Drools Rule Engine Integration
| Download |
|---|
| Drools integration |
Summary
This article illustrates how to integrate the Drools Rule Engine with the GigaSpaces data grid.
Overview
Drools is a business rule management system (BRMS) with a forward and backward chaining inference-based rules engine using an enhanced implementation of the Rete algorithm. Reasons to use Drools include:
- Declarative Programming
- Logic and Data Separation
- Speed and Scalability
 The ability of a system to handle increased load by adding resources, such as processing power or storage. Scalability ensures that the system can grow with the demands placed on it.
The ability of a system to handle increased load by adding resources, such as processing power or storage. Scalability ensures that the system can grow with the demands placed on it. - Centralization of Knowledge
- Understandable and Transparent Rules
- Dynamic Rule Deployment
The Drools Rule Engine matches Facts (POJO![]() Plain Old Java Object.
A regular Java object with no special restrictions other than those forced by the Java Language Specification and does not require any classpath.) against Rules to infer conclusions which result in actions. The process of matching the new or existing facts against Rules is called pattern matching, which is performed by the inference engine.
Plain Old Java Object.
A regular Java object with no special restrictions other than those forced by the Java Language Specification and does not require any classpath.) against Rules to infer conclusions which result in actions. The process of matching the new or existing facts against Rules is called pattern matching, which is performed by the inference engine.
Drools stores its rules in Production Memory and facts in Working Memory. The Agenda manages the execution order of these rules using a Conflict Resolution strategy.
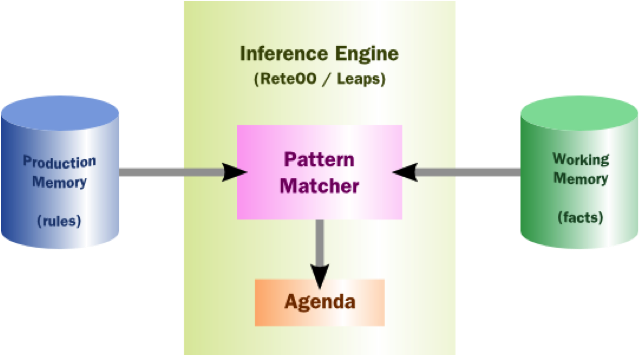
Drools has a "native" rule language. A rule file typically has a .drl extension. In a DRL file you can have multiple rules, queries and functions, as well as some resource declarations like imports, globals, and attributes. A package is a collection of rules and other related constructs, such as imports and globals. The package members are typically related to each other - perhaps HR rules, for instance.
A package represents a namespace, which ideally is kept unique for a given grouping of rules.
The KnowledgeBase is a repository of all the application's knowledge definitions. It will contain rules, processes, functions, and type models. The KnowledgeBase itself does not contain data; instead, sessions are created from the KnowledgeBase into which data can be inserted and from which process instances may be started. Creating the KnowledgeBase can be heavy, whereas session creation is very light, so it is recommended that KnowledgeBases be cached where possible to allow for repeated session creation.
Detailed documentation on Drools 5.6.0.Final can be found here.
Drools Integration with GigaSpaces
As stated earlier, Drools stores all rules and data types in-memory to reduce the overhead of compiling them every time before execution. This benefits enterprise applications with low-latency performance but establishes architectural gaps such as:
- Distribution
- Failover
- Redundancy
- Consistency
- Scalability
Let's discuss these gaps within the context of a stateless application hosted in clustered environment and explain how an integration with GigaSpaces would benefit its use of Drools.
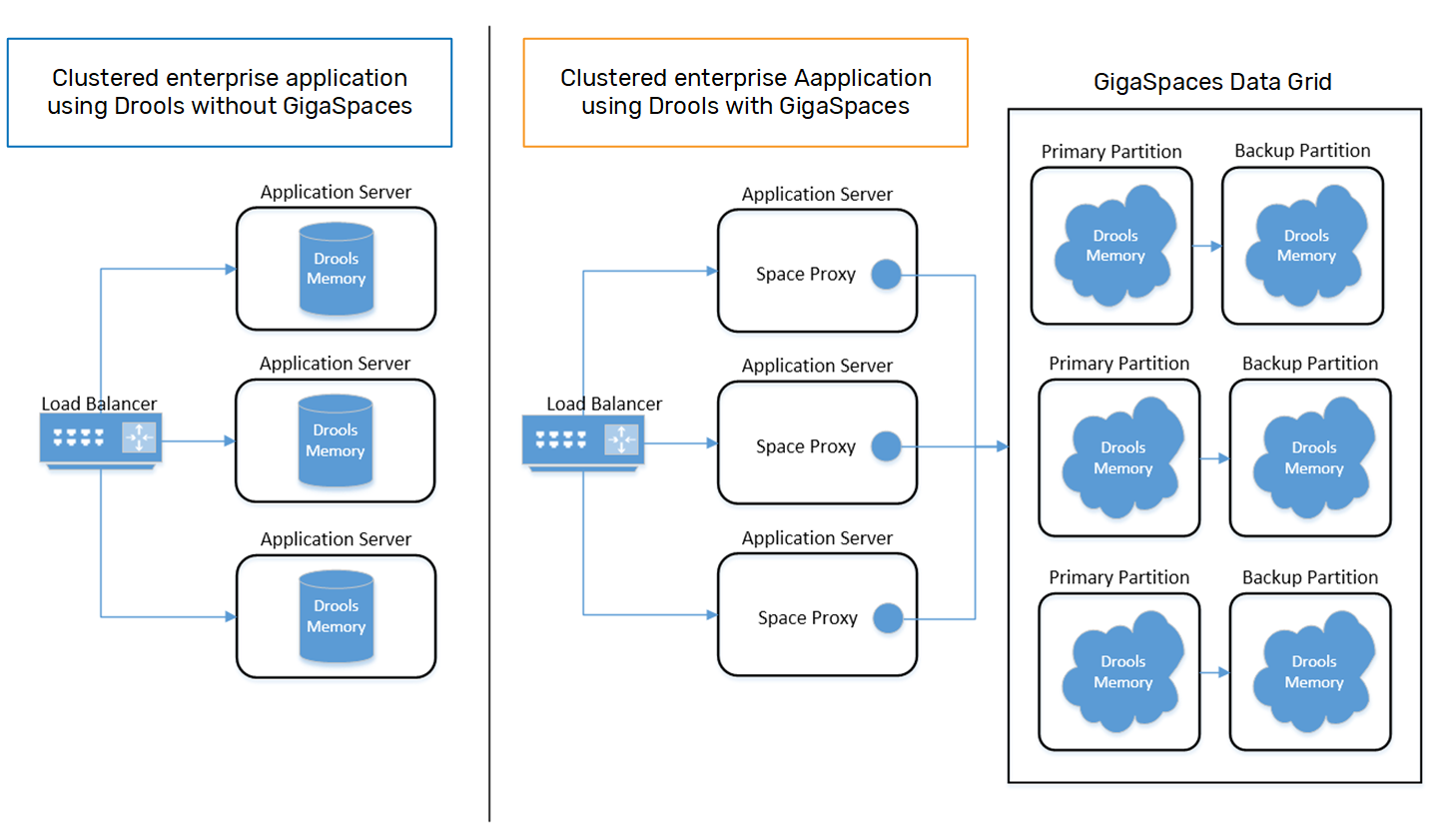
Distribution
Drools was not created as a distributed solution. In order to maintain seamless load-balancing in a clustered environment, each instance of an enterprise application would require identical data in its KnowledgeBase(s). The GigaSpaces data grid is inherently a distributed environment, so it allows the clustered enterprise applications to distribute their rules across multiple Data Grid partitions (Spaces). In addition, enterprise applications use a common reference proxy to the Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model., allowing them to avoid the burden on managing data locality.
