Kubernetes Overview
Kubernetes is an open-source orchestration system for automating the deployment, scaling and management of containerized applications. It can be used as an alternative to the GigaSpaces service grid for deploying and orchestrating GigaSpaces and the GigaSpaces data grid in a cloud-native environment.
Kubernetes works in synergy with GigaSpaces, which simplifies the operationalizing of machine learning and transactional processing at scale. GigaSpaces leverages Kubernetes features such as cloud-native orchestration automation with self-healing, cooperative multi-tenancy, RBAC authorization, and auto-scaling. Auto-deployment of data services, the Apache Spark deep learning and machine learning framework, and Apache Zeppelin (providing visualization and interactive analytics), seamlessly support GigaSpaces-based applications.
GigaSpaces uses Kubernetes' anti-affinity rules to ensure that primary and backup instances are always on separate Kubernetes nodes. This high-availability design, combined with self-healing, load-balancing and fast-load mechanisms, provides zero downtime and no data loss. Additionally, rolling upgrades can be automated and implemented pod by pod using Kubernetes' Stateful Sets. This allows for a smooth upgrade process with no downtime.
Architecture
KubeGrid, GigaSpace’s Kubernetes-based deployment option, utilizes the key features of the Kubernetes platform mentioned above to set up and run the data grid. KubeGrid can also auto-deploy data services and frameworks, such as Spark Drivers and Spark Executors, to enable Spark machine learning and Spark SQL.
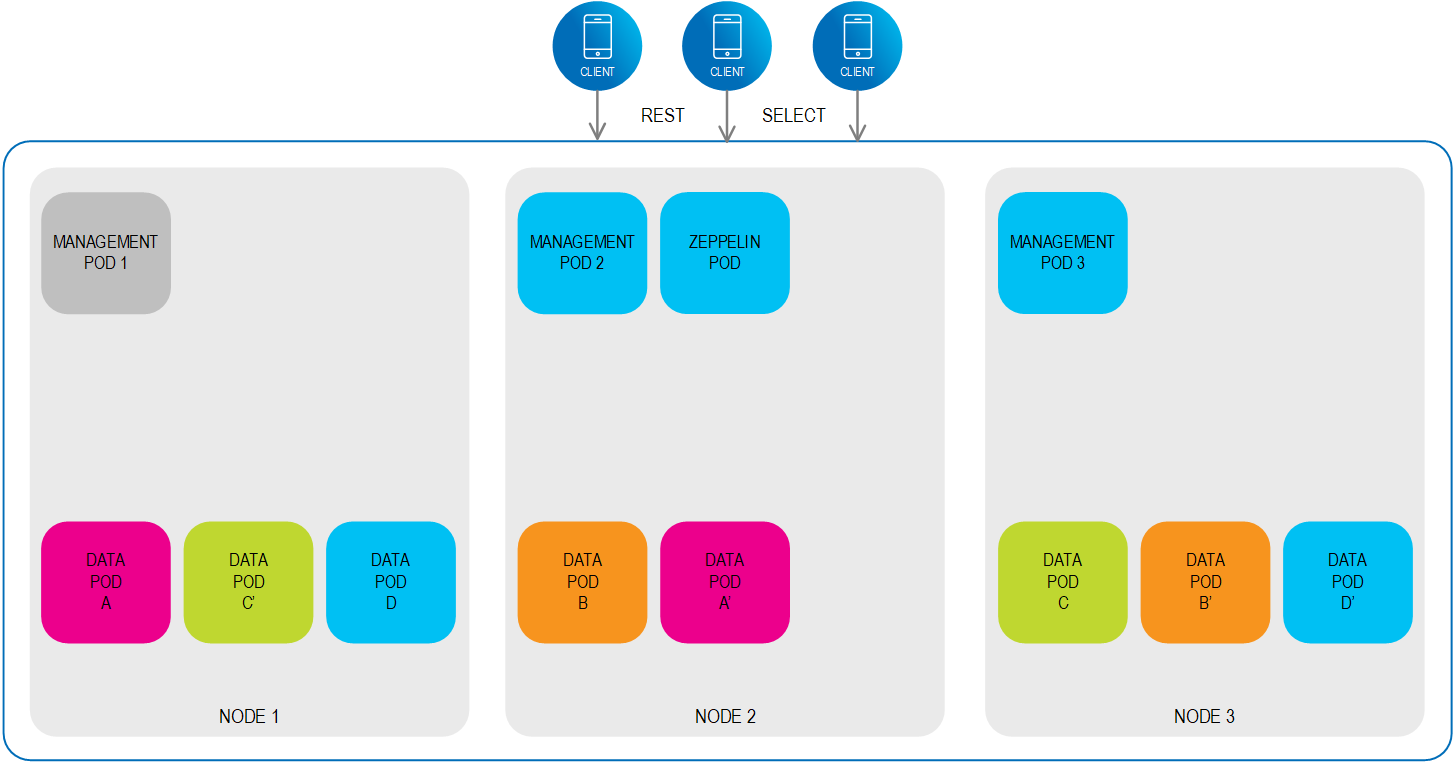
KubeGrid deploys several components that comprise the data grid.
