GigaSpaces Kafka Sink Connector
| Author | Product Version | Last Updated | Reference | Download |
|---|---|---|---|---|
| Yoram Weinreb | 15.2 | April 2020 | github |
Kafka is enterprise software that provides a publish/subscribe data communication service. Kafka![]() Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. can be used to indicate the location of output data for a GigaSpaces SpaceType Descriptor.
Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. can be used to indicate the location of output data for a GigaSpaces SpaceType Descriptor.
Prerequisites
In order to deploy the GigaSpaces Kafka Sink Connector, the following prerequisites are required:
-
Install Kafka and Kafka Connect
-
Install GigaSpaces v15.2
- Install Git, Maven and JDK 8
Installation Steps
git clonethe repomvn clean package- Move the generated jar (from the target folder) to the Kafka connect connector's
libfolder. - Define the connector configuration as outlined below.
Schema and type definitions for the data can be expressed via the json file as shown below.
The maven Kafka artifacts in the pom.xml file must match the Kafka version.
If you have developed a GigaSpaces data model, you do not have to provide a json file. Instead, you can provide the generated jar file containing the relevant POJOs.
Configuration
Following is an example of a GigaSpaces connector properties file,connect-gigaspaces-sink.properties .
bootstrap.servers=localhost:9092
name=gigaspaces-kafka
connector.class=com.gigaspaces.kafka.connector.GigaspacesSinkConnector
tasks.max=1
topics=Pet,Person
gs.connector.name=gs
# True -- start gs inside the same JVM Java Virtual Machine. A virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. as connector; False - separate JVM (default)
gs.space.embedded=false
# Name of the target gs Space Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model.
gs.space.name=demo
# Location of GS Manager:
gs.space.locator=127.0.0.1:4174
#Choose one of the following -- Jar file or Json file:
gs.model.json.path=<path to gigaspaces kafka connector repo>/example/resources/model.json
#
plugin.path=<path to gigaspaces kafka connector repo>
Java Virtual Machine. A virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode. as connector; False - separate JVM (default)
gs.space.embedded=false
# Name of the target gs Space Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model.
gs.space.name=demo
# Location of GS Manager:
gs.space.locator=127.0.0.1:4174
#Choose one of the following -- Jar file or Json file:
gs.model.json.path=<path to gigaspaces kafka connector repo>/example/resources/model.json
#
plugin.path=<path to gigaspaces kafka connector repo>
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
key.converter=org.apache.kafka.connect.storage.StringConverter
# Currently the connector does not support Kafka schema.
key.converter.schemas.enable=false
#key.converter.schemas.enable=true
#value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
# Flush much faster than normal, which is useful for testing/debugging
offset.flush.interval.ms=10000
Following is an example of a GigaSpaces connector model schema json file.
These JSON fields map to the Space Type Descriptor in GS. For more information, see Space type Descriptor in the GigaSpaces documentation center.
[{
"type": "com.gs.Person",
"FixedProperties": {
"firstname": "java.lang.String",
"lastname": "java.lang.String",
"age": "java.lang.Integer",
"num": "java.lang.Integer"
},
"Indexes": {
"compoundIdx": {"type":"EQUAL", "properties": ["firstname", "lastname"], "unique": false},
"ageIdx": {"type":"ORDERED", "properties": ["age"], "unique": false}
},
"Id": {"field":"num", "autogenerate": false},
"RoutingProperty": "firstname"
},
{
"type": "com.gs.Pet",
"FixedProperties": {
"kind": "java.lang.String",
"name": "java.lang.String",
"age": "java.lang.Integer"
},
"Indexes": {
"compoundIdx": {"type":"EQUAL", "properties": ["kind", "name"], "unique": false},
"ageIdx": {"type":"ORDERED", "properties": ["age"], "unique": false}
},
"Id": {"field":"name"},
"RoutingProperty": "name"
}]}]
Running the Example
The steps must be run in the order indicated below.
In this example, we will consume data from a text file using the FileStreamSource source connector.
This connector will publish the lines it reads to the type topics in Kafka.
The GigaSpaces sink connector will read the data from the topics and store them in the in-memory grid (the "Space").
