and automatically identifies the consumed message format based on a pluggable CDC template. It converts messages into a Space document and writes the Space document to the Space.
Flow
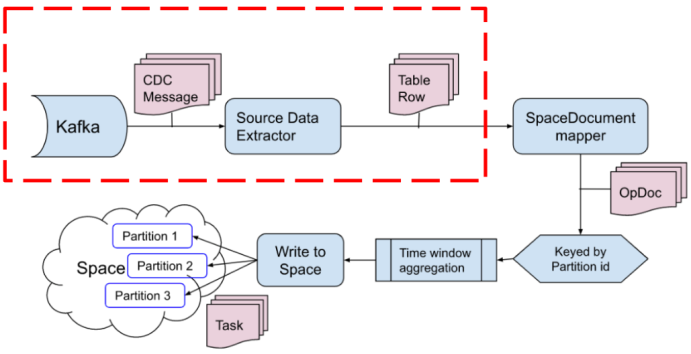
-
Parsing Kafka messages
-
Determining source table information
-
Determining CDC operation type (INSERT, UPDATE or DELETE)
-
Extracting all column data from the parsed message.
Extraction information is provided by MDM service
Extraction information includes names of attributes, their types and json path used to extract the values
-
Storing extracted data as table row (e,g, Flink Row for interoperability)
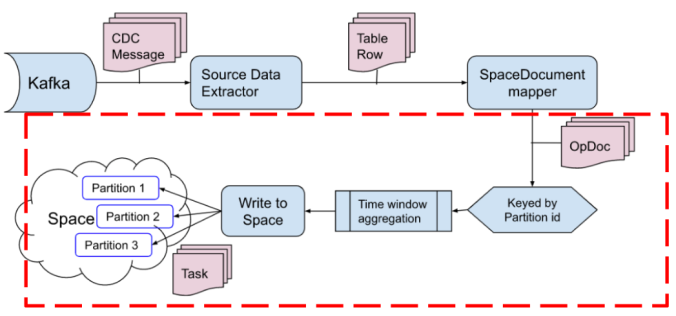
The SpaceDocumentMapper is responsible for converting the table row into corresponding SpaceDocuments which is stored in the OpDoc entity together with the operation type.
The conversion is performed according to the source table name. Multiple types of SpaceDocuments can be generated from a single table row.
Conversion may include:
-
Mapping of row column name to the space document attribute name
-
Conversion of types
-
Non-trivial transformations
-
Calculated expressions
OpDoc
The OpDoc entity contains the following information:
-
Operation (insert, delete or update)
-
Space Document
-
Partition ID
-
Transaction ID
Example:

Keyed by partition id
This is the process that attached a space partition ID to each OpDoc according to the SpaceType routing definition.
Time window aggregation
The process aggregates all OpDocs received during a certain time period for efficient space write operation.
Write to Space
At this phase, all aggregated OpDocs are written to the appropriate partition in space asynchronously using the space task execute mechanism.
4. DI Manager
The DI manager is an interface for communicating with Flink. It also communicates with external components such as UI and MDM via REST API. In addition, the DI Manager retrieves a correct schema and tables structure from a Source of Record (SOR![]() System of Record. This is an information storage and retrieval system that stores valuable data on an organizational system or process. This record can contain multiple data sources and exist at a single location or multiple locations with remote access.) and stores it in the MDM.
System of Record. This is an information storage and retrieval system that stores valuable data on an organizational system or process. This record can contain multiple data sources and exist at a single location or multiple locations with remote access.) and stores it in the MDM.
The DI Manager-Flink operations are:
-
Creating, editing and dropping Flink jobs
-
Starting and stopping Flink jobs
-
Getting Flink's job status