Data Persistency in Tiered Storage
Tiered Storage stores data in a permanent repository. The data can be saved when the tiered storage is undeployed, and restored when it is redeployed.
Why Use Data Persistency?
The initial loading of data into each tier can be a time-consuming process, starting with the System of Record or other external data sources. Additionally, data in both tiers can be updated during the normal course of operations during the day.
During the normal use of Tiered Storage, priority data is stored in the Hot tier, and other data is stored in the Warm tier:
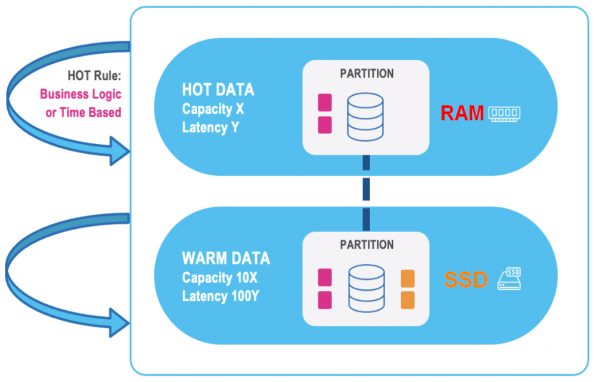
For an explanation of Tiered Storage and instructions for configuration, see What is Tiered Storage?
Using data persistency, data in both tiers is stored in a system repository. When the data is undeployed, the user has an option to persist the data. Subsequent redeployment of the data is performed at optimum speed.
The undeployed services can be viewed using the GET /pus/undeployed REST API.
An example of sample output is shown below.
[
{
"name": "tiered-space",
"unDeployedAt": "2021-08-03T14:14:22.787",
"isPersistent": true,
"gracefulShutdown": true,
"lastPrimaries": [
{
"partitionId": 1,
"instanceId": "1_1"
}
],
"spaceInstancesHosts": [
{
"instanceId": "1_0",
"host": "127.0.1.1"
},
{
"instanceId": "1_1",
"host": "127.0.1.1"
}
],
"schema": "partitioned",
"numOfInstances": 1,
"backupsPerPartition": 1
}
]
The number of backups per partition is zero or one.
The data of undeployed services can be deleted using the DELETE /pus/undeployed/{id} REST API.