All files are under the example/resources folder.
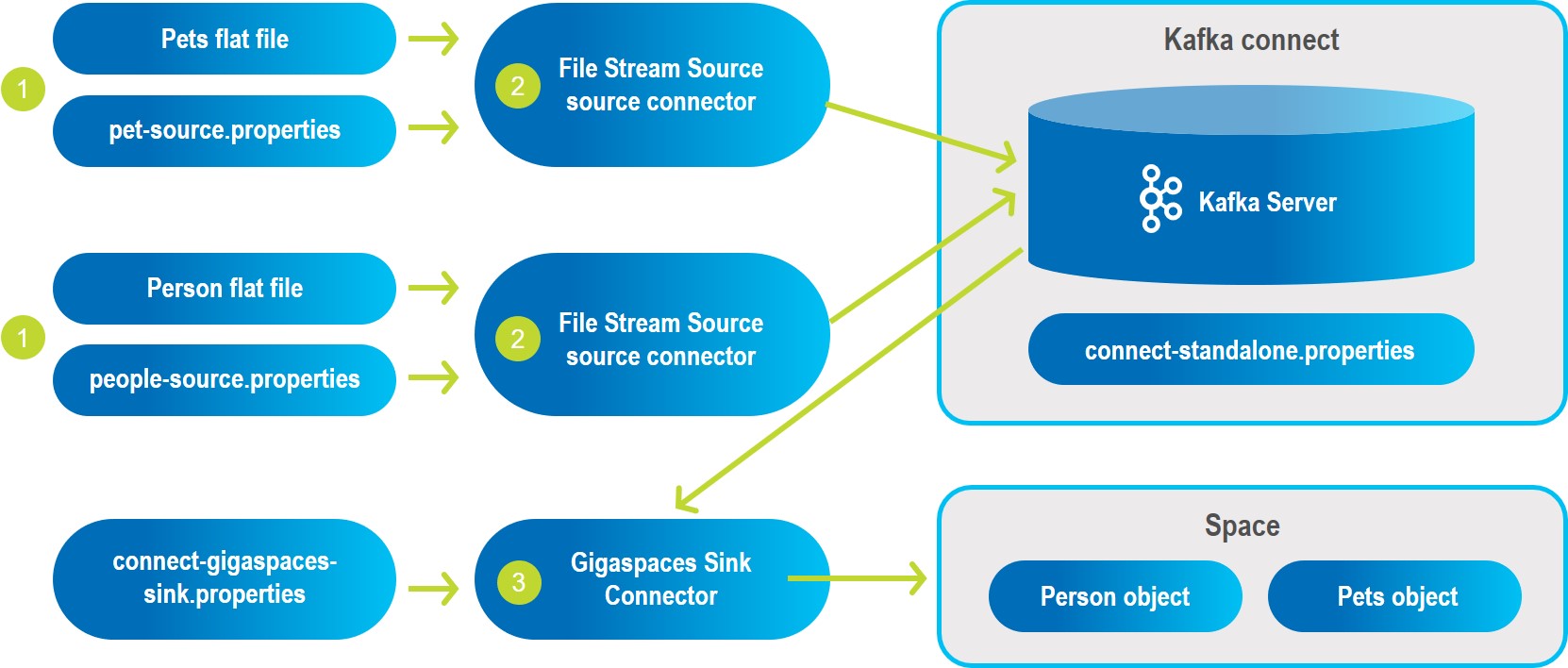
| Key to Diagram | |
|---|---|
 | Consume data from text files based on information in properties files. |
 | FileStreamSource source connector publishes the lines it reads to the type topics in Kafka. |
 | Gigaspaces sink connector reads the data from the topics and stores them in the in-memory grid (the "Space"). |
- Start Gigaspaces and have a Space running. In this example, we are running the demo project:
gs.sh demo - Start Kafka using the same port used for Zookeeper Apache Zookeeper. An open-source server for highly reliable distributed coordination of cloud applications. It provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. The goal is to make these systems easier to manage with improved, more reliable propagation of changes..
