Using a Jupyter Notebook
In addition to native support for Apache Zeppelin, which is used primarily by Java and Scala developers, InsightEdge supports integration with the open-source Jupyter web notebook. Programmers can perform data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and more on objects in the InsightEdge data grid using PySpark.
This topic describes how to integrate the Jupyter Notebook with GigaSpaces.
Prerequisites
The Jupyter notebook should be installed and included in your system PATH variable.
If you don't have Jupyter installed, refer to the Jupyter documentation for installation instructions.
Incorporating the Jupyter Web Notebook
You need to incorporate the Jupyter web notebook in the GigaSpaces environment in order to access PySpark using the Jupyter dashboard.
To integrate Jupyter in GigaSpaces:
-
Add the following entries to
$GS_HOME/insightedge/bin/insightedge-pyspark:export PYSPARK_DRIVER_PYTHON=jupyter export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
-
Add the following entries to
$GS_HOME\insightedge\bin\insightedge-pyspark:set PYSPARK_DRIVER_PYTHON=jupyter set PYSPARK_DRIVER_PYTHON_OPTS='notebook'
Running PySpark from the Jupyter Dashboard
After you've installed Jupyter and incorporated it within GigaSpaces, you can use the web notebook to access the data in the GigaSpaces data grid and perform the required operations using PySpark.
To run PySpark from the Jupyter dashboard:
-
Run the following command:
$GS_HOME\insightedge\bin\insightedge-pysparkThe Jupyter dashboard launches in a browser window that opens at localhost:8888.
- From the dashboard, view or run existing notebooks or click New and select a notebook from the list to create a new notebook.
-
Load data from the InsightEdge data grid as shown in the example on the PySpark page, and use the DataFrames API to manipulate the data as necessary.
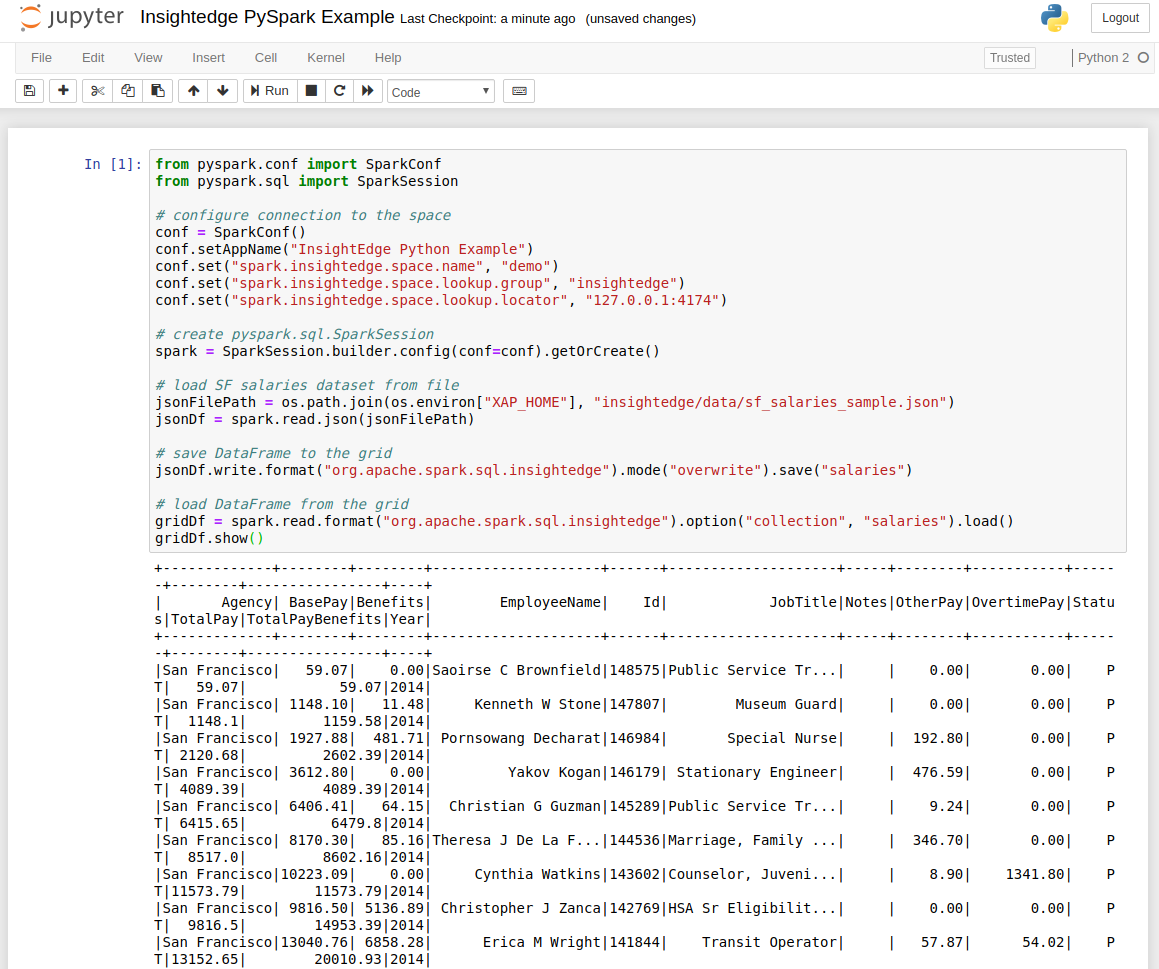
You can run this sample that loads data from a file and saves it to the demo dataspace.
from pyspark.conf import SparkConf from pyspark.sql import SparkSession # configure connection to the space conf = SparkConf() conf.setAppName("InsightEdge Python Example") conf.set("spark.insightedge.space.name", "demo") conf.set("spark.insightedge.space.lookup.group", "insightedge") conf.set("spark.insightedge.space.lookup.locator", "127.0.0.1:4174") # create pyspark.sql.SparkSession spark = SparkSession.builder.config(conf=conf).getOrCreate() # load SF salaries dataset from file jsonFilePath = os.path.join(os.environ["XAP_HOME"], "insightedge/data/sf_salaries_sample.json") jsonDf = spark.read.json(jsonFilePath) # save DataFrame to the grid jsonDf.write.format("org.apache.spark.sql.insightedge").mode("overwrite").save("salaries") # load DataFrame from the grid gridDf = spark.read.format("org.apache.spark.sql.insightedge").option("collection", "salaries").load() gridDf.show()And see the PySpark commands and output within the Jupyter dashboard.