Deploying a Space
In the previous section you have learned about data grid's capabilities as a data store. In this part of the tutorial we will show you how you can deploy an In Memory Data Grid (IMDG![]() In-Memory Data Grid.
A simple to deploy, highly distributed, and cost-effective solution for accelerating and scaling services and applications. It is a high throughput and low latency data fabric that minimizes access to high-latency, hard-disk-drive-based or solid-state-drive-based data storage. The application and the data co-locate in the same memory space, reducing data movement over the network and providing both data and application scalability.) that provides scalability and failover.
In-Memory Data Grid.
A simple to deploy, highly distributed, and cost-effective solution for accelerating and scaling services and applications. It is a high throughput and low latency data fabric that minimizes access to high-latency, hard-disk-drive-based or solid-state-drive-based data storage. The application and the data co-locate in the same memory space, reducing data movement over the network and providing both data and application scalability.) that provides scalability and failover.
Data gridcan be used as a scalable application platform on which you can host your Java application, similar to JEE and web containers. However, GigaSpaces's IMDG can also be embedded within another Java application which is not hosted within the data grid platform. In this part of the tutorial we will show you how to start a data grid and how you can interact with it.
Getting Started
To start a data grid, run the following command:
$GS_HOME\bin\gs-agent.bat
$GS_HOME/bin/gs-agent.sh
# start the agent with the REST REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style. interface
# Windows
gs-agent.bat --manager-local --gsc=2
# Unix
./gs-agent.sh --manager-local --gsc=2
REpresentational State Transfer. Application Programming Interface
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style. interface
# Windows
gs-agent.bat --manager-local --gsc=2
# Unix
./gs-agent.sh --manager-local --gsc=2
This will start all the infrastructure required to run the data grid. The following components are started:
-
Grid Service Manager (GSM
Grid Service Manager.
This is is a service grid component that manages a set of Grid Service Containers (GSCs). A GSM has an API for deploying/undeploying Processing Units. When a GSM is instructed to deploy a Processing Unit, it finds an appropriate, available GSC and tells that GSC to run an instance of that Processing Unit. It then continuously monitors that Processing Unit instance to verify that it is alive, and that the SLA is not breached.)
The Grid Service Manager is the component which manages the deployment and life cycle of the processing unit This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity.. -
Grid Service Container (GSC
Grid Service Container.
This provides an isolated runtime for one (or more) processing unit (PU) instance and exposes its state to the GSM.)
The Grid Service Container provides an isolated runtime for one (or more) processing unit instance and exposes its state to the GSM. -
The Lookup Service (LUS
Lookup Service.
This service provides a mechanism for services to discover each other. Each service can query the lookup service for other services, and register itself in the lookup service so other services may find it.)
The Lookup Service provides a mechanism for services to discover each other. Each service can query the lookup service for other services, and register itself in the lookup service so other services may find it. For example, the GSM queries the LUS to find active GSCs. -
Grid Service Agent (GSA
Grid Service Agent.
This is a process manager that can spawn and manage Service Grid processes (Operating System level processes) such as The Grid Service Manager, The Grid Service Container, and The Lookup Service. Typically, the GSA is started with the hosting machine's startup. Using the agent, you can bootstrap the entire cluster very easily, and start and stop additional GSCs, GSMs and lookup services at will.)
The GSA is a process manager that can spawn and manage service grid processes (Operating System level processes) such as the Grid Service Manager, The Grid Service Container, and The Lookup Service. Using the agent, you can bootstrap the entire data grid very easily, and start and stop additional GSCs, GSMs and lookup services at will. Usually, a single GSA is run per machine.
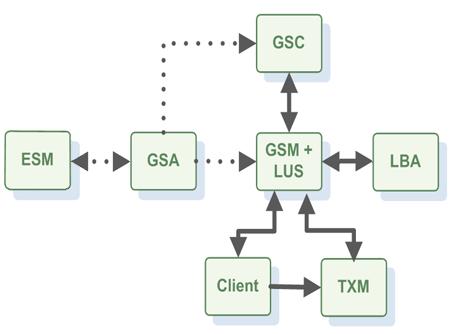
For more information, see the Service Grid Layer page in the Product Overview section.