- Start the connect with the source and sink connectors and see how the data is consumed and published to the space, as shown below:
connect-standalone connect-standalone.properties people-source.properties pet-source.properties connect-gigaspaces-sink.propertiesThe three connectors properties are found in
<path to gigaspaces kafka connector repo>/example/resources.Ensure that the file parameter in the
people-source.propertiesfile and thepet-source.propertiesfile points to the location of the corresponding txt files. - Connect to the GigaSpaces Ops Manager using the Ops Manager URL, and view the types that were defined and the data that was inserted into the spaces by the connector.
From the Ops Manager screen, choose Analyze my data:
-
In the Spaces Overview, select the
demoSpace: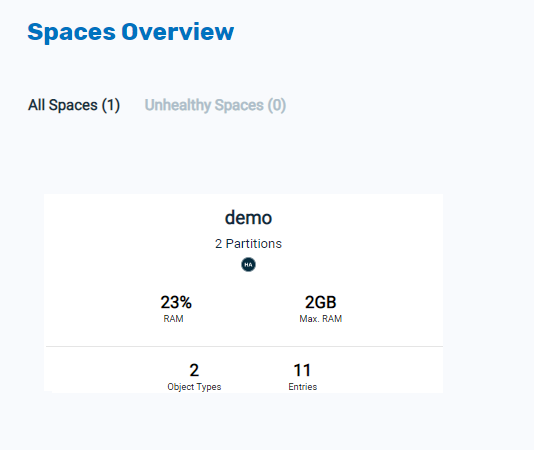
- You can now see the two object types,
PetandPerson, and the number of entries for each object: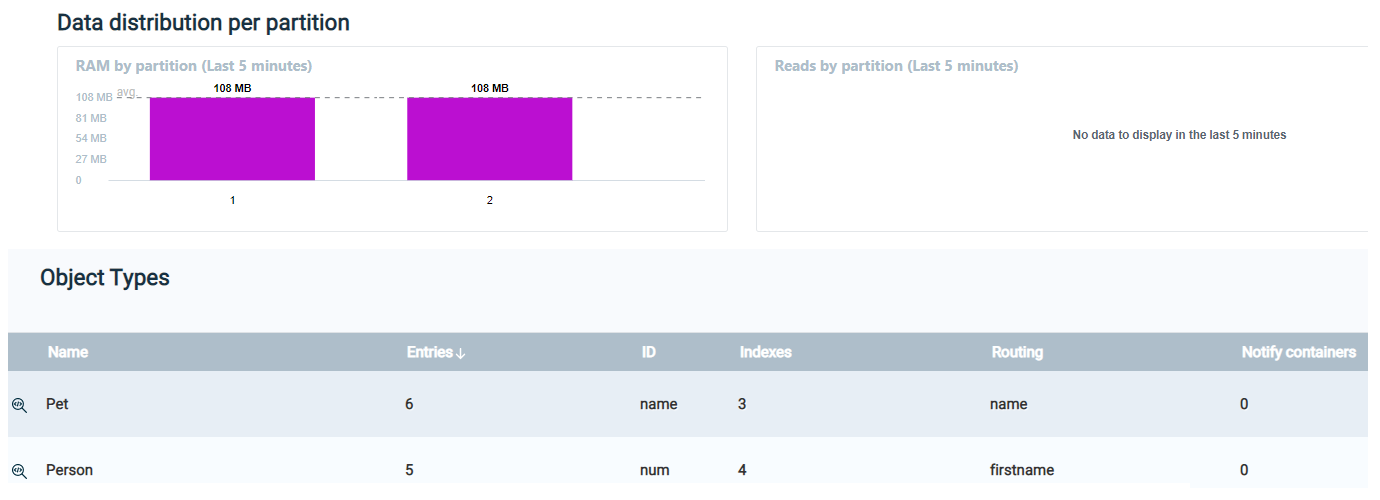
If the Demo Space remains empty and you receive the following message in connector stdout:
INFO: Call put with record count 0
Then proceed as follows:
rm -rf /tmp/connect.offsets (clean the offset file)
This should solve the issue and then you should be able to see the records in the Space and see the following in the sink connectror stdout:
INFO: Call put with record count 11