The Management Pod contains the data grid’s management components. A minimum of one Management Pod is deployed in a regular environment, while three are deployed in a high availability environment.
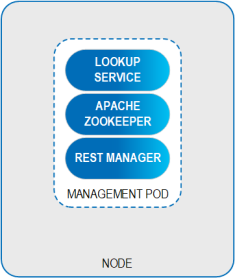
The Management Pod contains the the following:
- Lookup Service (LUS) – A mechanism for services to discover each other. For example, the LUS can be queried for the location of active Data Pods.
- REST Manager - A RESTful API that is used to manage the data grid and GigaSpaces environment remotely, from any platform.
- Apache Zookeeper - A centralized service that determines Space leader election.
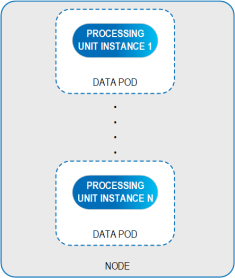
The Management Pod manages the Data Pods, which are the fundamental unit of deployment in the data grid. Each Data Pod contains a single Processing Unit instance that provides cloud-native support using built-in Kubernetes controllers, such as auto scaling and self healing.
Functionality
KubeGrid enforces SLA-driven capabilities that leverage the Kubernetes controllers and schedulers.This enables defining the following for environment stability:
- Requirements for controlling the provisioning process of available Pods.
- Hosts, zones and nodes. The SLA requirements are based on machine-level statistics, and grouping the Pod processes in zones.
- Deterministic deployment by explicitly defining the primary and backup instances.
Additional benefits include:
- High Availability in conjunction with the Kubernetes Pod anti-affinity rule, which ensures that primary and backup Pods will be allocated on - different nodes.
- Ability to scale the system up or down, and apply rolling updates with zero downtime using StatefulSets (persistent identifiers per Pod).
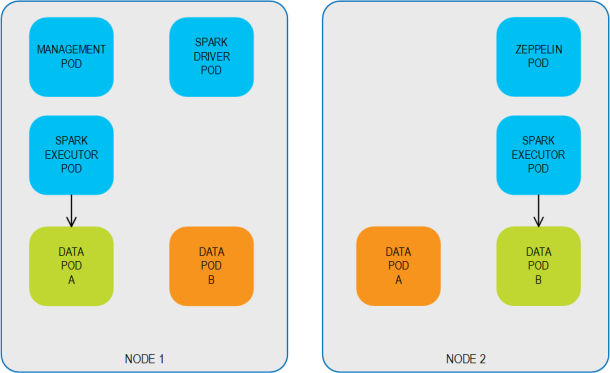
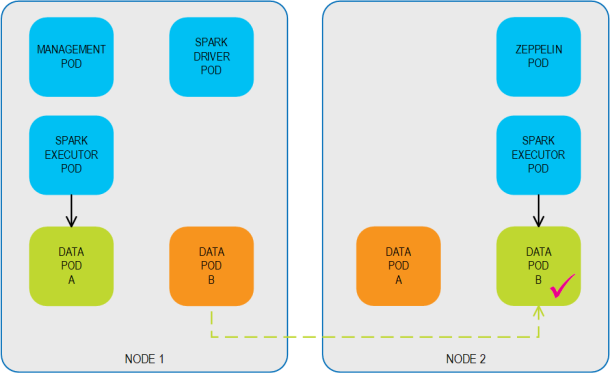
Automatic Pod Failover
KubeGrid supports automatic Pod failover behavior. The following example describes the failover behavior for a 2,1 primary/backup topology. When Pod anti-affinity is defined, the Pods are distributed over multiple nodes so that each primary/backup pair is hosted on different nodes.
If the primary Data Pod B is disrupted for some reason (either voluntary for scenarios such as rolling upgrades, or involuntary for reasons such as loss of connectivity), the system fails over to the backup Data Pod B, ensuring business continuity. Backup Data Pod B switches roles, and becomes a primary Data Pod.
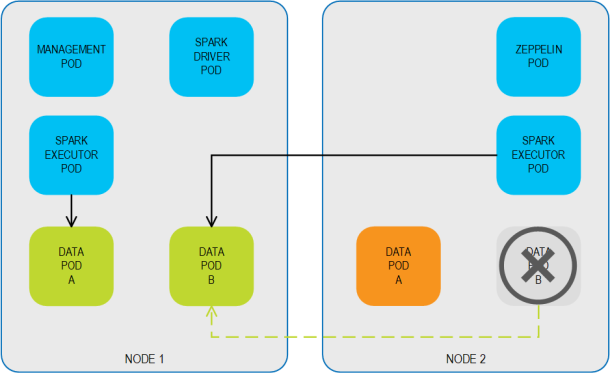
When the original primary Data Pod B is back up and available, the system can fail back to the restored Data Pod B, which resumes its role as a primary Data Pod.