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model., allowing them to avoid the burden on managing data locality.
Failover
Without GigaSpaces, the data in the KnowledgeBase would be lost, in the case of node failure within the cluster, and could not be recovered by the standard failover mechanism. GigaSpaces provides data failover out of the box via its asynchronous replication to back up cluster topology. In the case of a GigaSpaces primary partition failure, the backup partition becomes the primary, preventing data loss and maintaining data integrity throughout the entire process.
Redundancy
Storing the KnowledgeBase's data in each clustered JVM![]() Java Virtual Machine. A virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. memory is redundant and costly in terms of memory footprint. Integration with GigaSpaces removes the enterprise application's need to locally store data because the
Java Virtual Machine. A virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. memory is redundant and costly in terms of memory footprint. Integration with GigaSpaces removes the enterprise application's need to locally store data because the KnowledgeBase resides in a partition hosted on the Data Grid.
Consistency
Similar to the concerns of load balancing, enterprise applications require all clustered JVMs to not only store identical data but also ensure consistency upon any change. Instead of building a custom solution to update the entire cluster, GigaSpaces can be used to ensure data consistency. By utilizing GigaSpaces's built-in Routing Mechanism, all instances of the cluster can seamlessly be routed to the unique partition that is storing the relevant KnowledgeBase(s) and always receive a consistent result.
Scalability
An enterprise application hosting multiple instances of KnowledgeBases can be limited by the memory constraints of its underlying JVM. Turning to a 64-bit JVM could extend memory resources, but its benefits are eventually offset by incurring an increased garbage collection![]() Garbage collection (GC) is a form of automatic memory management. The garbage collector attempts to reclain memory that was allocated by the program, but is not longer referenced; such memory is called garbage. penalty. With GigaSpaces, KnowledgeBases can be distributed across separate partitions each hosted on top of their own individual 64-bit JVM, allowing Drool's production/working memory to scale into the Terabytes.
Garbage collection (GC) is a form of automatic memory management. The garbage collector attempts to reclain memory that was allocated by the program, but is not longer referenced; such memory is called garbage. penalty. With GigaSpaces, KnowledgeBases can be distributed across separate partitions each hosted on top of their own individual 64-bit JVM, allowing Drool's production/working memory to scale into the Terabytes.
Integration Pattern
To demonstrate GigaSpaces's integration with Drools, we designed a pattern in the form of a Maven project. The project is distributed into 4 Maven Modules, each with an individual purpose:
| Module | Purpose |
|---|---|
| common | Sharable library including data model and utilities |
| client | Load/analyze/execute/remove rules and facts |
| space | Defines space, event containers and remote services |
| web-service | Expose JSON Restful |
The combination of these modules provide you with a working project to deploy a Data Grid, load/compile/remove rules from DRL files, execute rules from a one-off process and/or expose them as JSON Restful Web Service.
Let's review each module to understand their code and patterns.
Common Module
The main purpose of this module is to define the data model for the entire data grid. The data model includes a POJO representation of Facts, Drools Rules, Knowledge Packages, KnowledgeBases, etc.
Facts are representations of business entities which will be referenced in either or both the condition and consequence of rules. In order for client applications to dynamically create rules, they must first define Facts which will be loaded into a KnowledgeBase's Working Memory before Rules execution can occur. Therefore the Fact POJO must be created and deployed with the Space module before new dynamic rules can be compiled and executed using them as a reference.
The integration between Drools and GigaSpaces is represented as the Space Class called KnowledgeBaseWrapper. This object stores a KnowledgeBase in the data grid along with all of its compiled content (i.e. rules, definitions, globals, fact types, etc.). Therefore it is a wrapper of the Drools Production/Working Memory, which is enhanced with the routing![]() The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. capabilities of a Space class along with additional attributes compensating for the KnowledgeBase's lack of transparency.
The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. capabilities of a Space class along with additional attributes compensating for the KnowledgeBase's lack of transparency.
The remaining POJOs are meant to be informative tools for management and governance purposes. Their role is to provide the user with metadata type information about the contents of KnowledgeBase without having to execute operations against the actual objects.
Client Module
This module implements classes encapsulating stand-alone functional processes to load, analyze, execute and remove Rules and Facts. These processes can be simply instantiated by running their main methods and will interact with the space via the Space Proxy. If you are using an Eclipse IDE![]() Integrated Development Environment.
