Tiered Storage Overview
The goal of Tiered Storage![]() Automatically assigns data to different categories of storage types based on considerations of cost, performance, availability, and recovery. is to offer a cost-effective solution for storing large amounts of data while balancing cost with read/write performance. Data is divided into two logical layers or 'tiers'. By abstracting the complexity of tiered storage management, developers can focus on building and optimizing their applications without concern for the specifics of data placement and performance tuning.
Automatically assigns data to different categories of storage types based on considerations of cost, performance, availability, and recovery. is to offer a cost-effective solution for storing large amounts of data while balancing cost with read/write performance. Data is divided into two logical layers or 'tiers'. By abstracting the complexity of tiered storage management, developers can focus on building and optimizing their applications without concern for the specifics of data placement and performance tuning.
Feature Overview
Data can be stored in two tiers. By strategically dividing data between these two tiers, Tiered Storage optimizes both performance and cost, ensuring that critical data operations are executed efficiently while maintaining overall storage expenses at a manageable level.
| Tier | Storage Location | Details |
|---|---|---|
| Hot | RAM |
This tier is designed for high-speed access. It stores data that should be accessed fast according to business requirement ensuring low latency and high throughput for read operations. |
| Warm | Disk | This tier is intended for data that is accessed less frequently. While it offers slower access times compared to the Hot Tier |
Typically, the Warm Tier![]() Part of GigaSpaces Tiered Storage Mechanism. Warm tier is SSD (recommended media) storage which is mostly used for data that is read-only and is less frequently used. contains all the data, while the Hot Tier holds a subset based on user-defined rules. The Warm Tier also acts as the persistence layer for all data. The distribution of data across these tiers is handled based on predefined rules and is seamless to client applications. Applications access data in both tiers via standard APIs, without needing to be aware of the tiered structure.
Part of GigaSpaces Tiered Storage Mechanism. Warm tier is SSD (recommended media) storage which is mostly used for data that is read-only and is less frequently used. contains all the data, while the Hot Tier holds a subset based on user-defined rules. The Warm Tier also acts as the persistence layer for all data. The distribution of data across these tiers is handled based on predefined rules and is seamless to client applications. Applications access data in both tiers via standard APIs, without needing to be aware of the tiered structure.
-
Data Distribution: The system transparently manages the placement of data between the Hot and Warm Tiers based on predefined rules. This ensures that the most critical data is readily accessible in the Hot Tier, while the full dataset remains stored in the Warm Tier.
-
Seamless Integration: Client applications interact with the data storage system using standard APIs. This abstraction means that applications do not need to be aware of the underlying tiered storage architecture. Whether data resides in RAM or on disk, the access and manipulation of data remain consistent and straightforward from the application's perspective.
Architectural Overview
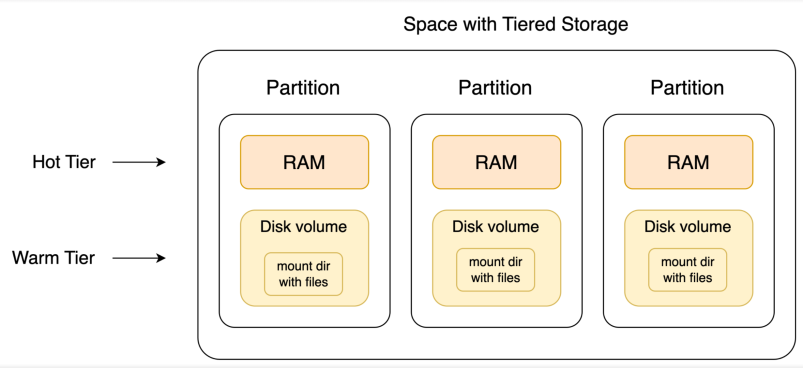
In Tiered Storage, space data partitioning adheres to the standard methodology. Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. objects and documents are routed to partitions based on the routing
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. objects and documents are routed to partitions based on the routing![]() The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. key property value. Partitions not only manage data in RAM but also on disk volumes. Consequently, within a Space partition, an object can reside in RAM, on disk, or in both locations. This dual-layered storage approach ensures efficient data management and access within each partition.
The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. key property value. Partitions not only manage data in RAM but also on disk volumes. Consequently, within a Space partition, an object can reside in RAM, on disk, or in both locations. This dual-layered storage approach ensures efficient data management and access within each partition.
