SpaceDeck – Data Pipeline – Create New Pipeline
Data Pipelines allow a convenient, no-code method to pipe data from the System of Record to the GigaSpaces in-memory data grid.
A new data pipeline definition will include the definitions of the System of Record databases, tables and fields that will provide data to the pipeline. The definition also indicates the in-memory Space that will receive the pipeline data.
Additional information includes optional validation rules and automatic conversion of specified field definitions.
Display the Configuration screen
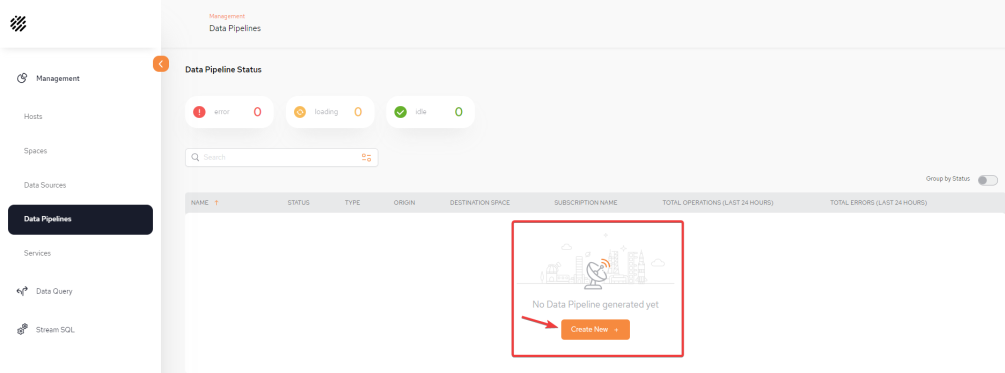
From the Data Pipeline![]() A series of data processing steps, including extraction, transformation, and loading (ETL), that move data from its source to a destination system. Data pipelines are essential for integrating and managing data flows. main screen, click Create New + to begin defining your first pipeline.
A series of data processing steps, including extraction, transformation, and loading (ETL), that move data from its source to a destination system. Data pipelines are essential for integrating and managing data flows. main screen, click Create New + to begin defining your first pipeline.
Pipeline Configuration Screen
STATUS - Possible statuses are: Inactive, Running, Error and Warning.
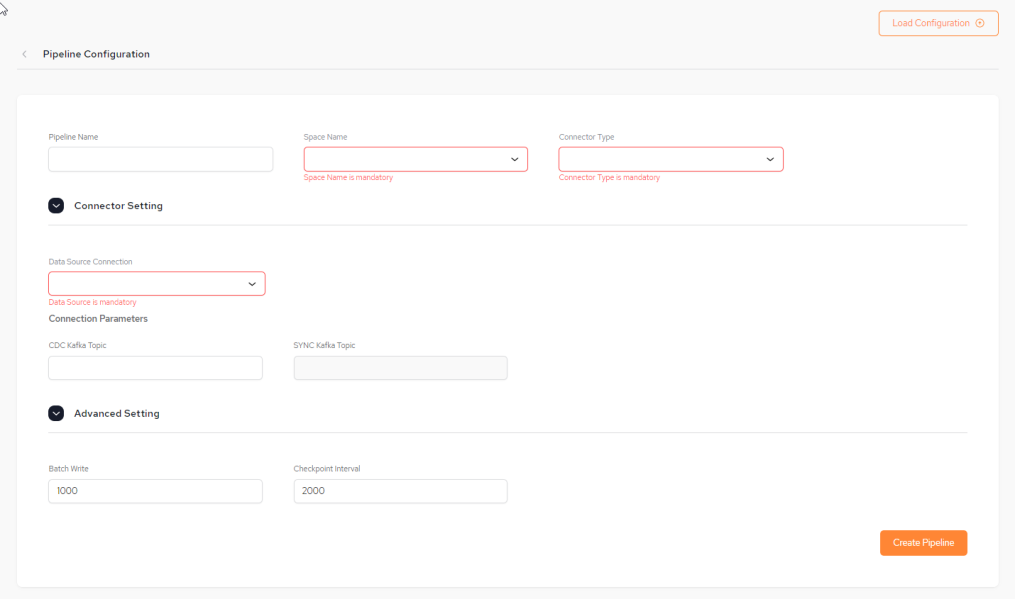
The Pipeline Configuration screen appears as follows:
Basic Pipeline Information
You can fill in some or all of the pipeline configuration items (shown below) from a JSON-format configuration file by clicking the Load Configuration button.