A software application that helps programmers develop software code efficiently. It increases developer productivity by combining capabilities such as software editing, building, testing, and packaging in an easy-to-use application. Example: DBeaver. you can just click on the class and choose Run As Configurations to start the process.
Integrated Development Environment.
A software application that helps programmers develop software code efficiently. It increases developer productivity by combining capabilities such as software editing, building, testing, and packaging in an easy-to-use application. Example: DBeaver. you can just click on the class and choose Run As Configurations to start the process.
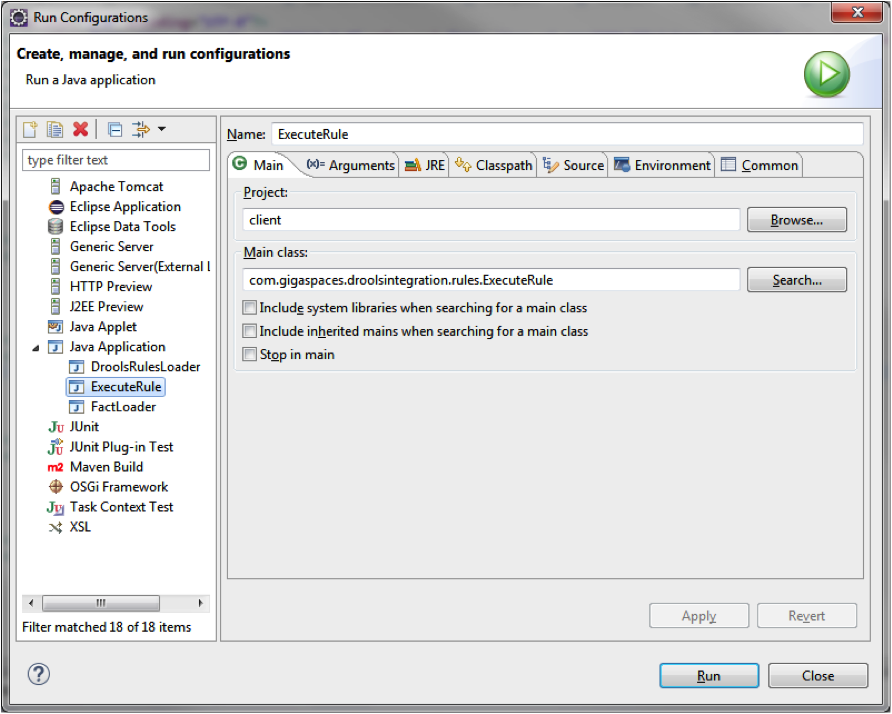
Some main methods allow for you to pass arguments.
Here is a list of the functional processes by category:
| Category | Function |
|---|---|
| Analyze | PrintOutAllKnowledgePackages PrintOutSingleKnowledgePackage |
| Loader | DroolsRuleLoader FactLoader |
| Manage Rules | ExecuteRule RemoveRule |
Analyze
By running these processes you can get a print out to the System.Out log of the KnowledgePackages and their corresponding Rules within the chosen KnowledgeBase.
You can also get this information by inspecting the KnowledgePackage Space Class via the GigaSpaces Management Center, which maintains metadata about each available KnowledgePackage across all loaded KnowledgeBase(s).
Loader
These processes load both the Rules and Facts into the KnowledgeBase(s) stored on one or more instances of Stateful Processing Units![]() This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity. representing the Space.
This is the unit of packaging and deployment in the GigaSpaces Data Grid, and is essentially the main GigaSpaces service. The Processing Unit (PU) itself is typically deployed onto the Service Grid. When a Processing Unit is deployed, a Processing Unit instance is the actual runtime entity. representing the Space.
Rules meant to reside within the same KnowledgeBase are gathered within their uniquely named RuleSet.xml located inside the resources/META-INF/rules folder. Each XML file will represent a separate KnowledgeBase which will be uniquely routed to its respective partition. The individual rules are encapsulated within DRL files. To add rules, simply add <resource> elements to the <add> element before running the load process. To remove rules just change the <add> element to <remove> and rerun the same process. Here is an example of a RuleSet.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0 change-set.xsd'>
<add>
<resource source='classpath:META-INF/rules/drl/ValidateAgeRule.drl' type='DRL'/>
<resource source='classpath:META-INF/rules/drl/ValidateApplicationRule.drl' type='DRL'/>
</add>
</change-set>
The Drools syntax is encapsulated within a DRL file including all reserved keywords such as package, import, rule, etc. This implementation assumes that only a single rule resides within each DRL file. As mentioned earlier, the custom facts which were defined in the common data-model are imported into the rules for use in both the condition (when) and consequence (then).
package Application
import com.gigaspaces.droolsintegration.model.facts.*;
rule "ValidAgeRule"
when
$applicant : Applicant( age > 18 )
$application : Application( processed == false )
then
System.out.println("Applicant is of valid age: " + $applicant.getAge());
$application.setApplicantId($applicant.getId());
$application.setApplicantName($applicant.getName());
$application.setApplicantApproved(true);
update($application);
end
Aside from loading rules this module can also load facts as Space Classes into the Space. These facts can be later queried as part of a decision web-service transaction and loaded into the KnowledgeBase's working memory before rule(s) execution.
Manage Rules
If you want to quickly pattern-match a set of facts against a loaded KnowledgeBase without having to create or alter a Restful Web Service, you can run the ExecuteRules class as an Application. To implement your own Rules Execution process, you simply have to account for the input and output parameters which will be passed to the Remote Service, which is collocated with the Space.
Since Drools only acts upon Iterable collections our integration pattern includes a utility class called IterableMapWrapper. This class simply wraps a Map and returns an iterator to its values in the iterator method. Use this map to pass all of the input facts which will be used for pattern matching before rules execution.