Kubernetes Environments
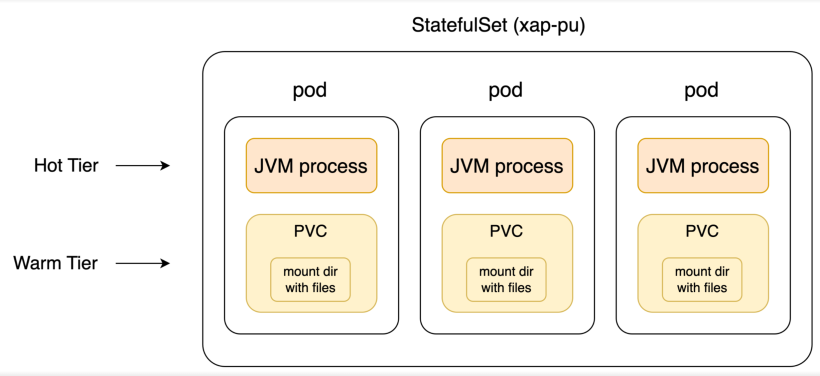
Tiered Storage implementation in Kubernetes![]() An open-source container orchestration system for automating software deployment, scaling, and management of containerized applications. involves managing disk volumes using standard resources:
An open-source container orchestration system for automating software deployment, scaling, and management of containerized applications. involves managing disk volumes using standard resources:
-
StorageClass: A cluster-level resource abstracting the storage provisioner in a given environment. This resource must be created by an administrator before deploying a space with Tiered Storage.
-
StatefulSet: Represents a space, ensuring a fixed relation between space partition pods and disk volumes. Created by running the space helm install command.
-
PersistentVolumeClaim (PVC): Represents a disk volume attached to a partition. PVCs (one per space partition) are created automatically by the space helm install command.
Optimizing the Use of Tiered Storage
In order to get the most out of Tiered Storage, please note the following:
-
By analyzing the query criteria, if it is definitely seen that all data is in the Hot layer, only the cache will be queried.
-
If max entries for the read is specified and there are max entries in cache that meets the query condition, only cache will be queried. If there is no limit, the query will go to the disk.
-
Using read API - ReadModifier : MEMORY_ONLY_SEARCH
-
When running using jdbc init the connection with properties. add readModifiers property with MEMORY_ONLY_SEARCH value.
-
Using the above modifier the number of objects in cache/total are revealed via the API.
-
The metrics are reported by GigaSpaces and can be viewed using a reporting tool such a Grafana
 Grafana is a multi-platform open source analytics and interactive visualization web application. It provides charts, graphs, and alerts for the web when connected to supported data sources..
Grafana is a multi-platform open source analytics and interactive visualization web application. It provides charts, graphs, and alerts for the web when connected to supported data sources.. -
According to the query criteria versus the Hot tier criteria, queries use the Hot tier only if all of the required data is present in the Hot tier. You can modify the read modifier to allow memory search only or the number of objects to read can be limited and they can be found in the Hot tier.
Primitive property types and selected Java classes are supported in Tiered Storage. See Tiered Storage Data Types for a complete list of supported data types.
For tables configured as Tiered Storage, if no rules are defined for the table, its data will be stored in the Warm tier only.
For Service Grid![]() A built-in orchestration tool which contains a set of Grid Service Containers (GSCs) managed by a Grid Service Manager. The containers host various deployments of Processing Units and data grids. Each container can be run on a separate physical machine. This orchestration is available for XAP only. SLA, the Processing Unit
A built-in orchestration tool which contains a set of Grid Service Containers (GSCs) managed by a Grid Service Manager. The containers host various deployments of Processing Units and data grids. Each container can be run on a separate physical machine. This orchestration is available for XAP only. SLA, the Processing Unit![]() This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity. must specify the instance level SLA with host requirement for each instance or alternatively, specify
This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity. must specify the instance level SLA with host requirement for each instance or alternatively, specify pu as a context property of the deployment. This will allow the system to automatically generate the SLA .![]() This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity..autogenerated-instance-sla=true
This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity..autogenerated-instance-sla=true
For Service Grid, each instance is bound to a specific machine for the entire duration of the deployment. Redeployment is only possible with the same schema, unless delete was called.
In order to improve recovery time from tiered storage space, counters initialization occurs in async mode, allowing the space to be ready before filling up statistics.
Deployment
For details of how to deploy Tiered Storage in a Service Grid environment, refer to Intelligent Tiering Details for Service Grid