The configuration file may contains some or all of the required details. After the configuration details are loaded from the configuration file, they can be edited if desired, before saving .
-
Pipeline Name – Name assigned to the pipeline.
The Pipeline name is not case sensitive and has no limits for naming
-
Space Name – The name of the GigaSpaces Space object that will receive the pipeline data. This is a mandatory field.
-
Connector Type – The data connector type, for example, IIDR
 IBM Infosphere Data Replication.
This is a solution to efficiently capture and replicate data, and changes made to the data in real-time from various data sources, including mainframes, and streams them to target systems. For example, used to move data from databases to the In-Memory Data Grid. It is used for Continuous Data Capture (CDC) to keep data synchronized across environments.. This is a mandatory field.
IBM Infosphere Data Replication.
This is a solution to efficiently capture and replicate data, and changes made to the data in real-time from various data sources, including mainframes, and streams them to target systems. For example, used to move data from databases to the In-Memory Data Grid. It is used for Continuous Data Capture (CDC) to keep data synchronized across environments.. This is a mandatory field. -
Connector Setting:
-
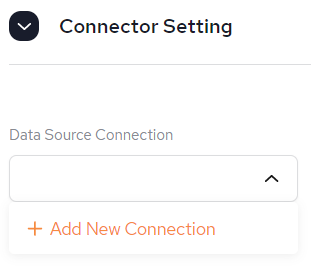
Data Source Connection – The data source from the System of Record. This is a URL and points to a database such as DB2. This is a mandatory field. Information about configuring data sources can be found here: Data Integration (DI).
It is possible to Create a new Data Source connection from here, if one has not already been created via the Data Sources menu. Follow the instructions from SpaceDeck – Data Sources.
-
CDC
Change Data Capture. A technology that identifies and captures changes made to data in a database, enabling real-time data integration and synchronization between systems.
Primarily used for data that is frequently updated, such as user transactions. Kafka Apache Kafka is a distributed event store and stream-processing platform. Apache Kafka is a distributed publish-subscribe messaging system.
A message is any kind of information that is sent from a producer (application that sends the messages) to a consumer (application that receives the messages).
Producers write their messages or data to Kafka topics. These topics are divided into partitions that function like logs.
Each message is written to a partition and has a unique offset, or identifier. Consumers can specify a particular offset point where they can begin to read messages. Topic – The name of the Kafka topic for CDC changes. -
SYNC Kafka Topic – The name of the Kafka topic for initial load changes.
-
-
Advanced Setting:
-
Batch Write – Size of the single batch write from a DI layer to the space. The value specified here is the number of commands.
-
Checkpoint Interval – Interval, in milliseconds, that the data integration layer performs a commit to Kafka and flush to Space.
-
Click Create Pipeline to create the new data pipeline.
Select Tables for the Pipeline
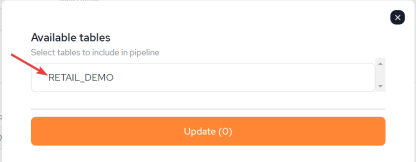
Once the pipeline has been created, click Add / Remove tables to select which tables to include in the pipeline.