By default, Drools returns all the input facts that have not been deleted from working memory during rules-execution along with any new facts that are added to the collection. This could be an unnecessary cost because it increases memory footprint over the network for client applications that do not require the entire collection of facts as a returned parameter. To avoid the overhead, we allow the client to pass a list as an input, which filters the result collection on the Space side and passes back only the required facts back over the network.
public void execute(Integer id) {
log.info("Starting ExecuteRules Execution");
Applicant applicant = gigaSpace.readById(Applicant.class, id);
Application application = new Application();
application.setProcessed(false);
IterableMapWrapper facts = new IterableMapWrapper();
facts.put(Applicant.class.getSimpleName(), applicant);
facts.put(Application.class.getSimpleName(), application);
List<String> resultKeyList = new ArrayList<String>();
resultKeyList.add(Application.class.getSimpleName());
try {
IterableMapWrapper resultFacts = (IterableMapWrapper) rulesExecutionService.executeRulesWithLimitedResults(RulesConstants.RULE_SET_APPLICANT_AGE, facts, resultKeyList);
Application result = (Application) resultFacts.get(Application.class.getSimpleName());
if(!result.getProcessed()) {
result.setApplicantApproved(false);
result.setApplicantId(applicant.getId());
result.setApplicantName(applicant.getName());
}
log.info("Date Approved: " + result.getDateApproved());
log.info("Applicant Id: " + result.getApplicantId());
log.info("Applicant Name: " + result.getApplicantName());
log.info("Application Processed: " + result.getProcessed());
}catch(Exception e) {
log.error(e.getMessage(), e);
}
log.info("End ExecuteRules Execution");
}
The client module also allows the removal of an individual rule as an alternative to changing the element inside RuleSet.xml from <add> to <remove>. To remove a specific rule using this utility you need only to change the arguments when running the RemoveRule class as an application.
Space Module
This module creates a deployable artifact (JAR) which instantiates Stateful processing unit(s) representing the data grid (Space). By default, the Space uses the SLA.xml file to deploy the predetermined amount of primary and backup partitions with the clustering topology set to partitioned-sync2backup.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:os-sla="http://www.openspaces.org/schema/sla"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.openspaces.org/schema/sla http://www.openspaces.org/schema/10.0/sla/openspaces-sla.xsd">
<os-sla:sla cluster-schema="partitioned-sync2backup" number-of-instances="2" number-of-backups="1"The number of backups per partition is zero or one.
max-instances-per-vm="1">
</os-sla:sla>
</beans>
In addition to hosting data, this processing unit takes advantage of GigaSpaces's collocation of business logic in the form of event processing and Space-based remoting.
The event processor of choice is the Polling Container, which listens for specific events to occur on the Space. As part of our integration pattern, we opted to decouple the adding/removing of Rule Events to the Space from the compilation and injection of those rules to their respective KnowledgeBase. Since loading a single instance of a KnowledgeBase creates a bottleneck for a queue of 100+ rules, it makes sense to allow the client (remote client proxy) to fire and forget while the server (Space) does its work at its own pace. Upon notification of an event, the collocated event handler looks up the KnowledgeBase from the data grid and adds the new rule to the KnowledgeBase, assuming compilation was successful. It alsos updates the metadata type Space Classes to keep track of the KnowledgeBase contents for transparency.
@SpaceDataEvent
public DroolsRuleAddEvent addRule(DroolsRuleAddEvent droolsRuleAddEvent) {
String ruleSet = droolsRuleAddEvent.getRuleSet();
String knowledgePackageName = droolsRuleAddEvent.getPackageName();
String ruleName = droolsRuleAddEvent.getRuleName();
try {
KnowledgeBaseWrapper knowledgeBaseWrapper = knowledgeBaseWrapperDao.read(ruleSet);
if(knowledgeBaseWrapper == null) {
knowledgeBaseWrapper = createKnowledgeBaseWrapper(ruleSet);
}
KnowledgePackage knowledgePackage = knowledgePackageDao.read(ruleSet, knowledgePackageName);
if(knowledgePackage == null) {
knowledgePackage = createKnowledgePackage(knowledgeBaseWrapper, knowledgePackageName, ruleSet);
}
if(!knowledgePackage.getRules().containsKey(ruleName)) {
DroolsRule droolsRule = createDroolsRule(droolsRuleAddEvent);
knowledgePackageDao.addRule(knowledgePackage, ruleName, droolsRule);
addKnowledgePackages(knowledgeBaseWrapper, droolsRuleAddEvent, ruleName);
knowledgeBaseWrapperDao.write(knowledgeBaseWrapper);
log.info(String.format("Rule '%s' compiled successfully", ruleName));
}else {
log.info(String.format("Rule '%s' already exists in knowledgePackage '%s'", ruleName, knowledgePackageName));
}
}catch(Exception e) {
log.info(String.format("Rule '%s' failed compilation for ruleset", ruleName));
log.error(e.getMessage(), e);
}
droolsRuleAddEvent.setProcessed(Boolean.TRUE);
return null;
}
Space-based remoting is a combination of an interface located in the common module and an implementation of the interface that is deployed co-located with the space. The interface is shared by both the space and the client(s) via the common module. To expose the interface as a Remoting Service, a simple annotation was added to the implementation class as well as a annotation scan within the pu.xml.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:os-core="http://www.openspaces.org/schema/core"
xmlns:os-events="http://www.openspaces.org/schema/events"
xmlns:os-remoting="http://www.openspaces.org/schema/remoting"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.openspaces.org/schema/core http://www.openspaces.org/schema/10.0/core/openspaces-core.xsd
http://www.openspaces.org/schema/events http://www.openspaces.org/schema/10.0/events/openspaces-events.xsd
http://www.openspaces.org/schema/remoting http://www.openspaces.org/schema/10.0/remoting/openspaces-remoting.xsd">
<os-core:space id="space" url="/./space" />
<!-- Defines a distributed transaction manager -->
<os-core:distributed-tx-manager id="transactionManager"/>
<!-- OpenSpaces simplified space API built on top of IJSpace/JavaSpace -->
<os-core:giga-space id="gigaSpace" space="space" tx-manager="transactionManager"/>
<!-- Enables the usage of @GigaSpaceContext annotation based injection -->
<os-core:giga-space-context/>
<!-- Enable scan for OpenSpaces and Spring components -->
<context:component-scan base-package="com.mycompany.app"/>
<!-- Enables the usage of @GigaSpaceContext annotation based injection. -->
<os-core:giga-space-context/>
<!-- Enables Spring Annotation configuration -->
<context:annotation-config/>
<!-- Enables using @Polling and @Notify annotations -->
<os-events:annotation-support/>
<!-- Enables using @RemotingService as well as @ExecutorProxy (and others) annotations -->
<os-remoting:annotation-support/>
<!-- Enables using @PreBackup, @PostBackup and other annotations -->
<os-core:annotation-support/>
<!--Add service exporter for remoting services-->
<os-remoting:service-exporter id="serviceExporter"/>
</beans>
@RemotingService
public class RulesExecutionServiceImpl implements IRulesExecutionService {
@Autowired
private KnowledgeBaseWrapperDao knowledgeBaseWrapperDao;
@Transactional
public Iterable<Object> executeRules(String ruleSet, Iterable<Object> facts, Map<String, Object> globals) {
KnowledgeBaseWrapper knowledgeBaseWrapper = knowledgeBaseWrapperDao.readByRuleSet(ruleSet);
if(knowledgeBaseWrapper != null) {
StatelessKnowledgeSession session = knowledgeBaseWrapper.getKnowledgeBase().newStatelessKnowledgeSession();
//Session scoped globals
if(globals != null) {
for(String key : globals.keySet()) {
session.setGlobal(key, globals.get(key));
}
}
session.execute(facts);
}else {
return null;
}
return facts;
}
}
As with any execution against a partitioned space, a routing key is required for the Hash-Based Routing mechanism to determine which partition hosts the client's requested data. The routing key can also simply be set by adding an annotation, but this time to one of the parameters inside the method signature.