When you execute the gs-agent command above without any arguments, 1 GSA, 1 GSM, 1 LUS and 2 GSCs will be started. The gs-agent command takes several different parameters as arguments.
For more information, see the Scripts page in the Administration guide.
Connecting to a Data Grid
In order to create a data grid, you need to first deploy it onto the GigaSpaces infrastructure. It's easy to write some code that connects to an existing data grid, or deploy a new one if the data grid does not exist. In the GigaSpace lingo, a data grid is called a Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model., and a data grid node is called a Space Instance. The space is hosted within a Processing Unit (PU
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model., and a data grid node is called a Space Instance. The space is hosted within a Processing Unit (PU![]() This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity.), which is the GigaSpaces unit of deployment.
This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity.), which is the GigaSpaces unit of deployment.
There are several ways you can deploy a new Data Grid; by command line, with java code embedded in your application and the admin UI. The following snippets shows how to deploy a data grid.
We want to deploy a data grid that has two primary partitions and one backup for each primary partition. Here are the gs and REST commands that you would execute to achieve this:
$GS_HOME\bin\gs.sh deploy-space -cluster schema=partitioned total_members=2,1 xapTutorialSpace
curl -X POST --header 'Content-Type: application/json' --header 'Accept: text/plain'
'http://localhost:8090/v1/spaces?name=xapTutorialSpace&partitions=2&backups=true&requiresIsolation=false'
This command will start a space called xapTutorialSpace with two primary partitions and a backup for failover for each primary.
You can also deploy the space via Java code. Here is an example:
String spaceName = "xapTutorialSpace";
public void startDataGrid() {
try {
// create an admin instance to interact with the cluster
Admin admin = new AdminFactory().createAdmin();
// locate a grid service manager and deploy a partioned data grid
// with 2 primaries and one backup for each primary
GridServiceManager mgr = admin.getGridServiceManagers()
.waitForAtLeastOne();
ProcessingUnit pu = mgr.deploy(new SpaceDeployment(spaceName)
.partitioned(2, 1));
} catch (ProcessingUnitAlreadyDeployedException e) {
// already deployed, do nothing
e.printStackTrace();
}
}
Lets take our online payment system. We are expecting thousands or even millions of payments to be processed over time and we want to store them in the IMDG. For this scenario we would like to partition our space into multiple partitions with each having a backup partition and the primary partitions are hosted on different machines then the backup partitions.
Here is how you would configure your IMDG: Lets assume we have 4 machines available. On all machines we will start a GSA. The default gs-agent script will give us a total number of 8 GSC's. We want to deploy 4 partitions each having a backup and there should only be one instance per machine.
$GS_HOME\bin\gs.sh deploy-space -cluster schema=partitioned total_members=4,1 -max-instances-per-machine 1 xapTutorialSpace
curl -X POST --header 'Content-Type: application/json' --header 'Accept: text/plain'
'http://localhost:8090/v1/spaces?name=xapTutorialSpace&partitions=4&backups=true&requiresIsolation=true'
When the application write Payment objects into this space, data grid will use the routing![]() The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. information provided (@SpaceRouting) by the Payment class to route the object to the right partition.
The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. information provided (@SpaceRouting) by the Payment class to route the object to the right partition.
Interacting with the Data Grid
Now we are ready to interact with the data grid. All the examples we explored in the first part of the tutorial can be used to interact with the IMDG.
If you have started the IMDG within your application, you would acquire the space like this:
GigaSpace gigaSpace = pu.waitForSpace().getGigaSpace();
Here is an example how you can connect to the grid from your application:
// Create the Space
GigaSpace gigaSpace = new GigaSpaceConfigurer(new SpaceProxyConfigurer("xapTutorialSpace")).gigaSpace();
Web Management Console
You can start data grid's console and inspect the Data Grid components that have been started. In the data grid distribution you will find the command file to launch the console.
$GS_HOME\bin\gs_webui.bat
$GS_HOME/bin/gs_webui.sh
After you execute the above command, open a browser and go to http://your_host:8099 and the login screen for the admin application will open up. The following screen shots will demonstrate some of the UI features: (no username and password needed)
For more information, see the Web Management Console page in the Administration guide.