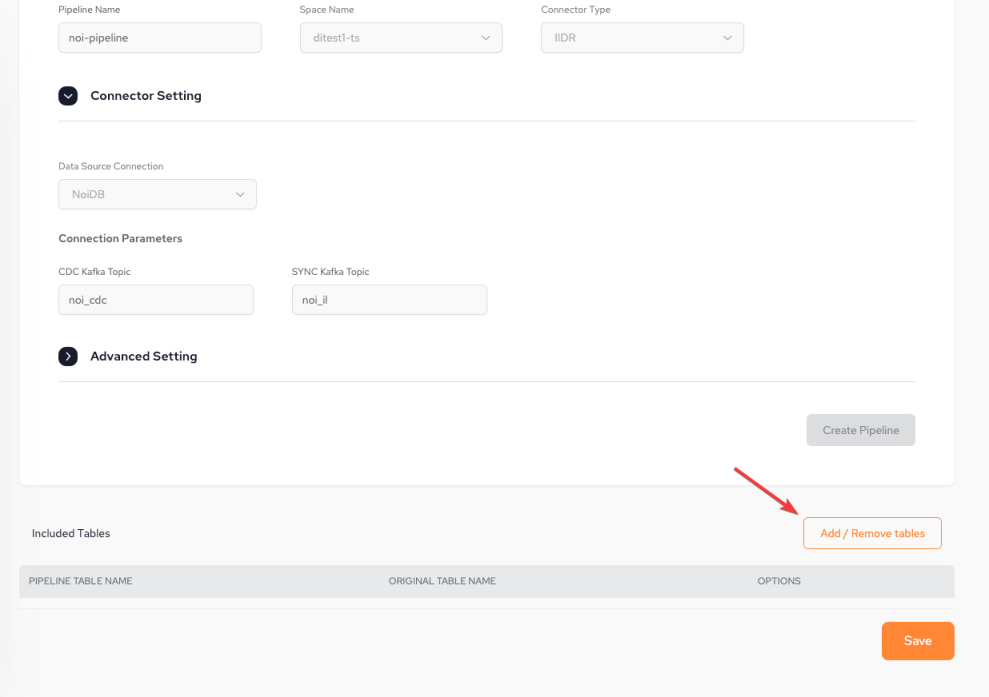
A list of available tables will be presented. Select the table to be added, and click Add to add the selected tables to the pipeline.
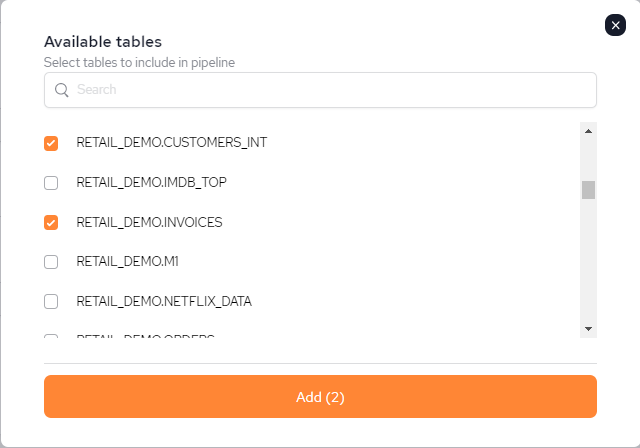
Once Add is clicked, it will take a few seconds to update.
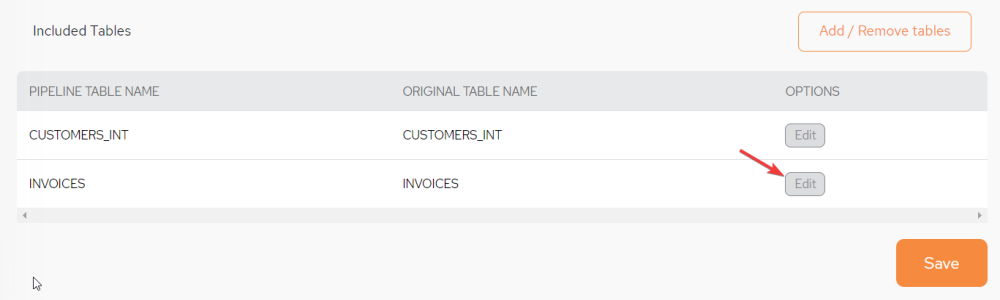
Edit the Tables
Editing the table can only be performed during the initial setup and configuration process. The pipeline has to be deleted and configured from new in order to perform this action again.
