Global vs. Local LUS
This page is irrelevant for GigaSpaces Manager; it explains how to setup multiple LUSs manually to achieve high availability. This technique is still supported, but outdated, and will be phased out in the future. It's highly recommended to use the Manager instead, which is both easier to use and provides superior high availability.
Global LUS
When you would like to have a fully dynamic elastic environment where the lookup service (LUS![]() Lookup Service.
This service provides a mechanism for services to discover each other. Each service can query the lookup service for other services, and register itself in the lookup service so other services may find it.) may be running on any machine on the network to serve multiple LUS machine failure (for existing machines or to be started in the future) you should consider using the global LUS setup.
Lookup Service.
This service provides a mechanism for services to discover each other. Each service can query the lookup service for other services, and register itself in the lookup service so other services may find it.) may be running on any machine on the network to serve multiple LUS machine failure (for existing machines or to be started in the future) you should consider using the global LUS setup.
With the global LUS setup you should rely on multicast lookup discovery mechanism to locate running lookup services. This discovery process executed by the service grid components (GSC![]() Grid Service Container.
This provides an isolated runtime for one (or more) processing unit (PU) instance and exposes its state to the GSM. , GSM
Grid Service Container.
This provides an isolated runtime for one (or more) processing unit (PU) instance and exposes its state to the GSM. , GSM![]() Grid Service Manager.
This is is a service grid component that manages a set of Grid Service Containers (GSCs). A GSM has an API for deploying/undeploying Processing Units. When a GSM is instructed to deploy a Processing Unit, it finds an appropriate, available GSC and tells that GSC to run an instance of that Processing Unit. It then continuously monitors that Processing Unit instance to verify that it is alive, and that the SLA is not breached.) - configured via the
Grid Service Manager.
This is is a service grid component that manages a set of Grid Service Containers (GSCs). A GSM has an API for deploying/undeploying Processing Units. When a GSM is instructed to deploy a Processing Unit, it finds an appropriate, available GSC and tells that GSC to run an instance of that Processing Unit. It then continuously monitors that Processing Unit instance to verify that it is alive, and that the SLA is not breached.) - configured via the GS_LOOKUP_GROUPS environment variable) or client applications when constructing their data grid proxy - configured via the groups URL String (i.e. jini://*/*/DataGridName?groups=myGroup) or lookup-groups spring property as part of the pu.
Another alternative is to use unicast based lookup discovery and specify with the ![]() This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity..xml
This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity..xmlGS_LOOKUP_LOCATORS environment variable all existing and future machines that are running/may be running the LUS. Same with the space Url on the client side (i.e. jini://LUS_HOST1,LUS_HOST2/*/DataGridName). In most cases its much simpler to use the multicast lookup discovery mechanism.
With the global LUS setup you should have two LUSs running across your service grid - these are running in active-active configuration. This means all agents are equal with their setup. They will be communicating with each other to preserve the exact amount of specified LUSs. Once a running LUS failed (as a result of machine termination, or LUS process failure) , a different agent that is not currently running a LUS will be starting a LUS to enforce the SLA specified at the agent startup. The timeout space URL property (i.e. jini://*/*/DataGridName?timeout=10000) or lookup-timeout Spring property with the pu.xml allows you to specify the LUS multicast discovery timeout.
Global Setup Example
With the following example we have Machine A, Machine B, Machine C and Machine D running the service grid.
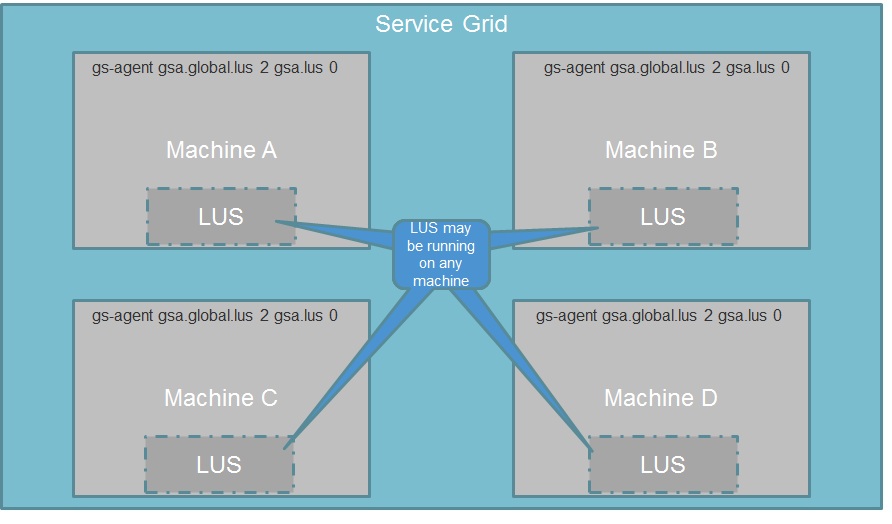
All agents are started with the same command instructing them to maintain two global LUSs across the entire service grid:
gs-agent --global.lus=2
Upon startup the agents will decide which ones will run a LUS and which won't.