public interface IRulesExecutionService {
Iterable<Object> executeRules(@Routing String resultSet, Iterable<Object> facts, Map<String, Object> globals);
Iterable<Object> executeRules(@Routing String resultSet, Iterable<Object> facts);
Iterable<Object> executeRulesWithLimitedResults(@Routing String resultSet, IterableMapWrapper facts, List<String> resultKeys, Map<String, Object> globals);
Iterable<Object> executeRulesWithLimitedResults(@Routing String resultSet, IterableMapWrapper facts, List<String> resultKeys);
}
Web Services Module
This module creates a deployable artifact (WAR) that instantiates a Stateless processing unit(s) hosting JSON Restful Web Services on top of GigaSpaces's Jetty Processing Unit Container.
Interaction with these services is very simple, because they only implement the GET REST method. A client only needs an Internet Browser to initiate a HTTP Servlet transaction on the listening Spring Controllers. There are two types of services that are deployed as part of this integration pattern - Decision Services and Generic Data Retrieval Services.
Decision services create or look up facts from the Space and pass them to the Remoting Service, which adds them to the KnowledgeBase's working memory and pattern matches them against all compiled rules. To initiate a decision service, enter a URL in the Browser and in response you receive a JSON payload printed to the screen.

Generic REST Data Retrieval Services come in two flavors - Read-By-ID and Read-By-Type. Read-By-ID requires the client to pass an ID along with the type of Object they are requesting. The Read-By-Type only requires the type returning multiple objects.

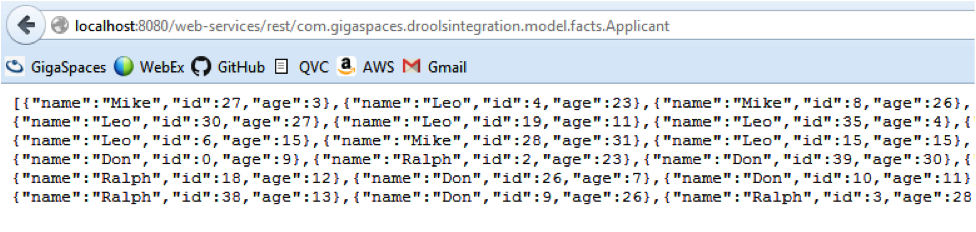
Running the Demo
Confirm Java is installed by running the java -version in your command line.

If Java is not installed, download Java and add JAVA_HOME to your system variables.
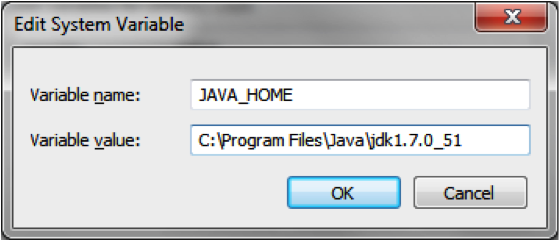
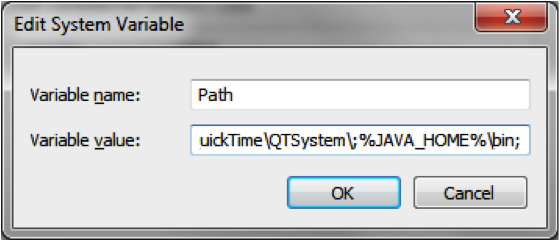
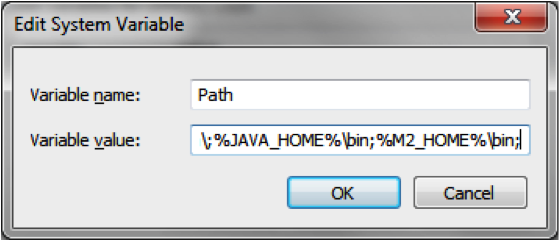
Add %JAVA_HOME%/bin to your PATH system variable.
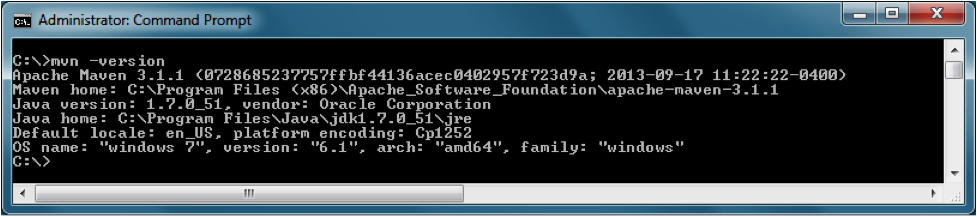
Confirm Maven is installed by running the mvn version in your command line.