From the Included Tables area of the screen, click Edit
Navigating the Configuration screen - Parameters Tab
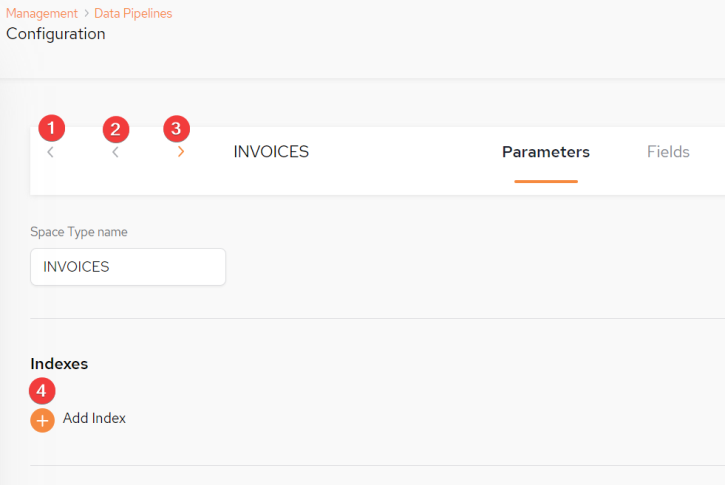
1: Return to Data Pipelines screen
2: Go to previous Space Type entry
3. Go to next Space Type entry
4. Add Indexes
It is possible to change the name of the Space Type to be different to that of the table name.
Indexes, Space ID and Routing ID
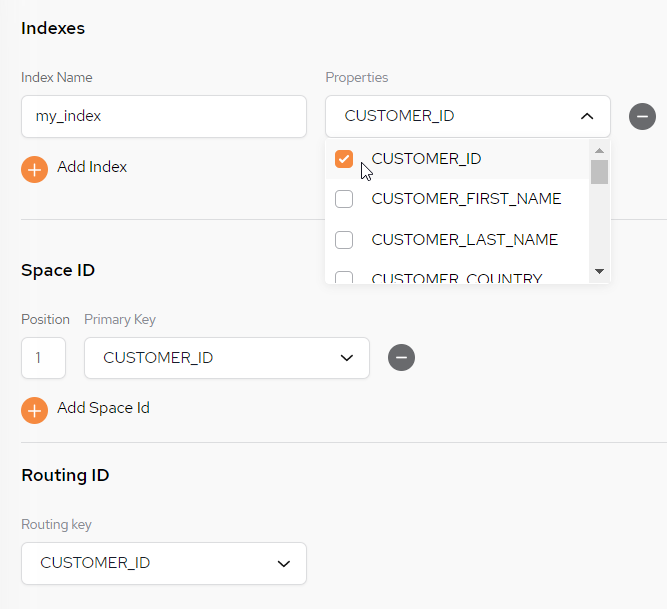
The Indexes area contains the following fields and options:
-
Index Name – Supply an index name
-
Properties – Select the columns to be part of this index
The Space ID area contains the following fields and options:
-
Position – In the case of a compound key (multiple keys in the same key), the position of every field in a key needs to be identified (first column, second column, etc.). For a single column, it should always be 1 (default).
-
Primary Key - Serves as a unique identifier in a table (space type)
The Routing![]() The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. ID area contains the following fields and options:
The mechanism that is in charge of routing the objects into and out of the corresponding partitions. The routing is based on a designated attribute inside the objects that are written to the Space, called the Routing Index. ID area contains the following fields and options:
-
Routing ID – Select a column in order to change the routing key.
Tiered storage will be part of a future release.
Navigating the Configuration screen - Fields Tab
In the Fields tab of this screen, the Field (column) names are initially the names of the fields from the database table that are included in the data pipeline. These can be edited to provide different property names (column names) in the GigaSpaces object type (table), or to include or exclude it.
Other fields in this screen will be editable in a future release.