To enable this dynamic setup you should have multicast enabled between all service grid machines and also between client applications machines and service grid machines. To differentiate between different service grids running on the same network you should specify a unique GS_LOOKUP_GROUPS environment variable value for the service grid machines before starting the agent. The client application should specify the right group via the URL (i.e. jini://*/*/DataGridName?groups=myGroup) or via the lookup-groups spring property as part of the pu.xml.
Local LUS
With the local lookup service setup you should specify a list of known machines to run the LUS. This list (two recommended) should be configured on the service grid via the GS_LOOKUP_LOCATORS environment variable (comma delimited) and also with the client application space URL (i.e. jini://LUS_HOST1, LUS_HOST2/*/DataGridName) or via the lookup-locators Spring property .
Local Setup Example
With the following example we have Machine A, Machine B, Machine C and Machine D running the service grid. We would like to start two LUSs across these machines. We have decided that Machine A and Machine D will be running a LUS.
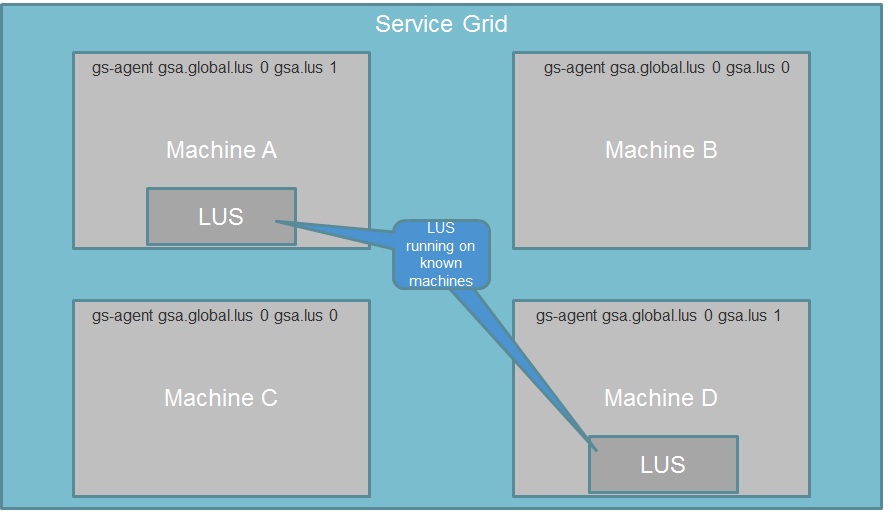
The agent on these machines will be started using the following:
gs-agent --lus=1
Machine B and Machine C will not run the lookup service. The agent on the machines will be started using the following:
gs-agent
Upon startup the only Machine A and Machine D agent's that are configured to start a local LUS will have it running. In case of Machine A or Machine D failure the system will have a single LUS. Service Grid![]() A built-in orchestration tool which contains a set of Grid Service Containers (GSCs) managed by a Grid Service Manager. The containers host various deployments of Processing Units and data grids. Each container can be run on a separate physical machine. This orchestration is available for XAP only. components (GSC , GSM) and client applications will keep looking for this missing LUS internally (configured via the
A built-in orchestration tool which contains a set of Grid Service Containers (GSCs) managed by a Grid Service Manager. The containers host various deployments of Processing Units and data grids. Each container can be run on a separate physical machine. This orchestration is available for XAP only. components (GSC , GSM) and client applications will keep looking for this missing LUS internally (configured via the com.gigaspaces.unicast.interval system property).
Once the missing LUS machine will be restarted they will reconnect. With a network running a DNS - you may start a new machine with the same Host name to support total machine failure while keeping number of running LUSs intact.