If Maven is not installed, download Maven and add M2_HOME to your system variables.
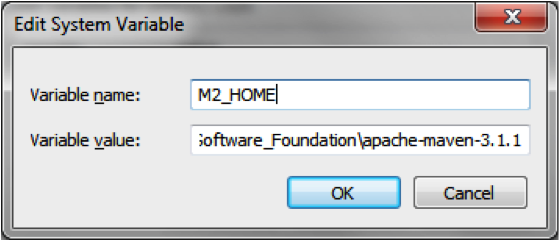
Add %M2_HOME%/bin to your PATH system variable.
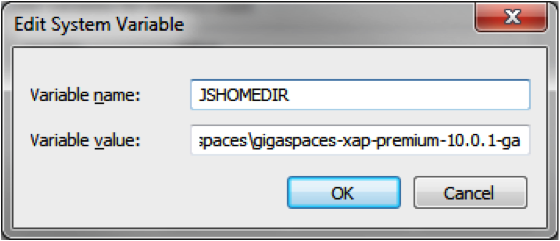
If GigaSpaces is not installed, download the latest version and add JSHOMEDIR to your system variables.
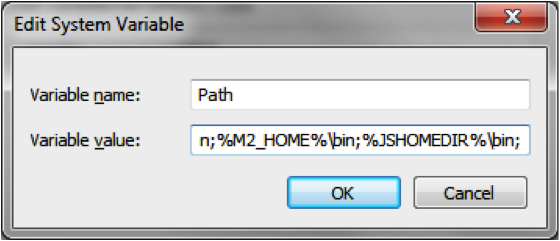
Add %JSHOMEDIR%/bin to your PATH system variable.
Download the example and extract.
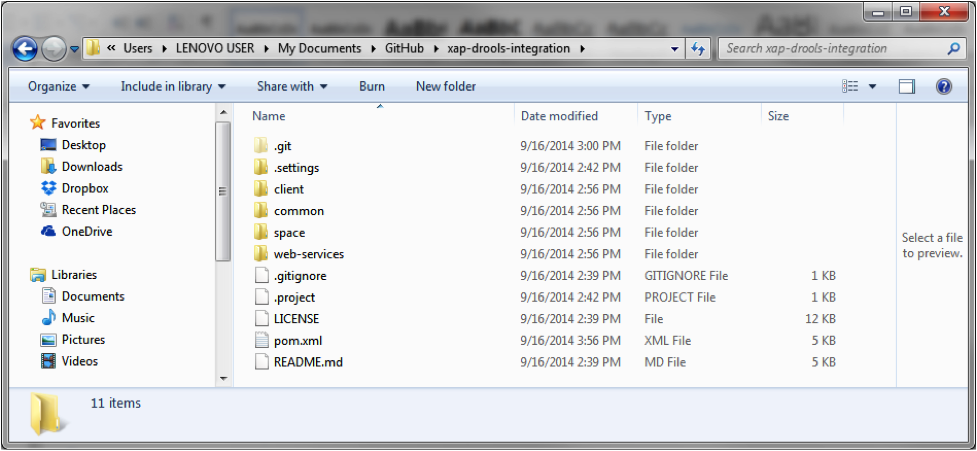
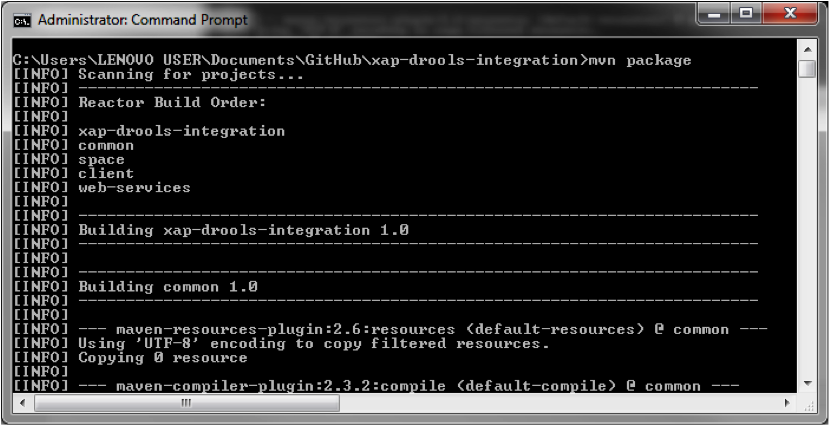
Navigate to the project root and execute the mvn package command.
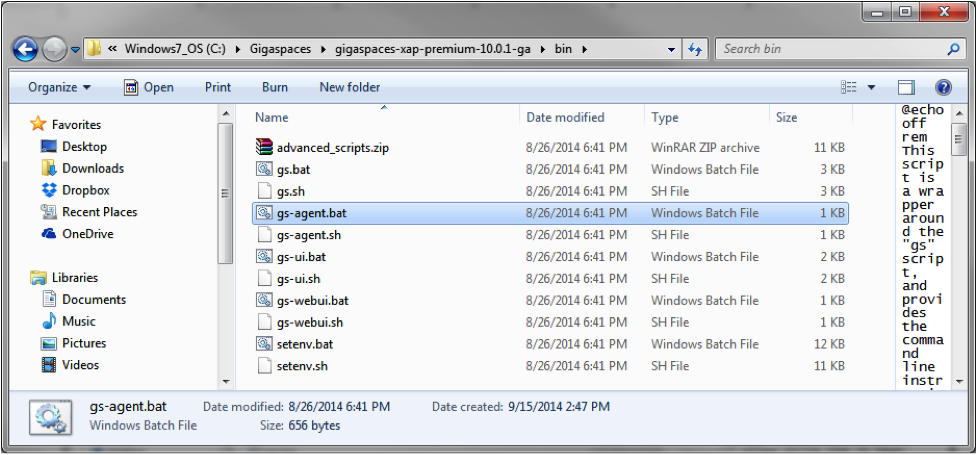
Navigate to the GigaSpaces bin directory and double-click gs-agent.bat.