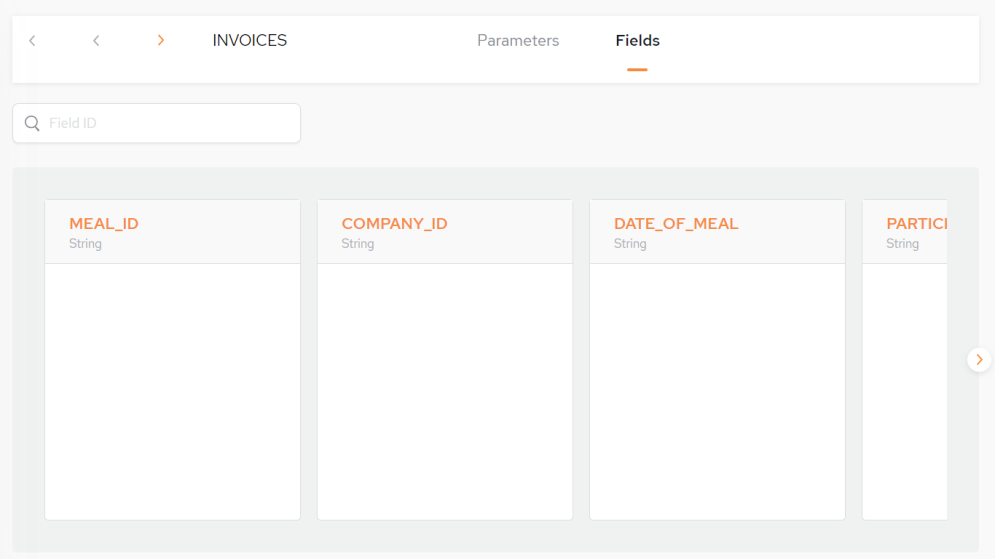
The Fields tab contains the following fields and options:
-
Field ID – Search for a field by field id
-
Field (column) names – Initially, the names of the fields from the database table, that are included in the data pipeline. These can be edited to provide different property names (column names) in the GigaSpaces object type (table).
In this example, the fields are named MEAL_ID, COMPANY_ID, etc.
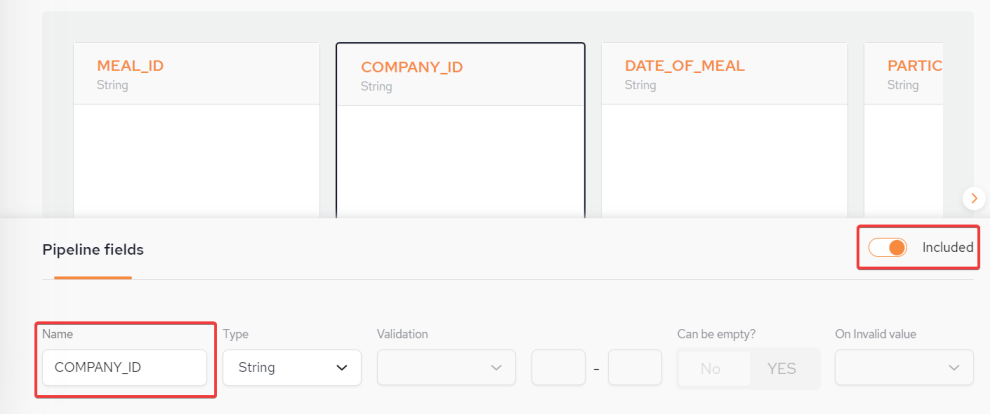
If you click one of the field names, the Pipeline Fields section appears, which allows you to edit the field characteristics:
-
Name – Name of the field
-
Included Toggle - Can include or exclude the a field of the table from the space type.
Once the setup has been completed, return to the main Data Pipelines screen and select save.
Remove the table and then add it again to be able to edit it again
Start the Pipeline
Once the pipeline has been defined, it can be started from two different menus.