Running Spark on KubeGrid for GigaSpaces Applications
Kubernetes has native support for Apache Spark. When you submit a Spark application, the following occurs:
- A Spark driver is created that runs within a Driver Pod.
- The Spark driver creates Spark executors that run within Executor Pods
- The Spark driver connects to the Spark Executors and executes the application code.
- When the application completes, the Executor Pods terminate and are cleaned up.
- The Driver Pod stays in “completed state”, persisting the logs until it is manually cleaned up or garbage collection is performed at some point.
The scheduling of the Driver Pod and the Executor Pods is handled by Kubernetes.
In completed state, the Driver Pod doesn’t consume any computational or memory resources.
When the Spark application runs, the Driver Pod and Executor Pods are created according to the schedule that was configured.
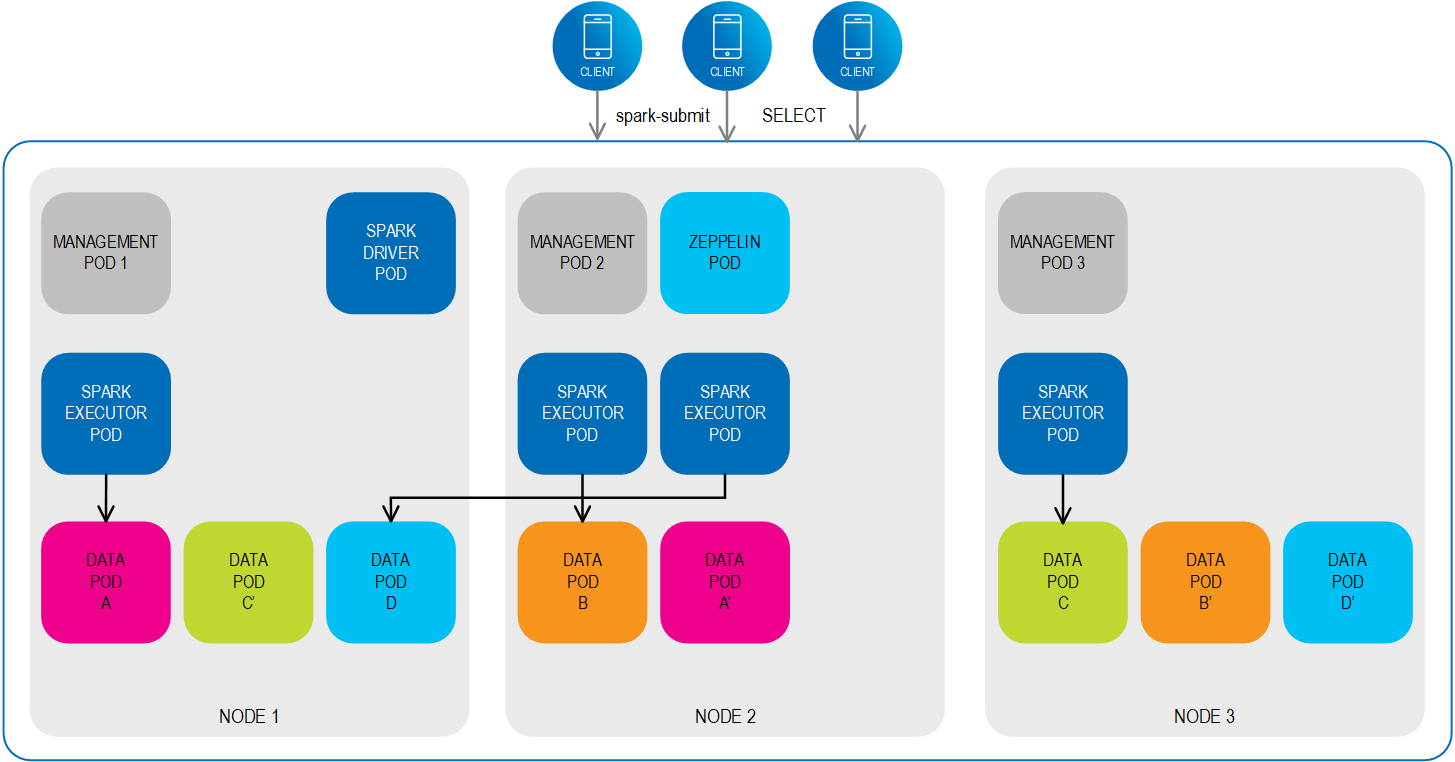
The Executor Pods can access the required data objects from any of the Data Pods in the cluster, regardless of which node they reside on. When the Spark jobs are complete, the Executor Pods are cleaned up and the platform is ready for the next submit.
Additional Resources
|
|
|
One-click deployment with Kubernetes |