Start the Web Management Console by double-clicking gs-webui.bat.
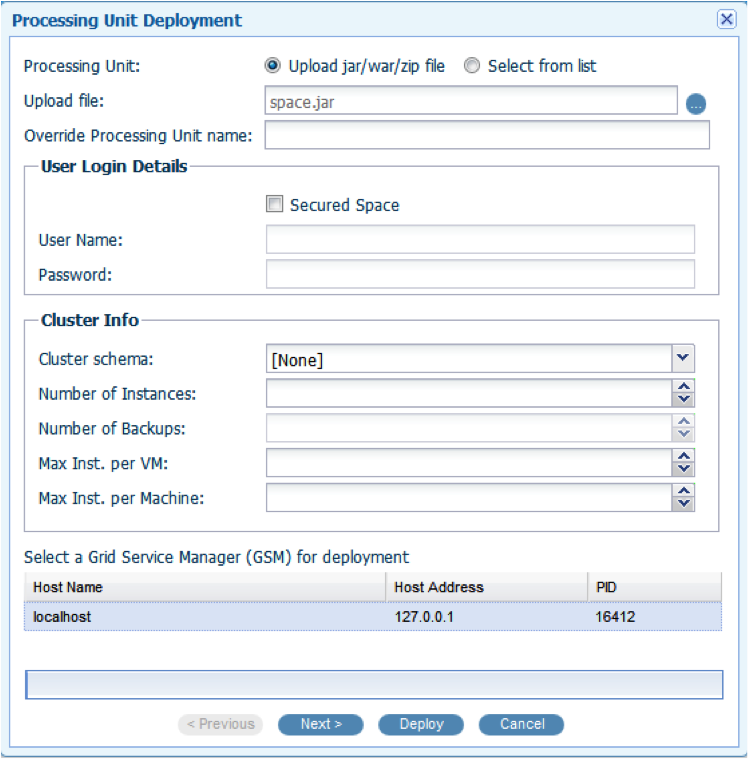
Click the Hosts Tab and find the Deploy drop-down. Choose Processing Unit.
Click Upload File and navigate to the space/target directory inside the Distributed Drools project. Double-click the space.jar and click Deploy.
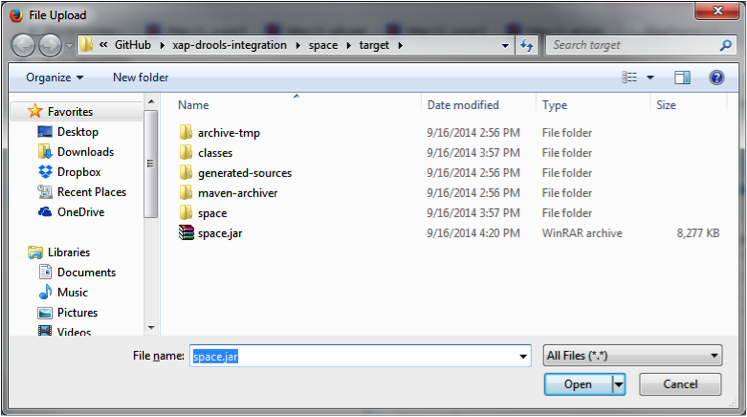
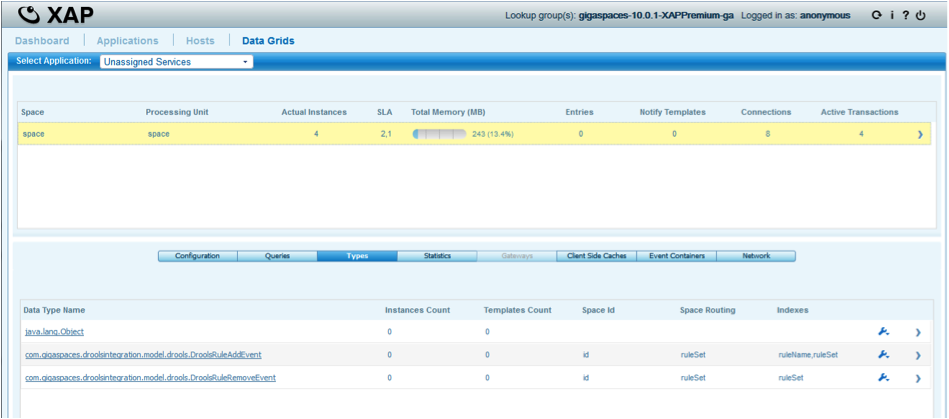
Confirm that the Space was created by clicking the Data Grid tab.
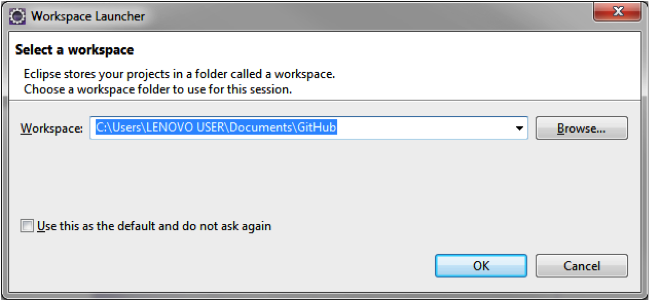
Open the workspace in an Eclipse IDE.
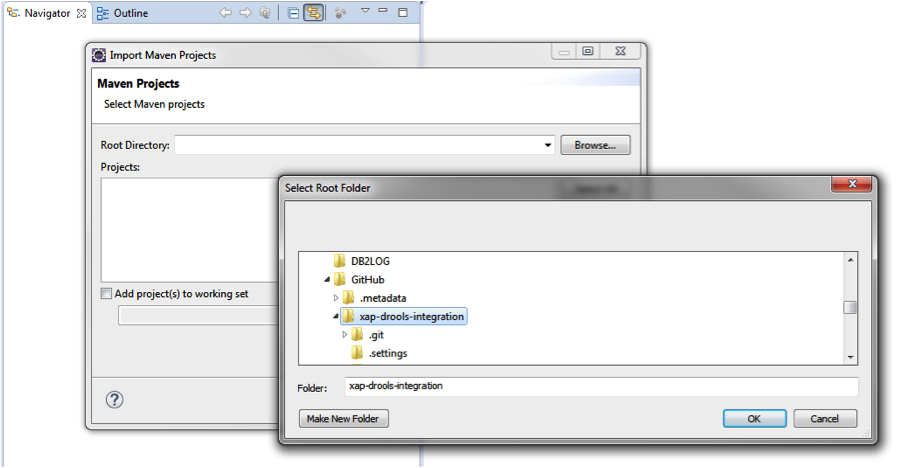
Import the existing Maven Project named xap-drools-integration.