-
From the Configuration menu, accessed by selecting the pipeline name from the main menu:
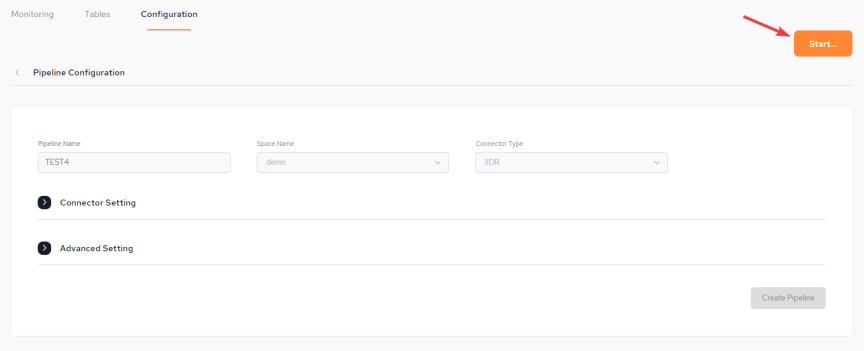
-
From the main screen by clicking Start Pipeline from the kebab menu (vertical three-dot menu) on the far right.
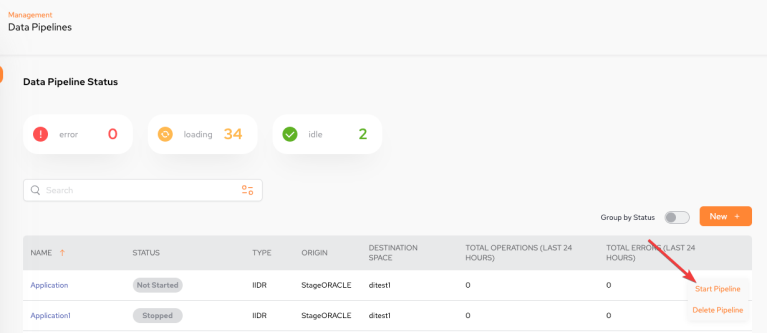
Then a Parameters to apply pop-up is displayed:
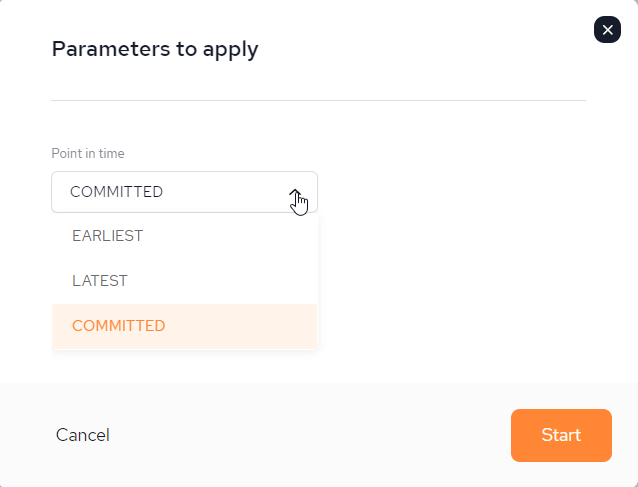
Point in time options:
-
EARLIEST - Start a pipeline from the beginning, means whatever is available for consumption in our queue , start processing from the beginning.
-
LATEST - Start a pipeline from now , start consuming and processing data from a current message regardless last stored checkpoint.
-
COMMITTED - Start a pipeline from the last successful processed message (kind of a checkpoint).
Once the pipeline has been started, it cannot be edited. To make changes it is necessary to delete the pipeline (from the main data Pipeline screen) and build it again.
After you have added the tables and saved the pipeline, save the changes and press Start to start the pipeline.
The pipeline will show as Started in the Data Pipeline Status screen and Active in the Spaces screen.
Deleting a Pipeline
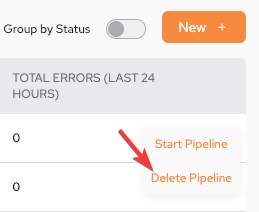
From the main screen by clicking Delete Pipeline from the kebab menu (vertical three-dot menu) on the far right.
If you decide to delete a pipeline the following confirmation pop-up screen will be displayed before the action can be completed:
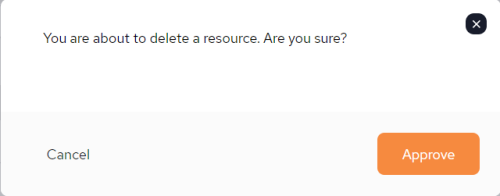
Once Approve has been clicked, the pipeline is deleted immediately and cannot be restored.