Persistency
Space![]() Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. persistency in GigaSpaces is comprised of two components, a Space data source and a Space synchronization endpoint. These components provide advanced persistency capabilities for the Space architecture to interact with a persistency layer, and are in charge of the following activities:
Where GigaSpaces data is stored. It is the logical cache that holds data objects in memory and might also hold them in layered in tiering. Data is hosted from multiple SoRs, consolidated as a unified data model. persistency in GigaSpaces is comprised of two components, a Space data source and a Space synchronization endpoint. These components provide advanced persistency capabilities for the Space architecture to interact with a persistency layer, and are in charge of the following activities:
-
The Space data source component handles pre-loading data from the persistency layer and lazy load data from the persistency (available when the Space is running in LRU
 Last Recently Used.
This is a common caching strategy. It defines the policy to evict elements from the cache to make room for new elements when the cache is full, meaning it discards the least recently used items first. mode).
Last Recently Used.
This is a common caching strategy. It defines the policy to evict elements from the cache to make room for new elements when the cache is full, meaning it discards the least recently used items first. mode). -
The Space synchronization endpoint component handles changes made within the Space delegation to the persistency layer.
GigaSpaces's Space persistency provides the SpaceDataSource and SpaceSynchronizationEndpoint classes, which can be extended and then used to load data and store data into an existing data source. Data is loaded from the data source during space initialization (SpaceDataSource), and from then onwards the application works with the Space directly.
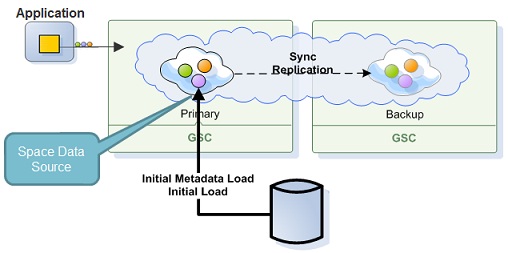
Meanwhile, the Space persists the changes that were made via a SpaceSynchronizationEndpoint implementation.
Persistency can be configured to run in Synchronous or Asynchronous mode:
Synchronous persistency mode is deprecated and will be removed in a future GigaSpaces product release. Use Asynchronous Persistency mode instead.
-
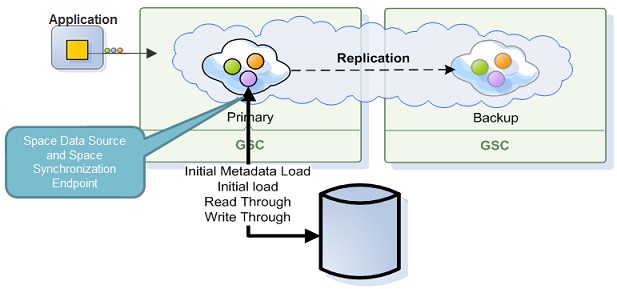
Synchronous Mode - see Direct Persistency
-
Asynchronous Mode - see Asynchronous Persistency with the Mirror
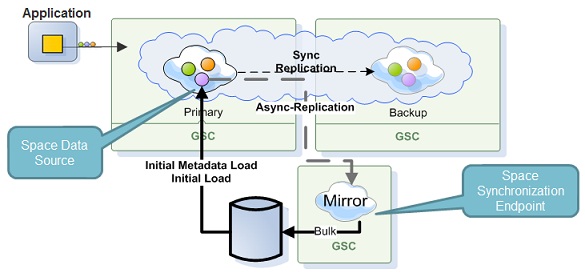
The difference between Synchronous and Asynchronous persistency mode is the way data is persisted back to the database. In Synchronous mode, data is persisted immediately after the operation is conducted where the client application waits for the SpaceDataSource/SpaceSynchronizationEndpoint to confirm the write. In Asynchronous mode (mirror Service), data is persisted in a reliable asynchronous manner using the mirror service as a write-behind activity. This mode provides maximum performance.
Space Persistency API
The Space Persistency API contains two abstract classes that should be extended in order to customize the Space persistency functionality. The ability to customize the Space persistency functionality allows GigaSpaces to interact with any external application or data source.
| Client Call | Space Data Source/ Synchronization Endpoint Call |
Cache Policy Mode | EDS Usage Mode |
|---|---|---|---|
write, change, take, asyncTake, writeMultiple, takeMultiple, clear |
onOperationsBatchSynchronization, afterOperationsBatchSynchronization |
ALL_IN_CACHE, LRU | read-write |
readById
|
getById
|
ALL_IN_CACHE, LRU | read-write,read-only |
readByIds
|
getDataIteratorByIds
|
ALL_IN_CACHE, LRU | read-write,read-only |
read, asyncRead |
getDataIterator
|
LRU | read-write,read-only |
readMultiple, count |
getDataIterator
|
LRU | read-write,read-only |
takeMultiple
|
getDataIterator
|
ALL_IN_CACHE, LRU | read-write |
transaction committed
|
onTransactionSynchronization, afterTransactionSynchronization |
ALL_IN_CACHE, LRU | read-write |
transaction failed
|
onTransactionConsolidationFailure
|
ALL_IN_CACHE, LRU | read-write |
GigaSpaces's built in Hibernate Persistency implementation is an extension of the SpaceDataSource and SpaceSynchronizationEndpoint classes. For detailed API information, refer to Space Data Source API and Space Synchronization Endpoint API.
RDBMS Space Persistency
GigaSpaces comes with a built-in implementation of SpaceDataSource and SpaceSynchronizationEndpoint called Hibernate Space Persistency. See Space Persistency Initial Load to allow the Space to pre-load its data. You can also use splitter data source SpaceDataSourceSplitter, which allows you to split data sources according to entry type.
NoSQL DB Space Persistency
The Cassandra Space Persistency Solution allows applications to push long-term data into the Cassandra database in an asynchronous manner, without affecting the application response time, and to also load data from the Cassandra database after the GigaSpaces data grid is started or in a lazy manner when there is a cache miss when reading data from the GigaSpaces data grid.
The GigaSpaces Cassandra Space Peristency Solution leverages the Cassandra CQL, Cassandra JDBC Driver and the Cassandra Hector Library. Every application's write or take operation against the data grid is delegated into the Mirror![]() Performs the replication of changes to the target table or accumulation of source table changes used to replicate changes to the target table at a later time. If you have implemented bidirectional replication in your environment, mirroring can occur to and from both the source and target tables. service that uses the Cassandra Mirror implementation to push the changes into the Cassandra database.
Performs the replication of changes to the target table or accumulation of source table changes used to replicate changes to the target table at a later time. If you have implemented bidirectional replication in your environment, mirroring can occur to and from both the source and target tables. service that uses the Cassandra Mirror implementation to push the changes into the Cassandra database.