Run DroolsRuleLoader.java and FactLoader.java as a Java Application.
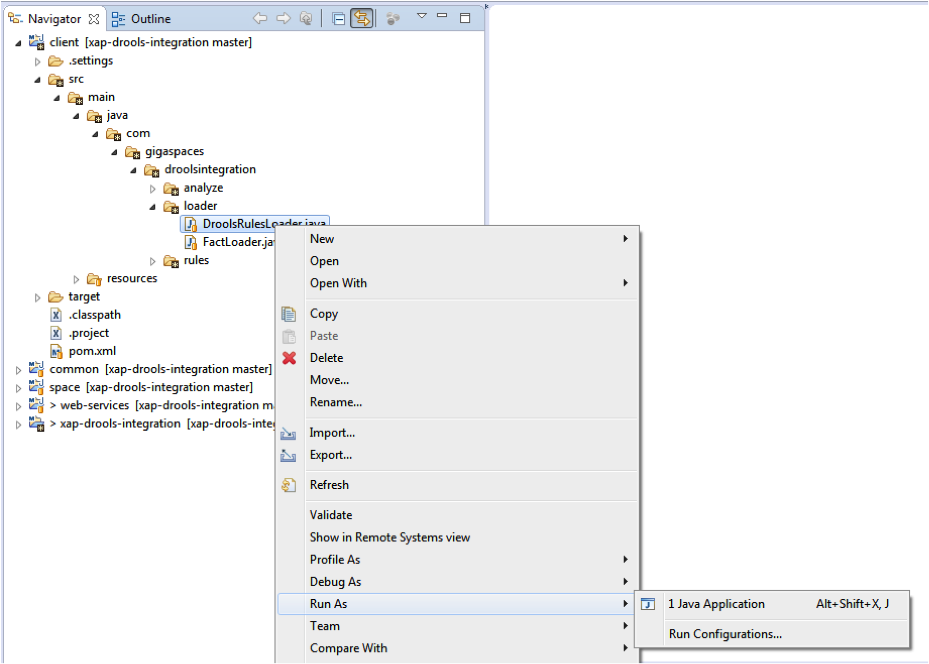
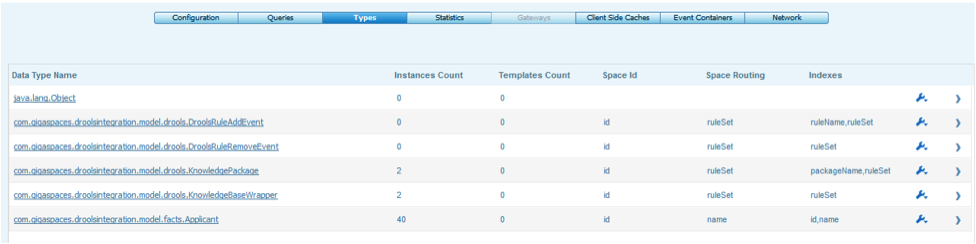
Confirm that the KnowledgeBasesWrappers and Applicant Facts were loaded to the Space.
Click the Hosts Tab and deploy the web-services.war file.
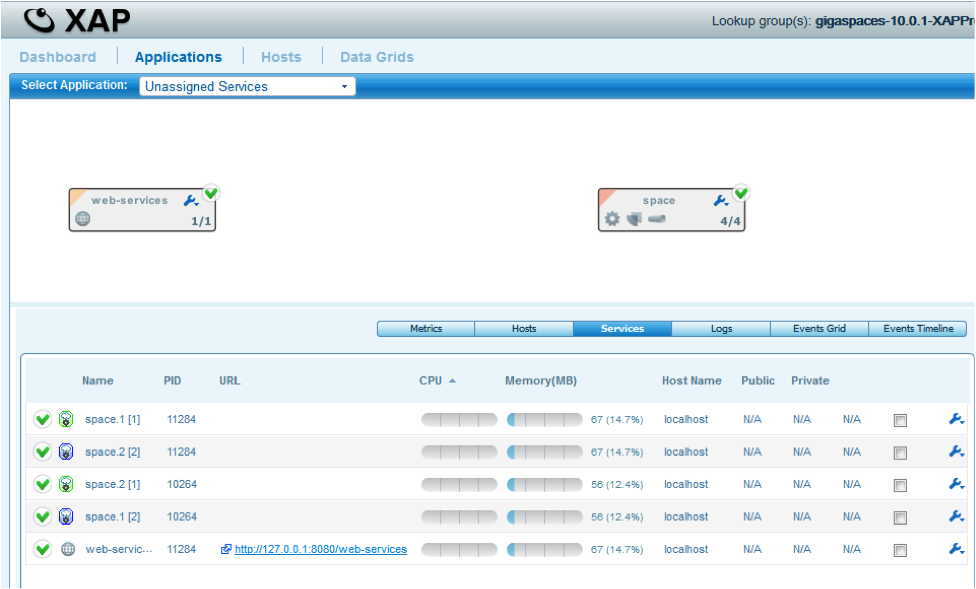
Click the Applications Tab and confirm the Web Services URL and PORT.
Open an Internet Browser and begin testing the Decision and Generic Data Lookup Services.
http://localhost:8080/web-services/mycompany/rest/com.mycompany.app.model.facts.Applicant/1 http://localhost:8080/web-services/mycompany/rest/com.mycompany.app.model.facts.Applicant http://localhost:8080/web-services/mycompany/rest/decision/processApplicationService/1 http://localhost:8080/web-services/mycompany/rest/decision/checkHolidayService/summer/july